react jsx编译后中文乱码问题
在一次开发中,我发现,构建出来的react应用出现中文乱码现象。于是我很自觉的,在html头部添加 <meta charset="utf-8" />,然后问题解决了。但是作为资深搬砖人,必须得搞清楚,为啥会乱码。
于是我打开了构建后的文件,发现里面中文被转码为unicode了。

这就尴尬了,但是经过观察之后,我又发现,只有createElement的部分被转码,其他部分的中文还是中文。

于是我想,肯定是编译工具在搞鬼,我得找到是哪个地方的问题,把这个转译给关闭。要么是webpack,要么是babel jsx。
于是还是用bing进行中文搜索,没有一个结果指向这个问题。再用英文搜,也没有找到相关解决办法。最后只能请出google大神,找到这个栈漏答案,找到了相关资料。兜兜转转一大圈,发现这是react自己埋的坑,跟编译工具无关(也有关),总之就是关不掉,只能这样,放弃挣扎。
-
之前也有遇到这情况, 想改个项目里的标题, 搜中文搜不到, 结果发现是unicode#1015 ID_1188 2021-03-02 16:29
我时常有一些执念,以至于有的时候不合群。我遇到无法修改react传入的props的情况,我大概知道在react源码里面干了些坏事,但是我想确认这一点,于是我在bing搜索相关问题。大部分的答案,无非是和react单向数据流相关的一些废话,谁不知道这些原则,我现在就是想打破这些原则,而我打破不了,你只告诉我原则就是根源,我呸!然后我找了很久,在漏栈上找到一个答案 https://stackoverflow.com/questions/26089532/why-cant-i-update-props-in-react-js 这个答案获得了20个反对票,最主要的原因在于,他指出只有通过修改react核心代码才能实现,于是被一路狂喷。我……我被气炸了!这个回答直指问题本质,就是react中使用Object.freeze(element.props)导致我们修改props会报错。我tm不懂,为啥真正指出问题所在的答案被驳20次,而千篇一律的讲废话的答案得到大量赞同。真是只要主义,不要实际!
-
因为 react 社区动辄喜欢谈设计理念,原则之类的,不考虑实际使用者的场景
-
有的时候爱,有的时候恨,选择太少了#1007 回复给#1006 否子戈 2021-02-05 19:52
-
没,有时候吾辈反而觉得前端选择太多了,各种乱七八糟的工具链和层出不穷的类似的轮子,上层应用的基础变化太快了。。。
-
有趣的例子.#1009 ID_1188 2021-02-09 15:40
动态表单可视化拖拽设计器
我为什么不在async函数中使用try...catch?
总之一句话:在async函数中使用try...catch会导致调试难道增加。且任何使用使用try...catch的场景,都会增加调试难度,比如react的报错信息,有的时候,你怎么都找不到问题代码具体在哪个位置。
当一个Error产生的时候,Error会用stack字段记录该Error产生的具体位置。只有,我们得到原始的Error,才能获得原始的stack信息,但是通过try...catch语法,往往会屏蔽原始的Error,导致我们追逐不到错误的原始位置。比如:
<script>
'use strict'
async function calc() {
try {
const x = await a + await b
const y = x + await z
return y
}
catch (e) {
alert('计算错误')
}
}
calc()
</script>
我们用alert来替代我们经常使用的toast, popup等方法。一旦我们通过交互形式接住错误时,我们就直接放弃了获得错误原始信息的权利。
async函数本质上是创建一个异步函数,而非创建一个封闭式的闭包。没错,如果你在async函数中使用try...catch跟使用闭包没有什么区别。异步函数的目标,是完成异步操作,但其中重要的一点是,它的错误是可以被捕获的。为了实现这种捕获,有些开发者会在 catch 中再次把错误抛出来,比如 catch (e) { throw e }。但是这样做,会导致程序在这里又结束了。所以,这种做法又不符合在async函数中使用try...catch的目的。
对于我个人而言,我从来不直接在async函数中使用try...catch,定义async函数是一个纯粹的async...await结构,在使用该函数时,使用.then().catch().finally()接住函数执行过程中的结果逻辑。
-
有点误人子弟了。。。async 函数中的 try/catch 和 then/catch 没什么区别吧?
-
要正确使用#1001 rxxy 2021-01-14 17:28
Angular怎么实现依赖注入自动实例化的?
Nautil是基于react的完备的前端开发框架
完备前端开发框架需要具备啥呢?我想了很久,最终觉得,主要要满足如下条件:
- 模型系统
- 控制器系统
- 视图系统
虽然是传统的MVC结构,但是在这些年的前端框架发展过程中,没有发展出真正的MVC框架。为什么会这样呢?主要的原因是,前端框架只要解决好视图编程,就已经足够解决日常开发中的大部分问题。所以,jquery, react, vue都被称为是框架,它们提供了一种视图渲染的方式。但是,这些框架,本质上还是解决视图渲染问题,而没有解决数据的抽象(也就是数据模型),数据如何映射到视图,数据的变动映射到具体的行为,以及它们之间的联系,这一完整的链条。现有的所有前端框架,都没有实现这一完整逻辑。而我自己想要实现这一逻辑,以在复杂的2B型系统中,可以构建完整的开发逻辑。而Nautil实现了这一完整逻辑,虽然目前支持的还不够完整,我还在慢慢打磨它。接下来,我举个例子,以及用一些伪代码来描述,这里所谓的MVC架构,和现在市面上的前端框架到底有啥区别。
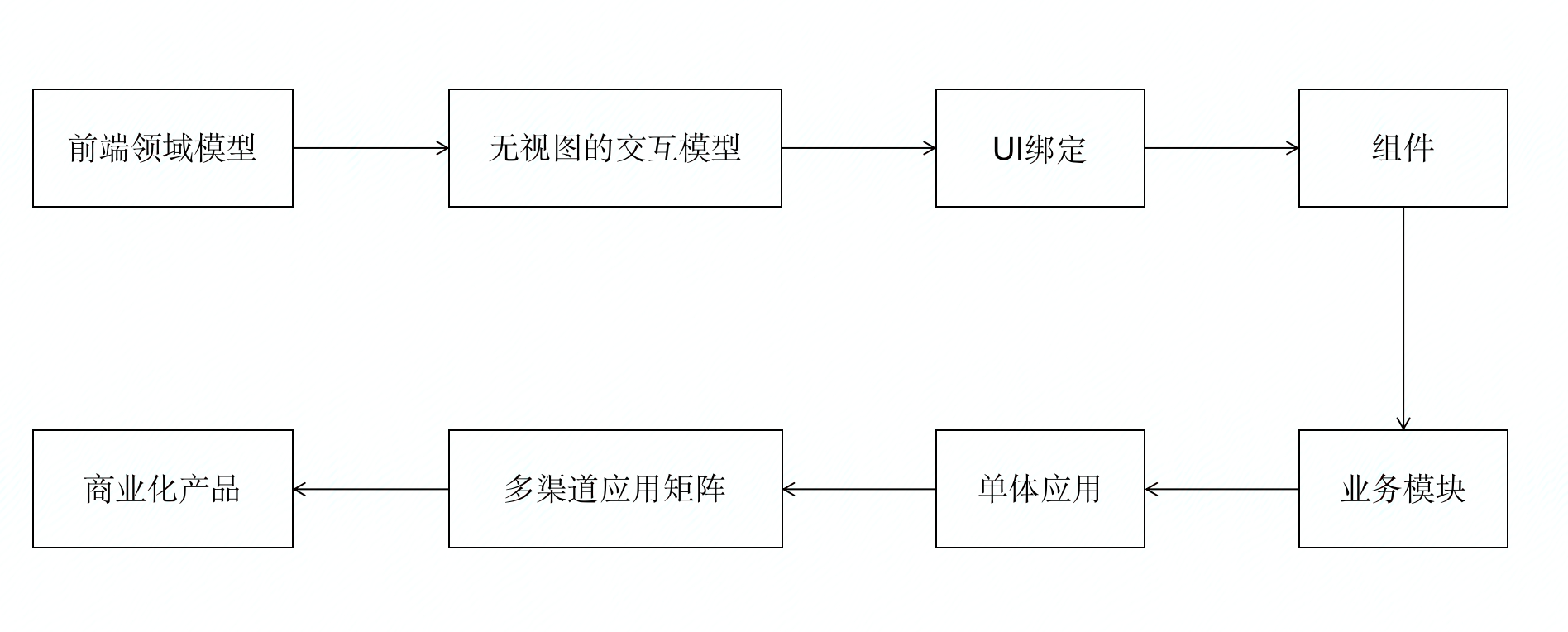
我在腾讯内总结的一套前端演进模式,对于应用团队而言,他们需要按照这个步骤,不断更迭自己的项目最终达到一个最大化效益的效果
首先看下“前端领域模型”。
在我的博客中,你可能已经了解过相关的内容,如果没有读过相关文章,可以通过我博客上方的搜索功能搜索一下。简单的说,在前端去构建一套有关前端如何使用业务对象所抽象的领域模型的一套实践。比如,你的主要业务是物流,那么就一定会涉及一个物流单,而这个物流单,会由寄件人、收件人、货物、保险、托运机构等等信息,整个业务还涉及支付、配送人等等。而由于这些所有信息,都不是确定的,需要通过系统进行填写补充。而这些动态的数据,字段与字段之间有一定的联系,字段本身还有一些规则(元数据),这些约束条件保证要处理的数据不是随随便便的,系统必须是在具有明确逻辑的数据流转下运行,而不是乱七八糟的数据。用以完成这种约束的,就是前端的领域模型,领域模型保证了系统中,数据的一致性和合理性。怎么建领域模型呢?其实很简单,主要要解决的,是一个业务对象所拥有的字段的元数据,以及可能存在的字段与字段之间的逻辑关系。例如我们这样定义货物这个对象:
class Kind extends Meta {
static default = 'life'
// 规定了type字段的类型,只能从这几个值中选择一个
static type = new Enum(['life', 'study', 'traffic', 'office'])
}
class Cost extends Meta {
static default = 0
static type = Number
}
class GoodModel extends Model {
static kind = Kind
static cost = Cost
}
这里定义了一个有关货物的模型,它由kind和cost两个字段组成。其中,规定kind字段必须是一组值中的一个,而cost字段必须是一个数值。
接下来看看“无视图的交互模型”。
在进入视图编程之前,我们要搞清楚,产品经理给的需求中,哪些是属于业务的交互逻辑,哪些是属于视图的交互逻辑。比如,一个按钮,点击之后,要将物流信息流转到下一个阶段,这是业务交互逻辑。一个按钮,点击时弹出一个窗口,询问用户要不要进入下一阶段,这是视图交互逻辑。但是很明显,这个业务逻辑是依托在交互逻辑上的,也就是说,只有完成这个交互,才能完成这个业务。
那这里就有一个问题,在产品经理提出这个需求时,他并不基于前端所使用的技术,因此,也不会考虑说,这效果是基于react的,还是基于vue的。我们有没有一种办法,可以在没有视图(框架)的前提下,对需求提出的交互,以及交互所连带的业务,做模型化编程?我们来看看我下面的这段代码:
class TransferController extends Controller {
static good = GoodModel // 使用到Good这个模型
CostInput(props) {
return [
'input',
{
...props,
type: 'number',
value: this.good.cost,
onChange: (e) => { this.good.cost = e.target.value },
},
]
}
}
这个控制器是对货物一些列逻辑的控制,它基于Good模型,并输出一个CostInput接口,这个接口是一个对交互的描述,它只描述了输出一个什么类型的组件,其属性有哪些。至于这个接口,将会被怎么渲染,则是视图层编程要做的事。
再看看“UI绑定”。
得到无视图交互模型实例之后,利用交互模型的接口,就可以完成对应的渲染,渲染过程,也就是UI绑定过程,通过react或vue进行绑定,比如上面我们创建的CostInput这个接口,我们用react来进行渲染:
class OrderView extends Component {
controller = new TransferController()
render() {
const { CostInput } = this.controller
return (
<div>
...
<CostInput className="form-item" />
...
</div>
)
}
}
在react组件中,我们通过某种处理,可以直接如上使用这个被输出的接口(组件)。而这个组件的业务和交互逻辑已经在controller中绑定了,在组件中,仅仅是为了实现视图层绑定(例如样式绑定)。
之后就是“组件”了。
在组件层面,我们需要完成和视图相关的交互逻辑,比如,我们要在打开一个弹窗之后,用户点击确定,才能能完成流转这个过程,其中的打开弹窗,点击确认这个过程,属于视图交互过程,在react组件中完成编程,而流转过程,我们已经在controller中定义完了。
组件之上的“业务模块”和“单体应用”,就是我们熟悉的react应用开发,这里就不赘述了。
接下来看看“多渠道应用矩阵”。
所谓多渠道,是指分发目标的多。比如,你有一个新闻网站,用户多起来了,又做了一个同名的APP。实际上,这个网站和APP,甚至直接将APP代码转化为微信小程序,这些渠道都是同一个应用的不同渠道。它们或许在某些方面有其独特的地方,比如说有些功能网站有APP没有,有些功能只有APP有。但是,本质上,它们是一个系统的多面,是为达到同一个业务目标完成的一系列布局,它们在业务上,为同一个目标服务,但是,它们在形式上,载体上,都不同,因此,称它们为“应用矩阵”。
最后看看“商业化产品”。
你可能非常熟悉Vue、React,同时,你也可能很熟悉AntDesign、ElementUI,还有,你还可能知道MySQL、Docker等。你一定听说过,一个免费产品背后,有一个付费版本的概念。没有错,商业化产品的目标,就是赚钱。一旦你要为商业化服务,那么你的应用形态就需要适应更加丰富的需求。比如我在腾讯内部,我们自己团队的应用一开始只服务与内部和合作厂商内部,后来,产品不错,就上腾讯云开卖了。另外,一些G类机构,还要求自己私有化部署。总而言之,言而总之,商业化产品要求你的应用架构可以做到无孔不入,不要上来你给我说“这个做不到”“那个做不了”,我只要通过把这个应用按照客户要求提供,躺着赚钱就行。这就是商业化。
通过这些思考,你可能会慢慢领悟,为什么前端现有的各种框架,都不是我想要的框架。这也是我做Nautil的核心价值。
ES查询相关知识

https://www.elastic.co/guide/en/elasticsearch/reference/7.x/index.html
https跨域net::ERR_SSL_PROTOCOL_ERROR
跨域跨域……哎!
我从一个https引入了一个http的图片,然后net::ERR_SSL_PROTOCOL_ERROR。我从一个https向一个http发送ajax,然后net::ERR_SSL_PROTOCOL_ERROR。我从一个https向一个https发送ajax,你TM竟然还net::ERR_SSL_PROTOCOL_ERROR。
鬼一样的net::ERR_SSL_PROTOCOL_ERROR是啥意思?劳资google了半天都没发现文档。最后在大佬的提携下,一点点终于搞掂疗。
![]()
https策略非常复杂,一时半会儿也说不清,仅针对我自己的问题。
图片问题,以及https向http ajax问题,是因为 https://blog.chromium.org/2019/10/no-more-mixed-messages-about-https.html ,垃圾 chrome 强制自动升级协议,我谢谢你全家。。。
而https向https ajax还报错问题,是因为我ssl没有正确部署。为什么呢?因为我自己的主域名放在 a.xx.com 下是一个子域名,而该子域名直接使用了 *.xx.com 泛域名证书,所以可以直接访问。但是,我另一个域名是 b.a.xx.com 是一个三级域名,而三级域名没有 *.xx.com 泛域名支持,所以不能https访问。我的大爷,被这个泛域名证书搞懵了,都是同一个证书,搞的我以为见了鬼,二级域名能访问,三级域名不能访问。最终原因是,理论上两个域名都不能https访问,只不过二级域名被强制 *.xx.com 泛域名覆盖了,所以能访问。
最后,把证书部署问题修好,一切OK了。折腾!
-
实习前阵子给人家写http请求相关的部分时候也是遇到这个错,后来发现是http和https,搜解决办法大家说没别的好办法只能统一https,摸不着头脑…… 结果拉着运维忙活了好一阵重新分配域名。#986 朔兔 2020-12-09 10:12
-
这种也不能埋怨说前端基础不好,这是真因为TM难调试啊,没有经验谁知道是在哪个环节有问题#987 回复给#986 否子戈 2020-12-09 10:51
