多年前我在用MySQL数据库时,始终没理解innodb是什么意思,也就糊弄自己说,那个东西就是一种存储数据的格式,多年后我自己在写一个桌面应用时,想创建一个用来存储数据的实体时,接触了sqlite,而后再接触了leveldb,之所以要接触这类东西,是因为我想要让自己的应用不需要依赖用户机器上已经启动的其他数据库服务,而是把数据库本身随着应用部署到用户电脑上。而随着我对leveldb了解后,我逐渐意识到,它就是和innodb一个层面的东西,被称为“存储引擎”。
从文件到引擎到最终的数据库,我们怎么才能做一个自己的类似MySQL一样的数据库呢?本文我将讲解利用我们市面上已有的工具,用nodejs整合出一个自己的数据库。
数据库系统的架构
对于我们习惯了应用开发的开发者而言,很少去考虑数据库的整体架构到底是怎样的。如果我们不理解数据库系统的整体架构,就没有办法做出一个符合自己需求的数据库。
我们常见的数据库有关系型数据库和NoSQL数据库,此外还有其他类型的数据库,如时序数据库、大数据数据库等等。这些数据库各有各的不同,但是在概念层面,总存在共通的架构。
经过总结,我认为数据库系统的架构大致如下,不一定全面,但是可以帮助我们理解数据库架构。
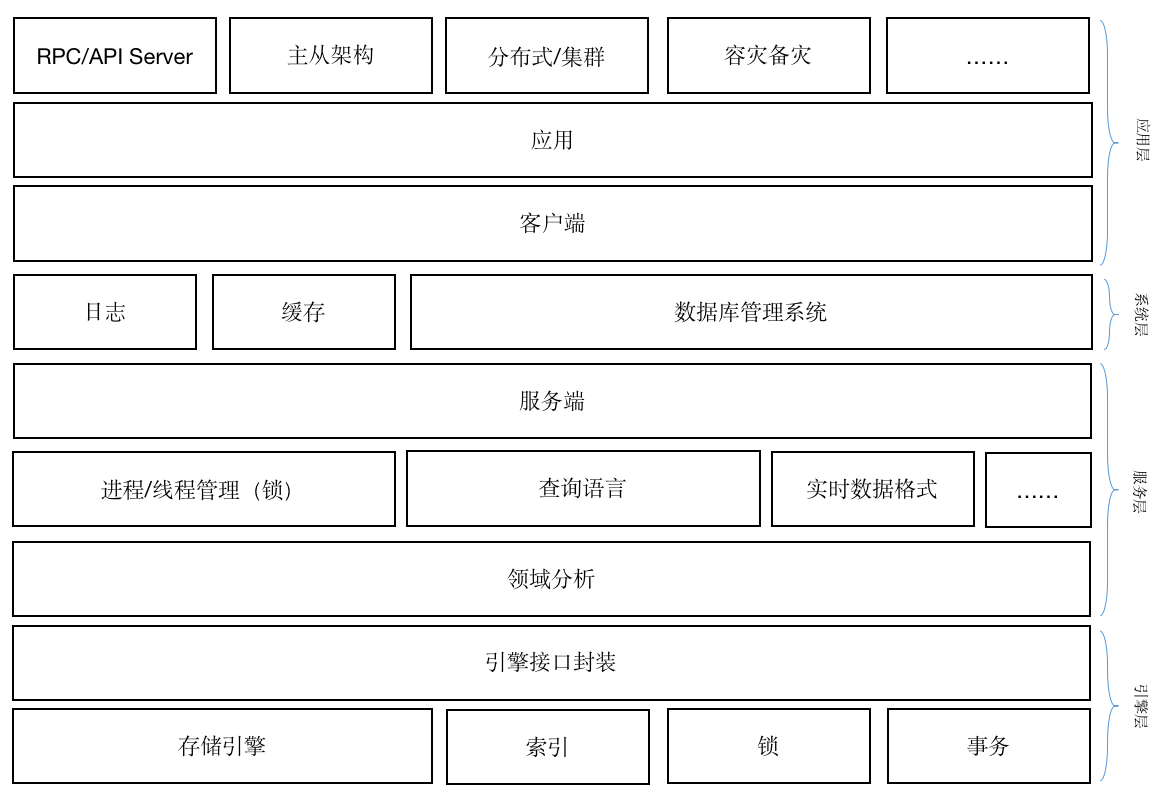
在上述架构图中,处于最底层的,是引擎层,我们可能会挑选市面上比较中意的存储引擎,比如MySQL所选用的innodb,Elastic和Solr所选用的Apache Lucene等等。而存储引擎,很大程度上决定了整个数据库的一些特性,甚至整个数据库系统的设计都决定了我们是否应该采用该引擎,而一旦确定了采用该引擎,就意味着后续的很多开发工作都将被固定下来。基于引擎和索引算法,设计一套适合该数据库的索引体系,能够在将来的查询阶段提供非常高的性能,但是一般而言,索引的建立又会花掉性能。例如Elastic作为知名的全文搜索引擎数据库,就在索引层面花了大量的设计。有些引擎还设计了读写锁和事务,特别是写的时候,因为大部分存储引擎都是基于文件的,所以在写入文件时,就存在同时写入的问题,而通过锁和事务,就可以有效控制数据错误问题。在这一层,我们要完成“存储单元->存储集合+索引->存储库”的设计,不管是“Column->Table->Database”还是“Object(key-value)->store->database”,都需要在引擎层提前设计好。甚至,在某些数据库设计中,可以同时存在多个引擎,只要封装的好,不同引擎之间还可以相互交互。
在进行更进一步设计之前,我们要知道,不同的数据库,针对的场景不同,除了通用的关系型数据库之外,还有其他场景下的数据库,例如专门用于存储日志的数据库、专门用于大数据分析的数据库、专门用于流程处理的数据库等等。因此,在引擎层的上方,我们看到有一层叫“领域分析”,主要负责对数据应用的场景进行分析,以更清楚自己的设计需求。只有搞清楚自己的需求之后,我们才能知道,我们是否存在有多进程的需求,是否需要需要提供C/S架构的服务层,如果都不需要,只是简单的存取数据,那么我们的数据库设计就到此结束了,直接用封装好的引擎接口就可以了,比如我们在一个手机端app中用来存取用户在app中进行的内容创作等等,我们可能只需要用到sqlite的封装即可,不需要再往上走了。但是,假如我们需要考虑多进程或多线程或多用户的问题,就需要继续往上。
我们都知道,如果基于存储引擎进行数据存取,就会存在一个争抢资源的问题,比如用户A需要写入一条数据的同时,用户B也需要写入,此时,就存在一个争抢。而为了避免这种情况发生,存储引擎一般都会做一个设计,即只允许在单一线程中打开自己,并通过一个PID文件记录打开自己的线程,再通过事务机制来控制写入顺序。但是,正是这一看上去合理的设计,导致我们在面对多用户读写时,由于单个用户的访问往往都是独立一个进程来执行,因此,我们需要做一个架构层面的设计,来达到这个目标,这个架构就是我们常说的C/S架构。我们在Server端用一个进程来负责数据的读写,而不同的用户通过Client端向Server发送消息,所有读写都交给Server端统一处理,从而达到可多用户同时读写数据的效果。至于查询语言(如SQL等),统一在Server端完成执行,当然,我们可以把SQL的解析等放到Client端,从而减少服务端的运算压力。C/S架构也好,B/S架构也好,我们都会发现,服务端需要强大的机器性能,才能支撑我们的某些需求。
在服务端之上,我们还会提供更多的能力,这些能力本质上不属于数据库本身,但是却对数据库的管理有非常大的帮助,例如日志和缓存。数据库管理系统则是可以提供用户和权限,以及提供可用户数据本身的管理的可视化页面,甚至像Kibana还提供了统计分析的能力。
前面讲,C/S架构也好,BS架构也罢,我们的瓶颈在Server端,而通过应用层,我们可以对数据库做更上层的架构设计,通过云计算的能力,把数据库从底到顶都实现一遍优化,以确保数据库的吞吐能力,以及安全风险的管理等等。
我们在市面上见过很多非常知名的数据库,例如MySQL、PostgreSQL、Oracle、Mongodb、redis、ES(本质上算引擎)、clickhouse等等,同时,在不同公司内部也会自己设计和实现数据库,例如华为的GaussDB、Facebook的TiDB、中兴的GoldenDB等等。这些数据库有的规模非常宏大,单无外乎都是上述的架构模式。
LevelDB引擎
几年前我研究indexedDB时不断阅读标准文档,作为国内比较早深入研究该库的开发者之一,在阅读标准文档时发现它的设计非常有意思,之后无意之间知道它的底层是基于leveldb实现的,随后我就对leveldb非常痴迷。虽然作为前端开发者,我并没有太多兴趣去阅读leveldb的源码,但是谷歌的这一小巧的数据引擎,让我觉得可以用它做不少应用的存储工具。
简单讲,LevelDB在很多领域被应用,我们前端开发最熟悉的就是indexedDB、localStorage等等,facebook从leveldb的源码fork了一份经过优化后发布了rocksdb,并基于它发布了TiDB(后面更换了引擎)。我之所以关注它,是因为它让我接触了存储引擎这一比较底层的概念,我以前只了解比较上层的数据库,很少有认真思考它的底层数据最终落地为文件时,是如何去存储的,而通过对leveldb原理进行了解后,逐渐明白,原来最终一个数据库存储的数据,不是纯粹的把数据序列化之后生成一个文件的buffer,而是有多个层面的架构设计,最终文件系统里面的文件,也不是纯粹的序列化buffer而已。
正如其名,leveldb的特征正在于它的分层设计,更细节的可以阅读其他博主的介绍,我可能不能讲的很详细,总之,基于它的分层设计,leveldb在读写上有 不错的表现。把它作为我们应用的数据存储工具,是一个不错的选择。
同时,leveldb提供了nodejs的封装,在它的封装中,包括leveldown、levelup、和其他封装。其中,我们常用的是levelup,它提供了统一的抽象接口,这些统一抽象接口即是我们更换底层的存储引擎,在其他包中导出时,也是拥有同样的API。用这些nodejs的包,我们可以做出不错的技术选型,然而,要真正构建起数据库,还是不大够。
用NodeJS写一个数据库
LevelDB提供了最简单的封装,包含了基础的kv存储、锁,并且levelup实现了类似事务的封装,不需要开发者主动去调用存储的open和close。但是,一个LevelDB实例,只提供一个kv的store,且只能存储字符串或buffer类型的值。我们需要一层一层的封装出自己的数据库。
引擎接口封装
在引擎层,我们需要做两件事,一是支持传入普通的object,我们自己序列化之后再存入到库中;二是需要支持索引。其中,索引部分,我们再创建一个store来存储索引。索引的算法和数据结构有很多种,我们从B/B+树、二叉树、Hash表等算法中挑选一个,既然leveldb本身就是kv,那么我们就用Hash表吧。
class Store {
constrcutor(options: { rootPath: string }) {
this.options = options;
// TODO 实例化LevelDB,创建一个用于存储数据,另外一个存储索引
}
query(params) {
// 查询数据
}
put(data) {
// 写入数据
}
}
我们创建一个Store的概念,一个Store里面就包含了存储的数据和索引,并且在内部实现了索引的算法。
有了Store之后,多个Store放在一起,就是一个Database的概念了。稍后,我们在服务端,可以实现创建和管理Database的能力。
服务端
实现C/S架构的S端,我们使用dgram模块启用一个UDP来运行服务,监听来自客户端的请求。同时,在服务端,我们要实现库的创建和管理能力,日志、缓存和数据库管理都需要实现。
不过,我们为了让这个数据库轻便一些,我们并没有把它设计为多database的,而是单database单store的,也就是说,它就像localStorage一样,整个应用只有一个kv模型。因此,我们不需要完整实现库的创建和管理,只需要通过服务,能让我们的库在server端拥有读写能力即可。
class Server {
constrcutor(options: { db: Store, port: number, host: string }) {
}
start() {
const socket = dgram.createSocket('udp4');
socket.on('message', () => {
// TODO
});
socket.bind(this.options.port, this.options.host);
this.socket = socket;
}
stop() {
this.socket.close();
this.socket = null;
}
}
使用UDP的好处,一方面可以拥有更好的性能,另一方面可以服用TCP的端口。
最后,我们写一个脚本,让服务跑起来:
const { port, ROOT } = require('./config');
const Server = require('./cs/server');
const Store = require('./db/store');
const path = require('path');
const rootPath = path.resolve(ROOT, 'db');
const db = new Store({ rootPath });
const server = new Server({
port,
db,
});
server.start();
接下来,我们用pm2将这个服务启动起来,那么,一个正在运行的数据库服务端就跑起来了。
客户端
既然服务端已经起来了,那么,接下来,我们就是连接到服务端,完成操作信息的发送和接收就可以了。基于dgram来访问UDP服务也是非常方便的:
class Client {
constrcutor(options: { port: number, host: string }) {
const socket = dgram.createSocket('udp4');
socket.on('message', (e, address) => {
// TODO 检查是否为对应port发来的消息
});
}
// TODO
}
一旦我们有了客户端封装程序,我们就只需要在我们的应用中,使用该封装,这样就可以连接到服务端,完成数据的操作了。而且,由于我们在服务端实现了各种设计,可以保证高效的请求吞吐和数据的准确读写。
结语
本文的重点在于梳理一个数据库系统的常见架构,再基于这个架构,用nodejs和leveldb实现一个我们自己的数据库。当然,要让数据库稳定运行,且能够支撑庞大的用户请求,还需要应用层面的架构,例如做一些主从设计,甚至分布式集群设计等等。虽然本文的内容非常简单,但是通过这一介绍,让我们也能在数据库的设计中,有了一定的基础了解。
2023-07-02 1713

