Angular是最早声称基于MVVM架构的前端框架,但在我眼里,Angular根本没有M这一层,React和Vue也好不到哪里,目前最热的三大框架,都只是V层前端框架,和M层谈不上什么联系。
不过,在此前我自己写过的一篇爽文《前端状态管理设计——优雅与妥协的艺术》里,我自己还曾经提到,Vue的组件管理有模型管理的影子,如今回忆起来,实属草率。不过还好,我并没有在文章中给前端状态管理和模型管理之间的关系下一个定论,避免打脸。但是在我的播客节目《Robust:程序员的Talk Place》的第15期《跳出框架看前端分层结构》中,我却明确提出了前端分层结构,妥妥的在一些问题上给自己挖了坑。
不是我冒犯,包括我自己在内,如果满眼都是React和Vue之类的前端框架、库,那么可以说,对前端数据层几乎一无所知,就算把前端框架玩的贼溜,对前端架构的理解,也不过是井底蛙之王。
前端热门框架只是视图框架
本文将主要讨论的是业务型前端应用中的数据层。业务型前端应用,主要处理的是基于某个业务流程而实现的产品形态,它和游戏、大数据展示、同声传译、音视频处理等前端应用非常不同,它关注业务流程在用户眼中的呈现,常常以业务流程的准确实现为目标,例如饿了么点餐、腾讯云服务管理平台、淘宝电商平台等,这些都是典型的业务系统,也是当下整个互联网行业最主流的产品形态。因此,React、Vue和Angular火,决定因素还是时代背景,即业务型应用的大势所趋。
从技术层面讲,三大框架(甚至包括Flutter)虽部分理念不同,但从底层视图绘制去思考,它们都是基于结构性视图绘制的实现逻辑。无论是基于DOM树形结构的框架,还是React Native,它们都有一个共同实现特征,就是需要“布局”,而且是“结构性布局”(比如基于类XML语言的布局)。本质上它们是Retained Mode GUI,而非Immediate Mode GUI。结构性布局框架,在Canvas、VR 3D环境中就会遇到麻烦,因为在这类视觉环境下遵循“坐标定位布局”,三大框架在这种场景中基本就没有发挥余地。在DOM环境下,处理动画、复杂交互(例如拖拽排序这个简单的功能),三大框架也不如jQuery顺利,因此,如今的前端框架,仅仅是在业务系统领域中,具备竞争力,脱离业务系统,它们的发挥空间和所带来的收益,就会瞬间下降,如果脱离“结构性布局”,它们的收益几乎为负数(React也在尝试实现canvas和vr渲染,其实很令人期待)。
虽然火力都在业务系统领域,但是对于对业务数据逻辑有极强要求的应用,却在前端层面,至今为止,没有统一的认识。前端数据层的缺少,是很多业务系统越来越难以维护的重要原因。
React是纯视图库,Vue和Angular并不比React内涵或外延多多少,三者本质上没有区别,甚至react在视图抽象上可以复用到其他平台,做canvas或vr的尝试,而angular几乎无法做这些尝试。在架构层面,它们声称遵循MVVM架构,特别是Angular认为自己拥有完整的框架结构。
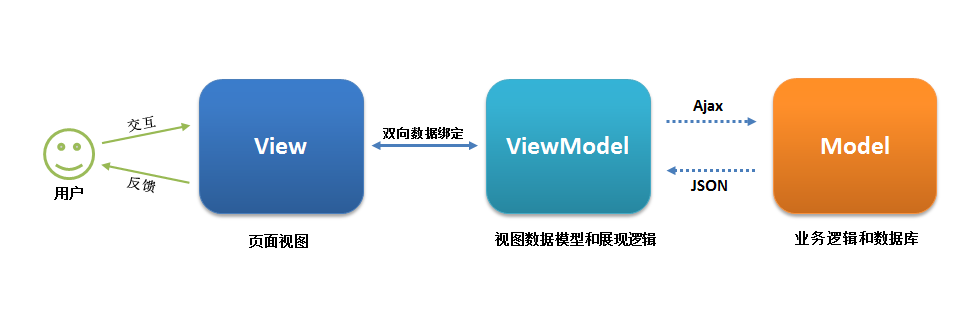
MVVM架构示意图,来自网络
在上图示意中,VM通过ajax和Model交互,这显然是一种奇葩解释。事实上,号称拥有完整架构的Angular确实是没有自己的Model层,它只有VM层的实现,并且规定了V层和VM层如何编程,但在M层毫无建树,而且所谓的VM层也是为V层服务。这也印证了主流框架本质上是V层框架的观点。
为了强行往完整的MVVM或MVC靠,很多人将基于Redux或其他类似全局状态管理器的应用结构称为真正符合完整MVC的架构。但这个说法实际上有点胡扯,全局状态管理是V层框架的衍生品,是属于解决问题过程中衍生出来的新问题,React和Vue都是基于状态驱动的V层视图框架,全局状态管理器本质是在解决这类(基于virtual dom的)视图框架的状态管理优化问题,根本和MVC中的M没有什么关系,也就更别说和模型设计有什么关联,自然也享受不到模型设计的好处。
而且冒昧的说,基于React这种组件结构性布局的视图层框架,如果无法解决全局状态管理器的隔离性,那都是在浪费时间和资源。什么是这里的“隔离”呢?简单说就是一个页面可能有两个React应用(本质是一个大组件),而每个应用有一个自己的全局状态。(不过比较幸运,Redux可以做到这一点。)为什么这么说?我们可以回顾一下,在没有数据(这里单纯理解为后端数据)参与的React应用中,编程是非常简单顺利的,因为React视图完全是靠状态驱动的。然而,当引入一个数据源之后,整个编程复杂度将会瞬间提升几倍,而且,越是使用Redux这类全局状态管理器,复杂度越高,甚至比不上单纯在组件中直接ajax请求数据来的简单。这是为什么?很多人根本没有思考过这个问题。
我曾经有一种想法是,既然React是单纯的UI库,那么我能否自己建立一套MVC的框架,其中V层由React来承担,M层我自己实现一套逻辑?这种想法是好的,而且实践起来也有可能实现。然而在真正实现过程中,我发现整个编程已经被React的编程范式框定住了,虽然React声称是纯UI库,但是它实际上规定了开发者写组件的方法,因为对于组件而言,状态是完全要自治的,一棵组件树最终表现成什么样子,它只能被内部的状态或外部的props控制,要真正实现MVC,就必须由全局状态管理器作为中间人,和M层打交道才能实现(如下图),这导致整个编程会非常复杂,一旦按照这种逻辑去实现,那带来的成本,比当前热门的只需要一个全局状态管理器的编程方式更复杂,完全没有必要。(不过,由于hooks的出现,这种局面可能会被打破。)
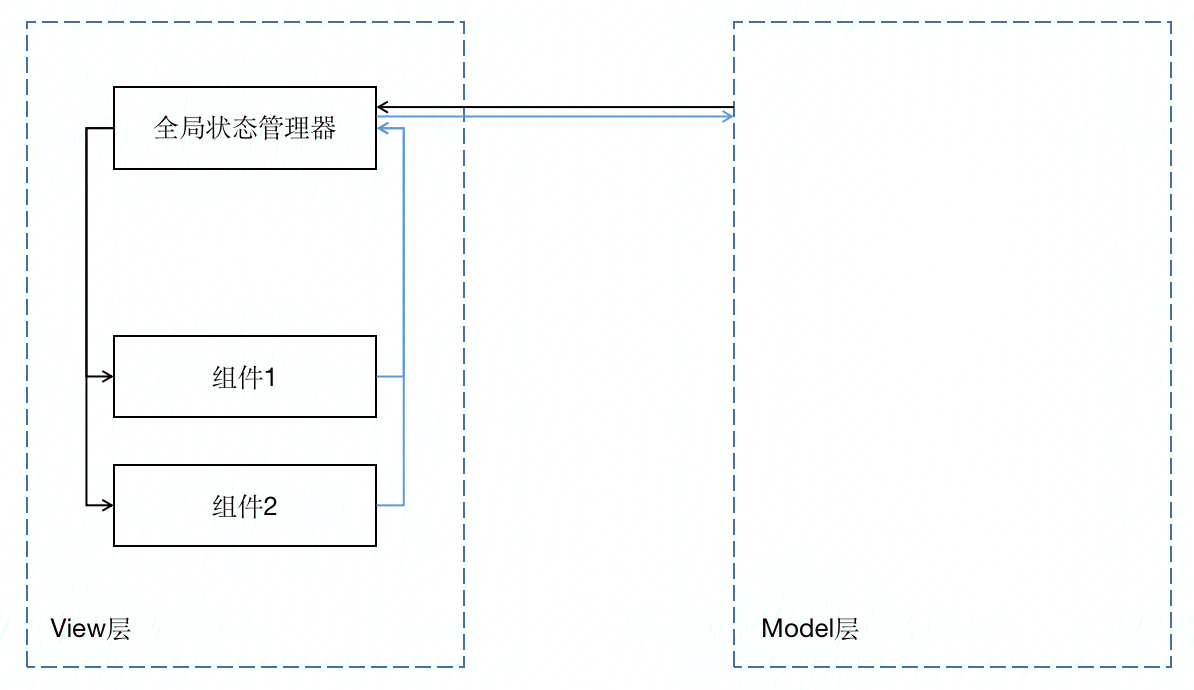
在原有的React编程范式上叠加Model层编程示意图
所以,无论是三大框架本身,还是全局状态管理器,都是V层编程,都没有真正解决前端数据层问题。而基于这套编程范式的框架,要再去实现M层,又会增加更加复杂的问题。除了三大框架之外的一些非V层前端框架,却在业务系统领域的理念上,可能更优秀。以Cycle.js框架为例,它本身虽然也是落足到UI上,但是它在数据到状态到UI的过程中,增加了“流”的逻辑,也就是说,它是两端可扩展的,基于这个扩展,数据管理的能力实现起来也更容易一些。而已经快被大家遗忘的Backbone框架,干脆在UI层没有强制,虽然也是基于jQuery的,但是它不限制开发者的视图层实现逻辑,它更关心Model如何触发View的重绘。从这些角度看,这些非主流的边缘框架,反而在前端框架架构层面走的更远,起码它们不是单纯V层框架。
前端分层结构
业务型应用和纯工具应用不同,前端业务系统不是无源之水,不可能凭空产生数据,如果脱离业务数据,它将变得毫无用处,一文不值。在浏览器里面运行起来之后,前端程序会申请内存,产生一些运行时数据,这些数据本质上是驱动V层渲染的状态,而非来自M层的数据。前端数据的来源有很多,最主要的包括:从后台api请求得到的,通过websocket等方式接收到的,通过postMessage等方式接收到的,从localStorage等前端持久化存储读取的,读取文件内容解析后得到的……这些数据来源组成了前端应用数据层的基础、源头。前端数据层,即围绕这些数据源,和数据源上游打交道,并且连接它的下游——视图层——的特定处理逻辑。

其中,和我们业务相关的,最核心的数据来自于API接口吐出的数据。不过理论上,这一层数据属于VO(View Object),它并不最贴近业务本身,而是后端为了提供符合前端需要的数据,经过层层处理,最终输出的数据。

图片来自网络
也就是说,对于单纯从界面出发的前端应用而言,其实并不需要涉及业务本身。可是非常不巧,业务流程越复杂的应用,在前端对业务的依赖更强。举个例子,一个流程管理系统,不同角色对某一个操作的效果不同,而且不同角色操作之后,会进入到各自的子流程中。由于这种逻辑是前置的,用户在操作之后,需要立即在界面上得到反馈,而不能等到拉取后端数据来渲染。直白的讲,这类业务逻辑只能写在前端,才能满足业务交互的需求。所以,在另外的一些系统中原本应该由后端完成的数据业务处理,此时,可能需要在前端完成。于是上图中的数据流,其中BO到VO部分,可能都需要前端参与。而这些,就是前端数据层需要考虑解决的问题。
正如前文提到过,数据层生产数据,视图层消费数据。
与此同时,前端还有一个非常棘手的问题,就是人机交互。在所有有关数据的流程模式的讨论中,很少有人能够将人机交互所带来的数据问题解释清楚。这也是为什么我在《Robust》第15期提出了“事件流”这一层的原因(也给自己挖了一个坑)。现在,我要提出的问题是:用户操作视图所产生的数据,例如键盘输入,鼠标拖动输入,是属于数据源,还是属于运行时数据?
数据源是固定的(相对而言),而运行时数据是动态的。人机交互中,用户产生的运行时数据,理论上是固定的,因为人输入的内容在那一时刻确定了,不会有变化。但是,实际生产中,这类数据生命周期太短了,它们几乎一瞬间就转化为视图状态数据,反映到界面上,成为视图的一部分,然后它们本身就消失了。因此,从这个点上,我虽然认可用户输入的信息是数据源,但真正在我们使用时,却是以运行时数据(视图状态)在使用。因此,这类人机交互产生的数据不属于前端数据层管辖范围(不是由数据层生产),但却可能要发送到服务端,成为新的数据源。那么,在真正的数据层和视图层之间,似乎是少了什么东西,用以在视图层和数据层之间有一个缓冲,以解决这类状态数据反向流回数据源的问题。而这一层,我称之为“逻辑层”(并非我所发明,网上早有人这样称呼)。

逻辑层的主要作用是调度,将数据层的结果实例化为运行时数据,这些运行时数据将被作为视图状态,用于渲染到界面中。同时,它接收人机交互信号,调度状态变化,协调视图层各个部分做出响应。于此同时,它还可能将状态数据转化为实体数据,通过调用数据层通道,将数据发送回源头,并获取新数据,以再次完成向视图层输送数据原料的任务。所以,数据层处理原始数据,逻辑层生产运行时数据,视图层消费运行时数据。

而逻辑层接收视图层信号的方式,在前端领域非常独特,它通过事件绑定,监听用户对界面的操作,从事件中提取信息,并将事件信息经过一通演变之后,转化为新的数据。在这方面rxjs这个库做的惟妙惟肖,它可以通过流式管道的形式,将事件信息,转化为状态数据,并将该数据反馈给状态管理器。由于现代前端编程深受“状态驱动视图”思想的影响,所以,一旦状态接收到新的变化后,会立即反馈到界面上。所以我反复提到,状态管理器,是用于控制界面的工具,属于视图层编程。

一旦理解了这一点,我们就会发现,如今大红大紫的前端框架领域,更多的是以界面出发,围绕视图层编程,解决一系列人机交互问题。而在数据层,也就是最贴近我们真实业务的层面,却几乎毫无建树。这也是为什么我们虽然已经有了强大的框架,却往往还是不断写出结构复杂,条理混乱,不易维护,升级艰难的前端项目。框架只是在技术层面帮助我们确定编程范式,却无法为我们解决真实业务的逻辑梳理。
我们纵观围绕业务系统而开发的前端框架,数据层、逻辑层、视图层作为前端最基本的分层结构呼之欲出。其中,视图层非常清晰,因为我们已经经历了太多视图层框架。逻辑层相对比较混乱,不过如果非得要找到对应的,我们姑且认为angular中的controller编程属于逻辑层编程。而数据层,则在少数企业内部有自己的实践,目前业界还没有统一的定论。
前端数据层
从上文的描述中可以看出,我们所指的数据层是指处理、管理静态数据资源的编程层,而非动态的运行时编程层。数据层的编程,形象的说,我们是在进行“壳”的编程,这个“壳”本质目标是为运行时数据塑形,使得运行时数据自身内部拥有某种约束性,以供逻辑层、视图层使用时,符合业务的实际。数据层本身也是分层的,它主要有服务层和模型层组成。
服务层
关于前端Service层的讨论并不少,一般认为,前端和后端的数据交互层被称为Service层,也就是通过ajax拉取和发送数据到后端API接口的这一层。不过我认为这种理解过于简单,它所蕴含的内在意义没有被讲透,无法让读者深刻理解从数据源获取的数据与应用本身之间的关系。
在这里,我将引入“数据仓库”设计中的分层相关知识来阐述前端数据服务层。
前文提到,前端数据不是无源之水,前端数据的来源有很多,其中最重要的形式包含API接口、WebSocket通知、localStorage本地持久化存储。我们设计一种“数据仓库”,它要完成如下的任务:
- 隔离前端应用与数据源,对于前端应用而言,不需要关心和数据源的交互问题,它把数据来源问题委托(代理)给数据仓库,它只从数据仓库读取数据,或提交数据,它只和数据仓库交互,而不和真正的数据源直接交互,甚至它不需要关心数据背后真正的数据源,不需要关心有没有数据源,这一层被数据仓库接管了,对于应用而言,数据源是黑盒。
- 数据仓库不仅要向应用提供数据,同时还要反应数据变化,也就是通知应用数据已经发生变化,应用应该做出相应的变化(如重新渲染),这里我们可以使用观察者模式完成。
- 数据仓库自己本身要解决数据的本地化,也就是根据前端应用的需求,完成数据的缓存、本地持久化等,比如某些应用的数据,要求刷新页面后,之前的数据还在,而不是需要从服务端再次拉取全部数据。
- 数据仓库自己要有和服务端实时交互的能力,无论是通过websocket还是其他方式,完成前端应用数据提交时,组建请求队列,和服务端交互。如果是提交数据,还要在服务端数据更新之后,主动拉取回新数据,并通知前端应用这一变化。
总而言之,数据仓库的存在,隔离了前端应用和服务端,对于前端应用而言,服务端应该是不可见的,它只会和数据仓库交互,读取和写入数据。
虽然数据仓库分层的方法不同,但是大体上,数据仓库设计主要可以分为如下几层。

虽然不同文献中对数据仓库分层阐述不同,但我总结认为,主要如上图5层。
- Source:数据源层,本质上它不属于数据仓库本身,而是数据仓库的上游,数据仓库的数据从这里来。
- ODS (Operational Data Store):操作数据存储层,即将数据原子化存储,是静态的,固定的,不是运行时的,对于前端而言,ODS可以落实到indexedDB中管理数据,当然也可以直接放在内存中,刷新页面再重新从服务端读取,但是,在js运行中,不应该对ODS中的数据进行任何修改,它应该是静止的,除非来自服务端的新数据替换了原始老数据。
- DW (Data Warehouse):数据仓库层,这里的数据仓库主要指代码层面,如何对ODS进行组织和管理,它更多的是负责对数据仓库中的数据进行变化、转化、修饰,并管理好存储在ODS中的数据,起到存储器的管理程序的作用。DW层本身可以有多个层组成:
- DWD (Data Warehouse Detail):明细层,距离ODS最近,是对ODS的详细描述和补充
- DWB (Data Warehouse Basis):基础层,也叫轻度汇总层,主要完成数据的统计、清洗等工作
- DWS (Data Warehouse Service):汇总层,距离DM层最近,为DM层准备数据
- DIM:字典层,为数据仓库提供字典配置,例如黑白名单等
- DM (Data Market):数据集市层,对数据进行包装,向下一层提供符合具体使用场景所需要的结构的数据。
- APP:应用层,也就是真正使用数据的一层,本质上也不属于数据仓库的部分,而是数据仓库的使用者,也就是我们的前端应用本身。
在后端设计数据仓库时,需要对每一层都创建数据库以保持每一层的数据,但是在前端,为了节省,我们可以只在ODS存储数据,其他层都是基于已有数据进行现算。而且对于前端应用而言,DW和DM是可以合并的,我们不需要将职能划分的如此清楚,总体而言,我们只需要一个DS(Data Service)层,用以从ODS中读取原始数据,然后格式化为具体业务逻辑中需要的格式化数据。
此外,我们发现,从Service到Source这个中间,其实要处理很多事情,其中需要包含数据的拉取、发送、同步,以及数据的存储,这些事都要完成。除此之外,还要完成两个可选的事:从数据源拉取的数据,可能需要经过格式化之后,再存储在本地;发送的数据,可能需要经过一定转化后才向服务端同步。我在几年前就开始实现一个叫 databaxe 的库,这个库在实现之初我并没有接触数据仓库的知识,凭借自己的直觉完成它的设计和开发,后来发现,它在很多方面符合数据仓库的设计理念。

上图阐述了正常数据从数据源,到应用的整个过程,中间环节就是数据仓库完成的事。其中,“同步”这个操作比较特殊,由于前端应用需要通过http等方式从服务端拉取数据,一旦服务端数据发生变化,例如当前这个用户现在在PC上进行操作,但是中间有一个环节,他去手机APP上处理了,这个时候,他再看PC,我们应该将他在APP上的操作同步到PC中,而这个工作,可以通过websocket完成同步。
另外,在上图中没有特别注明的是前端特有的事件驱动,当websocket下发用户在手机端的操作信息后,如何将新的数据反馈到界面上呢?在数据仓库设计时,需要APP层通过观察者模式,对数据仓库中数据的变化进行订阅,当数据仓库同步数据变化之后,调用APP层传入的subscribe函数,从而触发APP层的重新渲染。
模型层
Service层为我们解决了数据源的抽象,但是感觉前端应用整体层面仍然少了什么,因为对于我们而言Service层是可选的,其设计复杂程度也是可选的,应用可以不要Service,或者Service仅仅是一个ajax接口请求的封装,而不需要上述所讲的从ODS到DM的设计,这也是可行的,而且也是当下大部分前端应用实践的。然而,我们究竟少了什么?
我们少了一层模型层。
M和VM的区别
以Angular、Vue为典型代表的框架声称自己是MVVM框架,那么这里的M和VM的区别究竟在哪儿呢?从字面上看ViewModel看上去好像本身就是一种Model,但实质上完全不一样。我们用代码来说明。
const Person = Vue.extend({
template: `
<div>
<span>{{name}}</span>
<span>{{age}}</span>
</div>
`,
data() {
return {
name: 'some',
age: 10,
}
},
methods: {
getName() {
return this.name
},
setAge(age) {
this.age = age
},
},
})
这是用Vue定义的一个ViewModel,它本质上是在创建一个视图模型,它确实和模型一脉相承,但是,它的核心在于围绕template描述视图,模型上规定的属性、方法,全部在视图中使用。
class Good {
type = ''
price = 0
storage_count = 0
up(count) {
this.storage_count += count
}
down(count) {
this.storage_count -= count
}
}
这是一个描述商品的简易模型,它描述了作为一个商品,应该具备什么属性,可以进行什么操作。和Person的最大区别在于,Good模型只描述自身,而Person却描述它要用template生成的界面。ViewModel是自洽的,它定义的属性、方法,大部分情况下会在template中直接使用,阅读ViewModel的描述是可以对视图逻辑有完整闭环的印象的。但是Model是开放的,Model上定义好的属性、方法,你根本不知道它会在哪里被调用,是在什么情境下,按什么顺序被调用。所以,ViewModel看上去是Model,但本质上又不是Model。
在前端系统中,界面必不可少,所以ViewModel有其价值,特别是以“状态驱动视图”的思想盛行后,View和ViewModel的组合可以实现极高的编程效率,对视图的抽象也变得非常优秀。然而,如果单纯这样,就可以声称自己是完整的框架,那么,我很遗憾的说:这不过只是完整的VVM框架,前面的M被干掉了。而且,对于框架本身而言,基于ViewModel的驱动确实不错,却不是唯一的选择,React本身是不基于VM的,或者说React并不强调是基于VM的,而是说自己是基于State的。这很好理解,因为在React中,你不需要事先定义一个ViewModel就可以完成界面编程,这也是为什么React称自己是纯UI库,而不像Vue称自己为框架。
从前文我关于前端分层结构的描述来看,我更倾向于把拥有完整MVP(而非MVVM)的框架称为完整的前端框架。其中V层业界已经很成熟了,而P层勉强可以通过我们自己的各种骚操作结合框架特征完成,唯独M层,业界没有统一认识。
前端需要模型吗?
如果VVM框架已经可以帮我们解决问题了,那么我们确实不需要模型层。然而,很多前端开发者和我一样,经历过刚开始用Vue的时候大喊爽,但当业务需求稍微多一些,复杂一些,就会跪下来拜求不要摩擦。这是为什么呢?
因为我们将复杂的业务逻辑写在ViewModel中,我们错误的认为ViewModel可以承载视图模型和业务模型。可是实际上,别说承载业务,单纯一个页面拥有极其复杂的交互的时候,VM管理自己的视图交互逻辑都顾犹不及,怎么可能还能包揽业务的逻辑呢?
那么,一旦有一天,当你可以明确区分,某个操作应该属于业务层面,某个操作应该属于交互层面,而且,这些操作混在一起带来管理麻烦的时候,你就可以准备创建自己的前端数据模型了。对于我个人而言,由于经历的几套大系统都是业务层面的,所以很容易区分业务系统和功能型应用。只要一开始就发现这是一个业务开发,我就会不自觉的提炼出业务实体,将业务逻辑收拢在模型中。
DDD领域驱动设计
讨论数据模型,绝对离不开DDD这个话题。并非凑热度,而是因为DDD为我们提供了方法论,帮助我们快速理解如何去设计领域模型,有了这些方法论,我们可以提前避免掉一些坑,不需要自己摸索太多。不过遗憾的是,DDD只为我们提供了思维层面的方法论,却在实际编程领域没有太多可直接使用的内容,开发者习得DDD思想之后,还需要依靠自己对业务本身的理解,以及自身在行业中的经验来构建自己的领域模型和业务系统。
虽然在具体意义上有差别,但是我们可以将领域模型和我们所指的前端数据模型划等号,都是对业务实体的抽象描述。DDD给我们的最大启发在于,我们不单单要关心数据,而且要关心业务。开发层面,DDD给我们提出了三个核心对象:
- 实体:用于描述业务的对象
- 事件:用于描述状态变化信息的对象
- 服务:用于执行无状态更新的函数集合
其中,实体(Entity)是领域模型的核心,一个Entity是对单个业务进行描述的完整信息集合。这里“完整”是指该业务中将拥有那些状态,以及将会发生什么事情。简单讲,Entity包含了业务对象的能力,本质上就是描述这个业务都拥有哪些特征,以及内部的约束逻辑。
在前端语境下,领域模型在代码层面,就是一个class类(当然,这是从java的面向对象过来的)。而这个Model类需要包含对实体的描述,需要实现事件系统,必要的时候需要实现服务(用静态属性即可)。我们来看一个例子:
class Good {
type = ''
price = 0
#events = []
increasePrice(num) {
this.price += num
this.#events.forEach((item) => {
const { type, fn } = item
if (type === 'priceIncreased') {
fn()
}
})
}
onPriceIncreased(fn) {
this.#events.push({
type: 'priceIncreased',
fn,
})
}
static create(data) {
const { type, price } = data
const instance = new this()
instance.type = type
instance.price = price
return instance
}
}
这是一个针对Good的纯业务模型,不涉及任何和界面相关的信息。它包含了实体信息type, price, increasePrice,也包含了事件系统#event,还包含了用于创建Good实例的服务create。在VM中,它可能被使用:
const good = Good.create({
type: 'ball',
price: 12.5,
})
good可能被用于界面上某处的渲染vm.good = good,此时的good和Good已经脱离了模型,成为运行时的状态,可以作为状态在视图中使用了。
某些情况下,一个模型的实例可能包含另外一个模型的实例,此时,模型之间就产生了依赖关系。例如
class Shop {
goods = []
addGood(data, count) {
for (let i = count; i --;) {
const good = Good.create(data)
this.goods.push(good)
}
}
}
这是一个商铺模型,一个商铺中可能包含一堆商品,通过addGood方法向商铺中添加商品,该店铺有哪些商品都被放在goods属性中。但是这里有一个问题,如果我们要从商铺下架一个商品怎么办?能不能直接在Good中加一个下架的方法呀,这样我不需要调用Shop的方法,而是可以直接对Good实例进行操作?虽然实践层面这是可行的,但是我们不允许这么设计。Clean Architecture 提供了一种有关数据分层的设计,我所在意的是,它提供了依赖指向性理论,外层实体依赖内层实体,因此,对于内层的实体,不需要知道外层实体对它的需求。如果在设计时,内层实体还要考虑外层如何使用它,那么这是“不干净”的架构。对于领域模型而言,它所要描述的是自身所拥有的特征和能力,描述时,不需要,也不应该考虑外部环境,它被谁使用,如何使用,对于它本身而言并不需要关系。领域模型是对业务对象的纯粹描述,和业务运行过程中的环境无关。
流程模型
实体模型往往是对某个具体的事物进行抽象描述,但是业务系统中另一个更复杂的对象就是流程。比如办公系统中的审批流,比如电商系统中的订单流程,这些流程不指具体的某个事物,而是一系列实体、行为和逻辑的总和。
实际上,流程的本质,是业务时间内实体的进出和实体状态的变化的总和。实体的进出是指,在流程这个“业务池”中,不同阶段,新的实体进来,老的实体出去,例如订单流程中,配送阶段,配送员这个实体进来,完成配送之后,配送员这个实体出去。而用户付款,则会修改订单的状态。业务池对付款实体状态变化抛出的事件进行监听,得到事件信息之后,再做一轮其他状态变化或实体进出。事件是保证业务流程形成链状,持续更迭的关键。
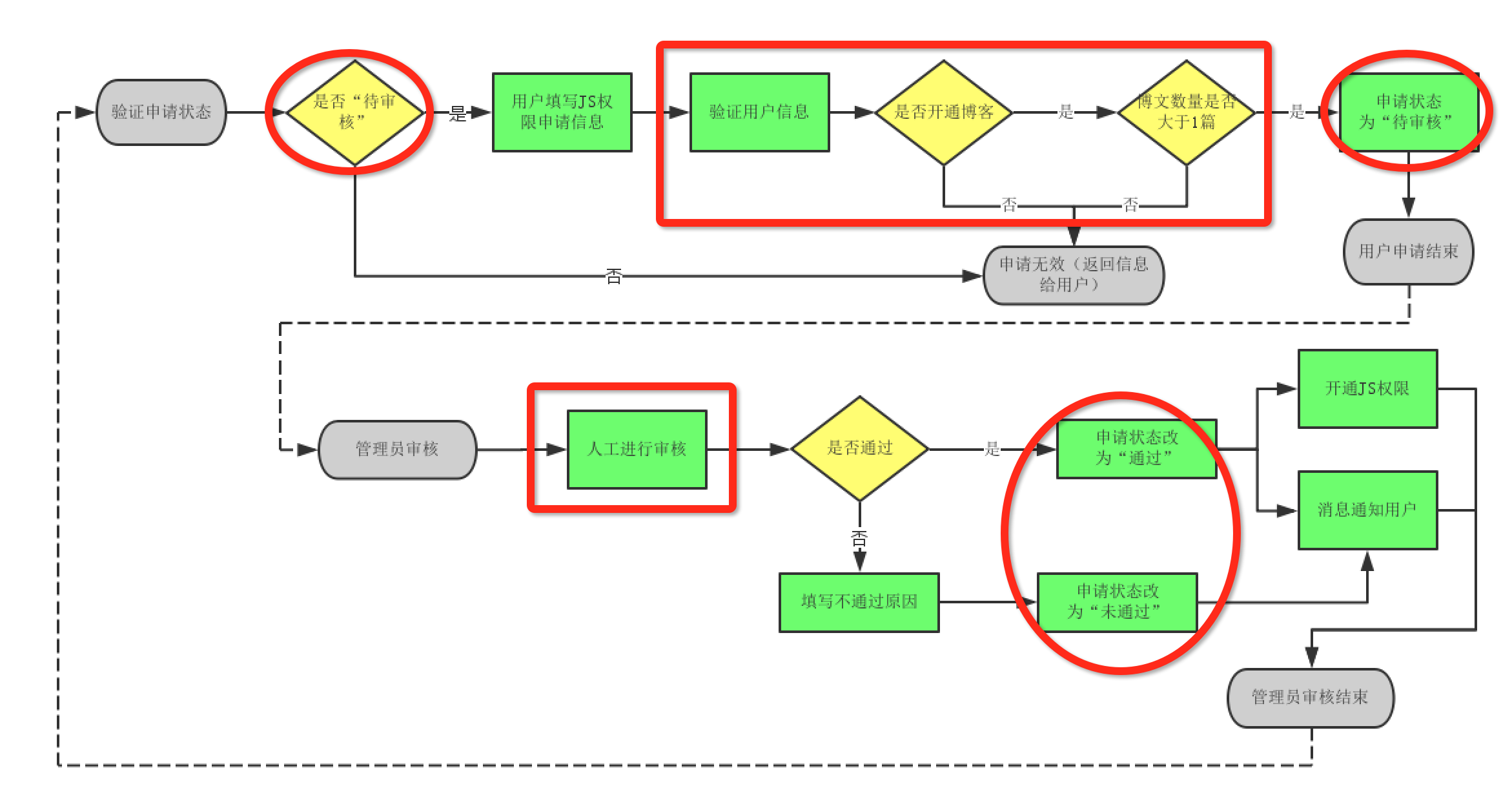
一个描述用户申请开通博客的流程,来自网络
方框圈的是核心业务,圆形圈的是实体的状态变化,核心业务一般包含在最简单的描述中,业务流程一般是不会发生变化的,变化的是核心业务。流程本身,实际上是由命令式代码根据复杂的条件判断完成的一系列指令。这些指令中,部分包含了对业务实体的操作,一般而言是通过调用流程中业务实体模型实例的方法完成的。模型本身只描述了自身的能力,但是这些能力在流程中如何被使用,使用时先后顺序是什么,都是由流程模型所决定的。在我已有的经验中,根本还没有实践过流程模型,我大部分业务逻辑中,都是杂糅在框架编程中,也就是angular的controller,或vue的组件method中。虽然我没有自己实践过,但是很明显,如果我们拥有一个流程模型,那么就像领域模型一样,将大大提升我们对业务本身的理解。而且,上文一直没有提到的一个点是,界面测试是比较麻烦的,但是模型的测试却相对来说比较容易,如果我们能抽象出流程模型,那么针对流程的测试撰写,将成为可能。
模型元
不过,在前端语境下,纯粹静态的领域模型有的时候会带来一些问题。我们在描述一个实体的时候,我们往往发现,模型中我们需要加入一些辅助信息才能完成前端编程的需要,而这些辅助信息不是业务核心的信息,不过理论上讲,也确实是和业务实体相关的信息。应对这种辅助信息,如果你加上,又会让模型含有杂质,但是不加,又在实际编码时会遇上麻烦,这是一块烫手山芋。不过我的想法是,凡事必有特殊,我们遵循DDD,并不意味着DDD必须原模原样的在前端实现。DDD的最佳实践都是针对后端的,后端开发存在的特征,前端可能不存在,前端的特征,后端也可能不存在,因此,以DDD为设计思想,同时针对前端特殊性做出一些调整,也是应该的。
我花费了很长一段实践撰写前端模型库 tyshemo,它的主要目标,是为前端提供创建读写过程具有强约束的模型的能力。在 tyshemo 的实践中,你需要定义模型上的字段,而对字段的定义,我称之为Meta。
import { Meta } from 'tyshemo'
class Name extends Meta {
static default = ''
static type = String
static required = true
static as = 'name'
}
我通过一段简短的代码定义了一个名字为Name的Meta,它将在模型中作为一个字段的定义。比如,我的一个模型中有一个字段name,它将被Name所定义:
import { Model } from 'tyshemo'
class Person extends Model {
static name = Name
}
一般而言,一堆Meta只为一个Model服务,很少有跨模型共用Meta的情况。不过也有例外,由于我们的应用可能存在于PC和APP两端,而在一些具体逻辑上,同一个字段可能又存在不同逻辑,所以,我们可能同样是定义Person模型,但为了满足不同端的逻辑需求,我们会定义两个Person模型,在不同端使用自己对应的那一个。本质上,这两个Person模型是代表同一个业务实体,但是却因为前端的特殊性,它们在具体字段上会有不同。
// for PC
class Person extends Model {
static name = Name
static weight = WeightOfPc
}
// for Mobile
class Person extends Model {
static name = Name
static weight = WeightOfMobile
}
上面这两个模型,我们就共用了同一个Name Meta,但是在weight字段上,我们用了不同的Meta。不过从业务上讲,虽然两个weight的Meta不同,但是对于Person而言,它是相同的,在设计该模型时,应该保持相同的API接口,以保证在不同端,它的用法是一致的。只是说,在运行时,weight字段会存在少许的不同,不过理论上,这种不同也应该是提前设计好的,后端应该根据这种不同制定不同的策略。
运行时数据层
首先明确,这里所指的运行时数据层,已经和前文所指的“前端数据层”不是一个概念了。运行时数据,在前端语义下,大多是指状态数据,是程序运行所占用的内存(Memory)数据,在逻辑层和视图层进行消费的数据。前端数据层分为Service层和Model层,它们是分离的,Model层可以内置Service层的某些能力,但不是强制的,其实大部分情况下,这两个层的融合要靠逻辑层来完成。逻辑层从Service中取出数据,作为初始信息传入模型进行实例化,得到模型实例,交给视图层使用。逻辑层是将抽象的静态的数据层进行实例化,得到运行时数据的主要场所。

上图中用红色标注的部分,就是我们前端数据的转化过程。从API拿到的原始数据,经过Service层汇总处理暂存在前端,形成持久化数据,这些数据是相对静态的不能被修改的,除非在明确得知服务端数据发生变化的情况下,它会被替换为最新的数据。而真正要交给应用层使用时,Service层需要通过DM层完成从持久化数据中读出的过程,而在读出之后,它作为数据本身并没有意义,而是会和模型进行一次结合,实例化模型时,将这些数据作为模型的初始化数据传入,从而得到一个特定状态的模型实例,此时的模型实例,本质上,是一个内存中的js对象,因此是一个运行时数据。JS运行时数据的一大问题,是无法作为DTO(Data Transfer Object)在网络上传输,它无法被直接发送到后端,保存到服务器数据库。能够作为DTO的,只能是纯对象或文本/buffer形式,而这个“纯”会导致模型状态丢失,也就丢失了运行时特征。因此,其中一个环节也很重要,就是Model基类应该具备通过纯数据还原有状态模型实例的能力,这样,我们就可以通过DTO复原当前业务实体(包含状态的模型实例)。
将Service和Model融合在一起的,往往并非数据层本身,而是逻辑层。前文提到,数据层是“壳”的编程,因此,数据层本身并没有状态,只有逻辑层和视图层才有状态。而视图层功能相对单一,即完成界面渲染。因此,逻辑层承担着将数据层的抽象业务转化为运行时数据状态的重要功能。可以说,逻辑层是数据层的末端,但好像又是整个数据层最终能够产生价值的起点。
小结
本文详细阐述了我关于前端数据层相关的研究和思考。业务系统前端,可以按照“视图层、逻辑层、数据层”进行结构分层。其中数据层在当下的前端领域被讨论的不多,但在我看来却非常重要。数据层本身也可以分为服务层和模型层,数据从源头(API接口)到数据层,到逻辑层,到视图层,然后在回流回来,形成一个完整的闭环。
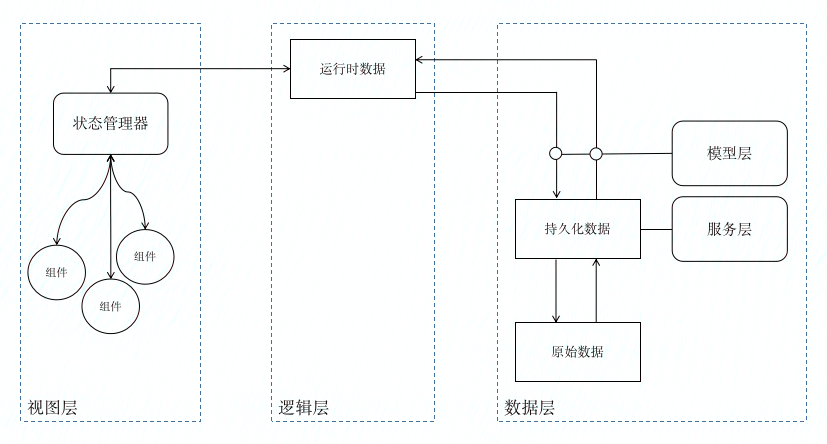
前端数据流总体示意图
上图囊括了本文所提出的整个前端数据层世界观,前端的数据管理是一个很大的工程,本文主要着眼于在当下热门框架缺失数据层,却在业务系统中大行其道的现实,反复强调数据层的重要性。但这不代表我不重视状态管理器,以及业务逻辑流程管理等方面的专研。另外,本文只在我的个人博客、个人微信公众号、知乎专栏“前端数据治理之道”发表,若经授权转载,会在博客本文下作好链接,否则,全是侵权转载。
我们不能一概而论的说前端所有应用都应该遵循这种设计,文章一开始就着重强调过,我们只在业务型前端应用中才会面临是否需要在数据层研究更深的问题。业务型,特别是具有流程的业务型系统,我们不仅要关注数据,而且更要关注真实业务本身,从根本上理解业务实体、规则、逻辑,甚至开发者自己切身去体验一下真实数据环境下业务人员在使用系统时的感受,才能在前端数据层面重新认识系统。我不能保证按照本文所述的方法去设计,就一定能写出明晰,不需要重构,逻辑正确,代码易读的项目,这是我不能保证的。但是,我认为,如果在设计系统之前,如果有过本文所述的所有思考,或许对你的前端代码的设计和管理会有帮助。<完>
2020-07-27 8884


