facebook生产有技术深度的垃圾
facebook从10年前开始在技术领域作出了非常大的贡献,在前端领域,出现了react,之后又出现了LLaMA。然而,随着时间的流逝,facebook这家公司正在衰亡,伴随而来的,是以前的一些项目的维护人员逐渐流失,因为无法维护,导致很多问题。今天要指出的,是两个非常有技术深度的,却没人维护的,让我非常后悔采用的两个东西:faiss和rocksdb。
我在几年前采取了这两个工具,但是现在,这两个工具成为我的项目毒瘤。我现在每次在一台新机器上执行yarn,都感到心惊肉跳,这两个东西都需要编译,而现在总是无法正常编译。对了,yarn也是facebook的东西。在用了这么多年之后,我不得不因为这两个没人理会的垃圾寻找出路,rocksdb我使用leveldb替代,要改代码。faiss-node我自己fork了一个,发了一个新包faiss-node-napi8,如果你也在用faiss-node,你可以在package.json中这样写:
... "faiss-node": "npm:faiss-node-napi8@^0.5.1", ...
虽然这是过渡方案,但是起码能跑起来。
这件事让我开始反思,我们在做技术选型的时候,应该要考虑到这种问题。随着nodejs、webpack、vite等基础设施的升级,很多以前的技术实现会出现不兼容的情况,而如果此时项目无人维护,而你的项目又重度依赖,那么就非常非常痛苦。你看,即便是强如facebook这样的大公司,也有很多当时有技术创新,却最后沦落为无人理睬的垃圾的项目。那么,就更无法对个人的项目库更加信任。因此,我们应该挑选那种社区比较大的开源项目作为技术选型,只有当社区足够大,才能支持项目可以持续维护。
只用了两招,网站秒开
感觉网站首开速度慢,虽然有缓存,但是大部分新用户第一次打开竟也要6-7秒。一开始想的是从拆包分包的角度去做,后来发现没啥用,vite打包无法做到对单包再拆分。之后又考虑SSR,改了半天,各种与浏览器端写法不兼容,发现SSR必须是从一早开始就按其思路来写,先浏览器端再来改造的,都很坑。之后想了一会儿,觉得从前端的角度去搞没前途,想想后端的办法。仔细观察了一下请求记录,发现js包文件很大,有1M多,再仔细瞄了一眼,发现没有开启gzip,于是感觉去服务器上开启gzip试试。经过折腾,一试,果然快了很多,看请求记录,确实压缩到了200k。但是仍然觉得还不够,突然间发现了两条记录之间有时间差,想起有一条浏览器同时发送请求不超过6条的规则,想到是不是因为这个原因,而对应的解决办法就是开启http2,于是又去找资料开启,回来再试,果然,这次真的是秒开了。从6-7秒,到秒内开,实际上只做了非常少的一点nginx的改动,可见有的时候,吭呲吭呲,还不如换个赛道。
通用人形机器人的一些遐想
今天,2024年10月11日,在特斯拉的发布会现场,除了无人驾驶出租车、无人驾驶出租车巴士以外,全新一代的人形机器人Optimus成为焦点,它不仅可以做家务猜拳,而且预估价格在两到三万美元。我在《Robust》播客节目中曾经提到,通用机器人,是人工智能未来的唯一方向。本文就从我作为AI从业者的角度,聊一聊对通用人形机器人的一些遐想。
基于多模态大模型的智力
过去很长的时间里,机器人的功能都是由固定的程序来实现的,这也就意味着它们会按照固定的单一或几种模式,基于穷举规则的办法,做循环动作,因此,在工业领域应用较多。但随着大模型的诞生和广泛应用,我们发现它能提供智力支持,因此出现了火热的AIGC。机器人领域也迅速跟进,让AI来作为其大脑,代替原来的“基于穷举规则”的方案。这让机器人的反应方案更加智能化和多样化,同时,基于Agent技术,确保目标执行的准确。
多模态大模型则可以直接对接机器人的传感器,将视觉、听觉等信息,全部统一交给中枢大脑处理,而无需像以往一样,需要前置一套图像识别的智能算法,再以结论的方式交付给中枢反应。一旦机器人拥有了视觉、听觉,再配合大模型本身的智力提供,机器人就可以自主的完成对环境的响应,而且由于简化数据流程,其响应速度也可以变的更快,应变处理的能力也就更强,这也就是为什么Optimus可以和人类玩剪刀石头布。
不过,大家不必过于惊慌,毕竟大模型本身的架构,并不能保证智力的准确性,总体而言,目前人类的智力还是有优势,还不可能出现机器人起义反抗人类的情况。
云端模型vs本地模型
那么,Optimus的智力来源,是本地模型,还是云端模型呢?马斯克的Grok作为超强模型,从英伟达那里拉来了几大卡车的H100,为Grok提供超级算力。同时,为机器人植入5G芯片,保证网络速度,就可以让机器人以微秒级对环境作出响应。同时,作为一个这么大体积的机器人,完全可以内置一个强大的本地AI芯片,配合大内容强CPU和GPU,可以并行的对环境变化作出决策,再根据云端的网速,如果网络震荡,可以降级到用本地小模型给出的决策方案。
家务场景
帮助主人完成家务,是我对人形机器人的最大期待。随着人类社会的演进,社会生活的模式会越来越把个体抽离出具体的事务,比如十几年前那种下班回家做饭一家人一起吃完再去散个步的生活方式,不会再成为整个社会的主要模式,人们对时间的紧迫感越来越强,而且个人精力的有限性,人们会失去更多的家庭时间。只有那些能请的起佣人的富人阶层才能既有足够的时间完成自己想做的事,又有整洁的家庭环境让自己可以和家人享受生活。而人形机器人的出现,则可以帮助人们获得优质的生活。房间打扫、物品收纳整理、做饭、拖地、洗衣服和晾晒收纳、快递收发等等,这些原本需要花很多时间去处理的事,交给机器人完成,那么家庭成员就可以有更多的时间享受家庭生活。
养老场景
人口老龄化严重的国家,必然会将养老纳入福利体系,但侍老人员问题频有发生,而引入人形机器人,既可以解决照顾老人这种疲累的工作,又可以陪伴老人,从精神层面解决老人的空虚感。
家庭医生、家庭教师、家庭律师
借助它的智能,机器人可以弥补普通人知识的不足,在遇到对应问题时,提供临时的解决方案。
以健康问题为例,我们现在很多人去医院看病,往往是这样的情况:挂号抢不到,只抢到了一周以后的号;去了以后,排队2小时,看病30秒;拿药回家。为什么真正的30秒,却要占用我们那么多时间?核心原因在于医生的经验,看一眼就能和过往的病例联系在一起,如果没有其他症状,连化验拍片都不需要,就直接开药了。那么,如果把这个经验赋予普通人自己呢?当然,这是不可能的。而基于专有医药大模型,则可以提供这种经验和决策,在小瘟小病上,可以节省时间,在大病上也可以提前预料,在家就有机器人帮做体检。
以教育为例,我们可以发现,西方很多成就破丰的人物都拥有较为富庶的家庭。这些富人阶层一方面通过舆论强调孩子发展过程中的开发性和趣味性,另一方面在自己家庭内部又对自己的孩子严格要求,并提供各种教育资源,特别是邀请名师作为家庭教师。而当具备智能的机器人进入普通人家庭,就可以利用其智力辅助孩子的学业,例如在数学和编程方面的辅导。
这种将智力外置的社会形态,会成为人工智能时代的重要标志,人们会把精力放在自己感兴趣的,无法被替代的工作上,而非低级工作中。
收费模式
我想,机器人收费模式一定是以汽车的收费模式为基础进行演化的。一款机器人,一定存在低配中配高配,同时还有选配。机器人的收费项目包含硬件部分和软件部分。硬件部分,包含出厂原价扣除厂家优惠、定期保养维护费,同时,我认为随着机器人硬件技术的成熟,新材料的运用,厂商还可以提供硬件升级和扩展服务,例如买了两年后开始流行给机器人装一对翅膀,那么你可以返厂加这对翅膀。软件部分,除了基础的套餐服务外,裸机只能完成较为简易的指令,想要机器人能下厨能看病,都需要另外购买套餐,通过云端升级来获得新功能。甚至就像特斯拉一样,硬件支持,但是软件不给你这个功能,你得买套餐才能获得。
国家安全的担忧
一旦海外国家机器人技术成熟,并量产,最后广泛用于军事,那么蓝星最强陆军可能将面临巨大挑战。虽然我们国家的无人机技术和产量已经形成了碾压趋势,但是未来战争一定是海陆空的机器人先行,除非把所有资源都打光,才轮到人上,而我国目前的机器人行业现状却不容乐观。前段时间中国机器人大会上,几家国内顶尖的机器人公司,呈现给我们的,还是上一代基于规则为主的机器人,与国外的差距仍然不小。于此同时,从事该行业,或者行业的预备人才,也严重匮乏,在面对国际环境日趋紧张的当下,令人担忧。
最近关于AI创业的一些想法
我本身是一个技术人,过去对市场和推广的东西比较木讷,我觉得这是一种错误的价值观。人的价值观是由多个方面组成的,例如是非对错、道德取向,但是,在当今社会,我觉得对于普通人而言,最重要的价值观是对“什么是有价值的”的正确认知。价值观本身是取舍,而取舍本身必然存在冲突,有冲突就有内心的挣扎。我们大多数人比较安逸于舒适区,对价值的判断有偷懒的惯性,因此,对于“什么是有价值的”往往用是非对错、道德取向等去判断。这使得我们作出错误的决策,错失很多好机会。在过去相当长的时间里,我都认为很多人在做投机,从而赚“亏心”钱。但最近我开始重新认识到,在赚钱这件事上,很多看上去投机的现象,本质上有其必要性,没有这种投机,市场无法表现足够的活跃。例如,我们一开始都认为抖音很低俗,但这一年,我越发觉得抖音是目前信息流通最快最广泛的,这在中国是好现象,这意味着通过信息差,我们可以获得更多的机会。在此之前,我还从未见过抖音这种信息流通形式,虽然它上面鱼龙混杂,需要辨别,但即使如此,我们仍然能够从错误信息中获得客观信息趋势。
随着我想法的变化,我不再执着于以前所认定的一些理念,例如追求技术深度、坚持干货输出、认可小而美,当下,我有一些有悖以往的认知,现在我认为小而美并不美,干货输出并不能获得有效流量,追求技术深度不会沉淀出竞争力。以OpenAI为例,虽然很多公司的强调开源,但是本质上它们都不属于上述任何一项,OpenAI赢在架构上,它们有追求,但是不是技术深度的追求,而是广度的追求,它们在GPT-2之后就不开源了,开源只是流量入口而已,他们始于chatGPT但是现在在全AI领域发力,不仅不小而美,相反它们想做未来的龙头甚至垄断。
当然,这只是我自己的想法,有些东西过于邪恶,不适合输出,就删掉了。
用Ideogram设计网页和logo
Ideogram其实已经上线很久了,只是最近2.0发布后才突然爆火。它的核心竞争力在于对文字的处理,同时它可以设计出“设计稿”风格的图片,因此,利用这两个特征,我们可以用它来设计我们需要的网页。当然,其实我们核心目的是设计出漂亮的界面,文字部分实际上作为参考,因为我们往往需要把这些文字替换为中文。
如何使用Ideogram?
进入Ideogram官网,只能使用google或apple账号登录,登录后直接在其页面的输入框内输入你想要的内容即可。与SD不同,你只需要按照自然语言进行描述即可,不像SD还需要各种关键字来出触发,也不像Midjourney还要输入命令符。你只需要按照自然语言的描述来输入prompt,以及几个非常简单的选项,即可。
然而,由于某些原因,国内目前无法直接使用Ideogram,这让我们无法使用这一优秀的生图模型。
你可以通过Developround来使用Ideogram,甚至你可以通过API来将它集成到你的服务中。只需要在Developround中进入 https://www.developround.com/service/37/entry 即可进入该服务。
用Ideogram来设计logo
制作logo的核心,将style_type指定为Design,在prompt中指明要创建的事物是logo。我们来看一下一些示例
candle logo in a minimalistic style. minimalistic silhouette of the goddess Hestia. color combination: blue, green, purple, gold. use the following text for the signature: “Hestia. Concept store”.
Create a logo in the red color of a perspective Trojan helmet, flag, shield, era, fierce, heroic, athletic, dark, bloody, fast, text with “INVICTUS NEUSS”, transparent background, sci-fi, illustration, fashion, poster, cinematic, typography.
Logo of “Yeboster” word, inspired by nature. Its simple design, is highly detailed, Typography.
A bright round logo in the style of a badge with the words “TaleCraft Gaming” highlighted in bold stylized font. The background shows a lush green landscape with trees and mountains 3d in Minecraft style . In the foreground, a knight in shining armor is facing the dragon. The knight’s sword is raised, and the dragon’s mouth is ablaze with fire as if he is about to spew flames. Small pixel symbols of the video game controller float around the edges of the stage. The logo evokes memories of fantasy, adventure, retro games, and epic stories. The overall style should be clean, clear, and visually dynamic.
在这些提示词中,我们可以很容易知道用户的目的是要创建一个logo,而且logo中都有文字。
虽然通过自然语言可以描述图片,但是,你可以看到在这些prompt中,存在一些术语,比如background, foreground, typography等,这些术语在大语言模型中,具有非常准确的含义,因此,多看看别人的prompt,或许就能掌握这些规律。
用Ideogram来设计网页
制作logo的核心,将style_type指定为Design,在prompt中指明要创建的事物是website page。另外,与logo不同的是,网页需要明确指出页面布局,或者说需要网页中的哪些元素,不需要太精确,因为模型会智能帮你处理。
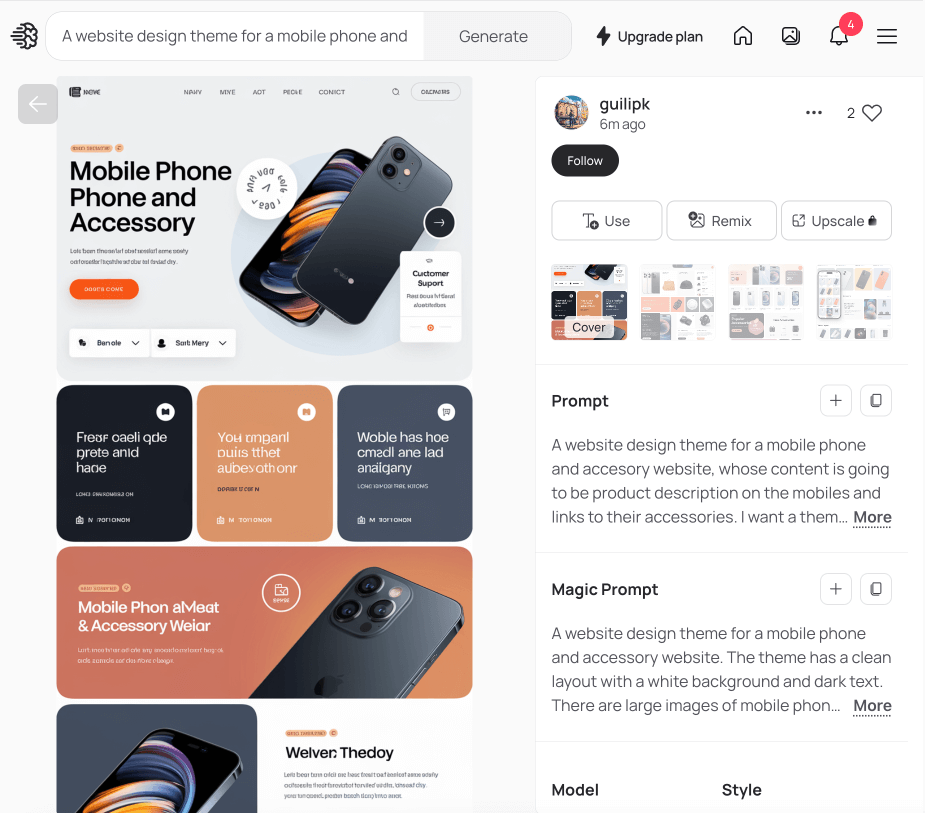
A website design theme for a mobile phone and accessory website, whose content is going to be product description on the mobiles and links to their accessories. I want a theme which showcases trust and understanding for the customers and is also easy on the eyes. Give me mobile, tablet and desktop layouts

Design a modern, responsive website layout for a technology startup company. The homepage should feature a large hero section with a call-to-action button, a clean navigation bar at the top, and sections for showcasing services, client testimonials, and a blog. Use a minimalist color palette with shades of blue and white. Include a footer with social media links and contact information.
以下是一些用于生成网页设计稿的建议:
- 明确目的:清晰地说明网站的用途(例如,电子商务、作品集、企业、非营利组织)。
- 定义受众:描述目标受众,这可能会影响设计的风格和可用性。
- 提及关键元素:列出任何必须有的部分,如页眉、页脚、评价、画廊、表单等。
- 详细说明美学:明确风格——极简主义、现代、复古、俏皮、企业等——并提及特定的配色方案或图像。
- 响应性:如果网站应该是移动友好的,请明确指出。
- 用户体验:描述您希望网站包含的任何特定用户流程或交互(例如,平滑滚动、悬停效果、视差部分)。
可以看到,Ideogram帮我们设计出了完整的网页,而且这些设计要素都属于非常主流的设计元素,这样,你再也不用担心没有网页制作的灵感了。

