时间沉淀,不问世人问自己
今天发现,当下非常火的视频剪辑软件剪映是有深圳市脸萌科技有限公司开发的,“脸萌”是多年前突然爆火的一款APP,在那段时间,几乎所有人都将自己的头像换成了用脸萌软件组合而成的头像。我至今仍在用的开通头像也是用脸萌生成的。虽然脸萌不是最早的捏人软件,但是确实那时最简单有趣的。不过,在爆火之后,很快这款app就退烧了。相信在互联网流速这么快的时代,很少有人还记得这款app,除了像我这种还在使用曾经制作的卡通头像的人以外。后来,我在一些视频网站看到媒体对它创始人的采访,他说到,随着app退烧,公司的业务也开始转型,可能很大程度上会作为技术服务公司,说的难听一点,就是外包。本质上,脸萌app没有盈利模式,所以逐渐褪去色彩也是很正常的,只是作为一家公司,如何在爆款过期后持续运营,是很难的一件事。不少公司或团队不断探索新的爆款,采用低成本高数量输出,博一个中奖概率。但是,我相信脸萌的团队在这些年的沉寂中,没有这走条路,或者说想走但最终条件不足,选择了技术沉淀的道路。我能想象到他们经历了公司从几个人到上百人的发展过程中,经历很多的消耗、迷茫、懊恼等等,但是,我也相信他们在不断的为其他项目提供技术支持的同时,不断的总结了自己的技术经验,形成了一套不错的技术护城河,最终通过技术获得字节这样头部公司的青睐。出品剪映,可能仅仅是因为他们拥有这样的技术沉淀,比别人走的早走的快,现在能把产品做的这么好,算是对这些年默默无声的回报。我相信,就两款软件而已,剪映更有价值,无论是使用的场景,还是未来的商业价值,然而,我们却并没有看到他们团队像曾经一样作为明星团队到处接受采访。这或许就是成长,同样一家公司,不同时期,不同阅历,不同心境。
windows11 资源管理器 该文件没有与之关联的应用来执行该操作
关于win11任务栏的文件资源管理器出现打不开,没有与之关联的应用.....,可以尝试以下方法,亲测有用。
新建txt文档,将以下代码复制进去。
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT\Folder]
@="Folder"
"ContentViewModeForBrowse"="prop:~System.ItemNameDisplay;~System.LayoutPattern.PlaceHolder;~System.LayoutPattern.PlaceHolder;~System.LayoutPattern.PlaceHolder;System.DateModified"
"ContentViewModeForSearch"="prop:~System.ItemNameDisplay;System.DateModified;~System.ItemFolderPathDisplay"
"ContentViewModeLayoutPatternForBrowse"="delta"
"ContentViewModeLayoutPatternForSearch"="alpha"
"EditFlags"=hex:d2,03,00,00
"FullDetails"="prop:System.PropGroup.Description;System.ItemNameDisplay;System.ItemTypeText;System.Size;System.HomeGroupSharingStatus"
"NoRecentDocs"=""
"ThumbnailCutoff"=dword:00000000
"TileInfo"="prop:System.Title;System.HomeGroupSharingStatus"
[HKEY_CLASSES_ROOT\Folder\DefaultIcon]
@=hex(2):25,00,53,00,79,00,73,00,74,00,65,00,6d,00,52,00,6f,00,6f,00,74,00,25,\
00,5c,00,53,00,79,00,73,00,74,00,65,00,6d,00,33,00,32,00,5c,00,73,00,68,00,\
65,00,6c,00,6c,00,33,00,32,00,2e,00,64,00,6c,00,6c,00,2c,00,33,00,00,00
[HKEY_CLASSES_ROOT\Folder\shell\explore]
"LaunchExplorerFlags"=dword:00000018
"MultiSelectModel"="Document"
"ProgrammaticAccessOnly"=""
[HKEY_CLASSES_ROOT\Folder\shell\explore\command]
"DelegateExecute"="{11dbb47c-a525-400b-9e80-a54615a090c0}"
[HKEY_CLASSES_ROOT\Folder\shell\open]
"MultiSelectModel"="Document"
"LegacyDisable"=-
[HKEY_CLASSES_ROOT\Folder\shell\open\command]
@=hex(2):25,00,53,00,79,00,73,00,74,00,65,00,6d,00,52,00,6f,00,6f,00,74,00,25,\
00,5c,00,45,00,78,00,70,00,6c,00,6f,00,72,00,65,00,72,00,2e,00,65,00,78,00,\
65,00,00,00
"DelegateExecute"="{11dbb47c-a525-400b-9e80-a54615a090c0}"
[HKEY_CLASSES_ROOT\Folder\shell\opennewprocess]
"ExplorerHost"="{ceff45ee-c862-41de-aee2-a022c81eda92}"
"Extended"=""
"LaunchExplorerFlags"=dword:00000003
"MUIVerb"="@shell32.dll,-8518"
"MultiSelectModel"="Document"
"LegacyDisable"=-
[HKEY_CLASSES_ROOT\Folder\shell\opennewprocess\command]
"DelegateExecute"="{11dbb47c-a525-400b-9e80-a54615a090c0}"
[HKEY_CLASSES_ROOT\Folder\shell\opennewwindow]
"LaunchExplorerFlags"=dword:00000001
"MUIVerb"="@windows.storage.dll,-8517"
"MultiSelectModel"="Document"
"OnlyInBrowserWindow"=""
"LegacyDisable"=-
[HKEY_CLASSES_ROOT\Folder\shell\opennewwindow\command]
"DelegateExecute"="{11dbb47c-a525-400b-9e80-a54615a090c0}"
[HKEY_CLASSES_ROOT\Folder\shell\pintohome]
"AppliesTo"="System.ParsingName:<>\"::{679f85cb-0220-4080-b29b-5540cc05aab6}\" AND System.ParsingName:<>\"::{645FF040-5081-101B-9F08-00AA002F954E}\" AND System.IsFolder:=System.StructuredQueryType.Boolean#True"
"MUIVerb"="@shell32.dll,-51377"
[HKEY_CLASSES_ROOT\Folder\shell\pintohome\command]
"DelegateExecute"="{b455f46e-e4af-4035-b0a4-cf18d2f6f28e}"
[HKEY_CLASSES_ROOT\Folder\ShellNew]
"Directory"=""
"IconPath"=hex(2):25,00,53,00,79,00,73,00,74,00,65,00,6d,00,52,00,6f,00,6f,00,\
74,00,25,00,5c,00,73,00,79,00,73,00,74,00,65,00,6d,00,33,00,32,00,5c,00,73,\
00,68,00,65,00,6c,00,6c,00,33,00,32,00,2e,00,64,00,6c,00,6c,00,2c,00,33,00,\
00,00
"ItemName"="@shell32.dll,-30396"
"MenuText"="@shell32.dll,-30317"
"NonLFNFileSpec"="@shell32.dll,-30319"
[HKEY_CLASSES_ROOT\Folder\ShellNew\Config]
"AllDrives"=""
"IsFolder"=""
"NoExtension"=""
保存文档到桌面,修改文档名称为folder fix w11,后缀reg格式。
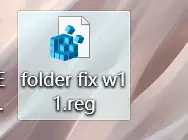
双击reg文件,点击是,添加到注册表中。
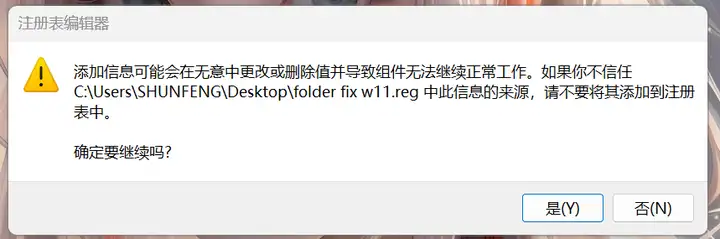
另外win10系统也可以将文件名称改为w10,其他步骤相同。
PM2 + Nginx 502 Bad Gateway
用PM2起node服务,再nginx反向代理,结果遇到502 Bad Gateway问题。我自己猜测,502就是node端报错或者什么原因,导致代理没有找到目标。后来研究很久之后,发现是PM2 --watch模式的原因。
当PM2开启--watch之后,目录下有文件变动的情况下,会重启服务,这就会导致会有短暂的空窗期,这期间nginx反向代理找不到目标,九会报502.
解决办法是将数据库、日志等会被操作的文件移除PM2对应的项目目录,确保项目下的文件,在运行期间不会被代码修改。

领域驱动设计实践
何为前端数据治理?
在5年前,我凭借一身胆,硬生生写完一个电子商务微商城,一个订餐系统,一个会议室抢订系统,一个基于ajax的内容管理后台,那时候的前端工具莫过于jQuery和sea.js,但总体而言,这些系统的实现只要耐心和时间都够,也能写出来。但随着时间流逝,我先后进入了国际知名基金评级机构Morningstar和国内社交王国腾讯,逐渐和业务系统打上了深刻的交道。于是慢慢发现,早年自己所完成的引以为傲的作品,实际上没有什么内在的干货,仅仅是可用而已,而谈不上优雅。究其本源,在那个年代,除了前端业界没有特别丰富的工具之外,还有一个重要的原因,即我自身因为经验单薄,对设计模式也好,对业务系统的抽象能力也好,都无法让我站在更高的设计层面去看待所开发的具体业务。
“业务”这个词在我这些年的开发生涯中是一个核心词汇。我从业虽然只有5年,但因为我是硕士毕业,加上本科期间的实习、自己倒腾,我的开发经验也已超过10年光景。这些年中,前期我几乎没有关注“业务”这个词,那个阶段我主要关注“功能”,对照着交互稿或设计稿,根据需求口述实现功能为主。以功能为导向的前端开发和以业务为导向的前端开发是不同的。前者关注快速实现,快速迭代,满足用户需要,提升用户体验,多面向toC产品。而后者关注准确性,稳定性,满足客户需要,保证逻辑没有丝毫差错,多面向toB产品,甚至是内部系统。业务开发也讲究快速迭代,但是和面向C端用户的产品迭代不同,B端产品的迭代之快,恨不得早上的需求中午就要给到。但是,这种极速迭代并不会持续的均匀的散布在开发周期中,很多情况下它是随机的突发的。除了极速迭代,业务开发的另一个特点是多迭代并行,在我自己的经历中,同一时间基本上都有2个以上任务同时进行,只有较少的时间只有1个任务,这种情况下相对比较闲适,会做一些技术建设,而最多情况下,我一周内有4个迭代并行推进,并且在这一周内,发布了3个迭代的成果。
面对业务系统开发的特性,慢慢的,我总结出一些规律。其中包括,“性能并不那么重要”“准确性高于一切”“功能可以先上,后续再优化”等等一系列在其他领域开发中,令人不可思议的违背“常理”的规律。
真的违背常理吗?其实并不是,面对围绕“业务”进行开发的系统,很多在C端大众性产品中看似成熟的经验,现在或许不适用,或者并不那么急迫。例如,大众性产品强调“秒开”这种体验,虽说在业务性产品中做到这一点是很不错,但是如果实在做不到,只要保证数据准确,业务逻辑准确,慢一点点也并无大碍。再例如,某些产品会遇到流量喷发,比如双十一这种场景,但是在业务性系统中,这种场景也基本不会遇到,虽说在某些时刻确实也会给服务器带来一些压力,比如周一业务方要开会,业务团队成员着急录入数据时,会有一小段时间的流量高峰,但这种压力基本上不足以摧毁系统。只有当业务系统需要对接业务团队外部人员时,才需要提供一个能够承受特大流量的服务,但实际上,这种场景,相当于在业务系统的基础上,部署一个大众性产品服务,也就是基于B端产品的C端产品,所以,理念上已经横跨了两个领域,不能因此而否定前面对B端产品的结论。
“业务“不是一个简单的词汇
如果你长时间在开发针对大众的C端产品,你可能对“业务”这个词不是很理解。不过,我举一些例子你就能明白。DNSPod是腾讯云旗下的一款DNS服务产品,最初,它围绕DNS这个业务,完成前后端的一系列技术建设,以支持业务的稳定可靠,从而才能实现最终的商业价值,如今已经在业务层面全面铺开,你或许可以猜一猜现在DNSPod为腾讯云带来多少收入?CODING是国内一家知名的围绕研发生命周期管理为业务的产品,它需要涉及开发体验、效能、管理、安全等等方面的技术,而围绕这一业务出发,它需要不断探索和优化产品内的细节,现在,它已经被腾讯收购,成为一站式软件研发管理业务的赢家。
如果非要再直白一点区分业务型产品和功能型产品,我认为可以这么解释,前者是持续合作的企业级产品,后者是一锤子买卖的普众型产品。虽然两者都能赚钱,但是赚钱方式不同,前者是跪着喊客户爸爸,然后挣很多钱;后者是利用自己的资源、体验吸引用户使用,然后搞各种增值服务策略,想方设法让用户掏钱,而且单价不会很高。前者开张吃三年,吃完三年又三年;后者靠走量一波达到巅峰,然后结束找下一波,只有形成垄断的巨头可以在部分产品上持续盈利。2018年开始,腾讯全面拥抱B端G端客户,并且随后小马哥提出“产业互联网”概念,2019年,腾讯云收入过百亿,我也领到了刻有腾讯云百亿纪念文字的纪念手机。

业务型产品的盈利能力和C端产品孰高孰低,在产业互联网时代尚无定论,但不可否认,业务型产品的潜力已经完全暴露,入场B端产品的企业越来越多,在2019年之前,字节跳动以今日头条、抖音、懂车帝等大众消费型产品崛起,在2020年,飞书趁疫情期间远程办公和协同工作需求的增加,也快速崛起,和阿里钉钉、腾讯企业微信形成新的鼎立之势。
以上这些,是我在长时间和“业务”开发打交道过程中的体会。也是我打算写一系列文章来探讨有关前端数据治理的动因。
业务准确性和数据
虽然在前文我没有提到“数据治理”这个词,但是我反复强调“准确性”,实际上,这个词是关键,是迫使我思考前端数据治理的核心原因。但是,在开始探讨前端数据治理的内容之前,我必须将为什么要去探讨前端数据治理的现实原因讲清楚。正是因为业务开发的特性,让我们不得不更多的思考数据,特别是前端这个弱环境(动态赋值、弱类型、对象引用、自动垃圾回收等)下,怎么确保“准确性”。
我刚开始进入Morningstar进行业务系统开发的时候,仍然以功能开发的思维开始上手,结果碰了一鼻子灰。首先,不懂业务场景,会对为什么要把数据设计成这种结构产生疑惑,觉得不符合道理,既不利于前端读取,也不利于http传输,用户体验太不好了。
// 某接口吐出的数据形式
{
data: [
{ key: 'some', value: 1111 },
{ key: 'another', value: 222 },
]
}我想象中的合理的数据格式应该是这样:
{
data: {
some: 1111,
another: 222,
}
}多么精简干净舒服且爽。
但是实际上,在业务系统中,一个数据集合除了要知道数据的值以外,还需要知道其他元数据。我再仔细去看接口吐出的其他信息,其实可能还会包含如下信息:
{
data: [
{
key: 'some',
value: 1111,
data_type: 'int', // 数据本身的类型
display_formatter: '2f', // 数据在当前接口用来展示的类型,表示展示的时候要体现2位小数
}
]
}业务场景的不同,会使得数据的使用不同。如果我们以固有的思维去质疑具体的业务逻辑,就会发现自己年轻莽撞且自以为是。
对于业务开发而言,比实现功能更重要的,是描述业务本身,而且必须是准确描述。所以很多业务系统都不约而同的选择用Java或C#来开发,除了.Net平台限制外,重要的原因在于通过语言特定的面向对象编程特性和比较强的类型系统,来确保对业务描述的准确。在开始功能开发之前,我们需要建立一套准确的领域模型,将属性、操作、事件抽象为独立统一体,这样才能保证程序员首先对业务有一定的理解和认知,然后才是业务流程、功能、交互的开发。
既然提到交互,那么我们来看一个具体的例子。
在涉及金融相关的系统中,有一个切换币种的交互。用户点击某个切换图标,会弹出一个模态框,用以让用户选择将要切换到哪一种币种,用户点击对应的币种后,模态框关闭。然而,实际上,这里交互虽然结束了,但是业务逻辑并未就此打住。一旦币种切换,那么意味着业务对象的其他字段信息需要全部重新按新币种计算。假如用户账户上有500万USD,切换为CNY之后,账户上的钱如果需要换算过来,那么需要通过汇率计算得到新的数额。汇率是取实时的汇率呢?还是通过定时任务拉取到自己的库中暂存呢?另外,由于浮点数计算问题,会导致先从USD切换到CNY,在切换回来,反复几次,会不会出现原来的500万,结果变成了499.99万?钱去了哪里?所以,看上去是一个切换币种的问题,实际上,它背后是一整套金融换算和数据管理的问题。
前端数据治理
我们做前端开发,虽然可能不会涉及到上述的后端数据管理问题,但是在前端,仍然面临复杂的业务数据管理问题。由于前端的数据不会自动产生,而是需要从服务器端拉取,所以,本质上,前端的数据全部是运行时的,虽然前端也可以采用一些持久化技术实现数据存储,例如我之前全面介绍过的IndexedDB,但是总体而言,前端仍然是在动态地使用内存即时的消费来自其他来源的数据,就像RAM和ROM,前端数据对应的就是RAM。
前端消费数据的方式千变万化,以我们熟悉的React为例,我们从后端拉取的数据,往往需要转化为组件或应用的state,再由React消费state,完成界面渲染和更新。也就是说,React消费的数据,已经是二手货,甚至好几手后面的,在层层传透过程中,出错在所难免,如果不建立一套确保数据准确性一致性的机制,很难让业务方放心把前端工作交给开发团队。
反例比比皆是,在手机端,用户从一个列表进入一个详情界面,进行一些更新操作,随着业务流转,新的数据被请求下来,并更新了当前这个详情界面。用户从这个详情界面返回到上一页,也就是列表界面,却发现,列表界面代表刚才修改的业务对象下方的一排小字内的数据并没有更新。这种场景几乎每个开发团队都遇到过。不同的技术架构里处理这个问题的方法不同,比如通过一个全局事件进行监听,当内部详情页发生变化时,列表页也要重新请求一次接口,以刷新页面。又或者,直接将列表页的对象和详情页的对象绑定,修改详情页对象就会同时修改列表页对象。等等,实现的方式各有各的不同。这是我们在功能开发中的惯用思维。
除了由于前端弱环境带来的语言层面的问题,由于业务需求多样性代码的问题也很复杂。同一个业务,在不同条件下的逻辑可能却不同。
比如,同一个字段,理论上表达的是同一个东西,但是在A页要展示成四舍五入成整数,而在B页要展示成永远含两位小数。对同一个业务对象的编辑表单中,X这个字段也面临复杂逻辑,当业务刚刚创建好时,你可以随意修改X字段的值,而且它是可选的,可填可不填;但是当业务经过一轮审批之后,X字段变成必填;而等到业务完成审批之后,X字段变成不可修改(其他字段可以修改)但要展示出来给人看。如果按照功能开发的思想处理这些问题,我们要写很难维护的判断逻辑来处理这些问题,稍有疏忽,就会出差错。
前端数据的即时性、流动性、多态性,特别是在业务系统中既要求准确,又要求适应多变的需求,单纯靠数据管理是无法完成的。数据治理是数据管理的高级阶段。从程度上讲,数据管理是从杂乱无章到有章可循,是方法论上的提升,我之前写过一篇《前端状态管理设计——优雅与妥协的艺术》专门探讨过前端状态管理的问题。而数据治理是从可用到有用的升华,是价值观的质变。一个业务,从原来乱七八糟,到使用状态管理器集中统一管理,调试和变化都可以顺藤摸瓜找到数据变化的顺序,这是数据管理的效果。而从这种“基本满足”的状态,上升到“有条不紊,万变不离其宗”,不管React层面怎么写,业务对象的内在关联永远保持,无论运行时状态怎么变化流动,都遵循着业务的逻辑描述,从数据的产生到消亡,都在按照某种约束运行而不会超出这个范围,同时数据质量、数据安全也因这种约束得以保障,即时出错,也有明确的告警,这就是数据治理。关于这一理念,实际上,我在我的播客节目《Robust:程序员的TALK PLACE》 中也提到过类似的理念。

“数据治理涵盖了从前端业务系统、后端业务数据库再到业务终端的数据分析,从源头到终端再回到源头,形成的一个闭环负反馈系统。“
我提出来“前端数据治理”,是希望站在前端的角度,重新去思考前端在业务开发时所面临的问题,而非纯粹去套数据治理的概念。前端数据治理是一个狭义的概念,它虽然会涉及和后端的交互,但我们不需要侵入后端,也不需要从系统整体层面去设计,我们只需要站在前端本身角度,重新审视功能开发的惯性思维,找到一种适合不同场景下的前端开发心态。
小结
本文从我的个人经历出发,慢慢展开聊到前端在业务系统开发下的特殊性,指出业务开发和功能开发的不同,并且阐述数据是业务“准确性”的核心要素,最后引出前端数据治理的概念。从本质上讲,前端数据治理更多的是有关策略、设计模式层面的问题,而非具体的编程实现问题,所以和我们原有的编程习惯并不冲突,冲突的地方在于思维方式,我们如果领悟到前端在解决业务复杂逻辑中数据保持约束的规律之后,就会发现,我们一贯的编程技巧仍然在具体问题中受用,只是在一开始,我们就会对业务系统中的数据管理采取另一种抽象的处理方式,这种方式可能性能稍差,却是我们保障业务准确性的重要一步。
前端数据治理之“元数据”
“前端数据治理“这个知乎栏目,我打算从另一个纬度去讨论前端应用开发。这个栏目的核心话题都是围绕“业务”这个词。之所以要再强调,是因为有少数朋友在阅读时,思路会跑偏,用非本栏目讨论范围内的内容进行无意义的互怼,我觉得没有必要。任何阅读和讨论,一定需要一个前置条件,本栏目的前置条件就是“业务型应用开发“。在这类场景中,由于业务本身的流转逻辑复杂,流转过程中不同的对象状态变化相互之间还存在关联性,所以开发过程中往往比较痛苦,这也是我开这个栏目,梳理这些开发问题,以帮助需要相关思路的开发者获得参考的初衷。
本文主要讨论“元数据”这个话题。“元数据”的简单定义就是“关于数据的数据”,直白的说,就是关于值本身的描述的集合。对应到开发中,就是表结构,我们在设计数据库表时,需要对每个字段的类型、长度、默认值等进行规定,这些内容,就是关于这个字段的值的元数据。
和后端开发不同,前端是面向交互编程,因此,和后端相比,前端建模更多是为了给视图交互服务。
现在,我们进入到具体的场景进行“元数据”的讨论。我们现在有一个简单的商城系统,商城系统的核心对象有三个:消费者(用户)、商品、订单。围绕这三个核心对象,商城的整套业务流转在运行。现在,我们要为商品建模了,我们来想一想,在那些业务环节(交互过程中)会需要商品?
- 商品的上架(一个提交表单)
- 商品信息的修改(一个修改表单)
- 商品的展示(商品详情页)
- 商品的引用(下单过程中,订单拉取商品部分信息进行展示或计算)
有人会说,用户已购买的商品也是,但我想说,用户已购买的商品和我们这里的核心对象商品是不同的,用户已购买的商品属于订单的子对象,用户下单买完之后,订单当时商品的信息是固定到订单信息中,相当于对商品对象进行了主要信息的克隆,和这里的核心对象商品已经脱钩了。
综合上面的这些情况,实际上,我们面临的交互主要有两个:1)表单 2)展示。
在考虑设计“商品”这个对象的元数据时,我们要分开上面两种场景进行设计。当然,对于我而言,我虽然是从两种场景去设计,但是我在模型中将所有的元数据集中在一起,在两种场景下都可以使用该模型。
接下来,我们来看商品价格这个字段。
我们先考虑展示的时候这个字段要准备哪些可能需要的东西:
- 样式类:字体大小、颜色等
- 值类:保留多少位小数,前面是否加¥等货币符号
- 名类:“价格”这个词,是否需要区分当前系统是中文和英文
- 格式类:是否需要千分位分隔符,或者根据用户所在国家进行数字格式化
你看,我们一下子就让价格这个字段丰富起来了。上面这些都是我能想到的,但不一定全。不同的电商系统中,这些东西估计都是需要的,所以,实际上,我们已经总结出“价格”这个字段的通用“元数据”了。
那么,具体在编程上怎么去实现呢?我在 tyshemo 中定义了 Meta 类,该类其实是一个抽象类,用于定义元数据。现在,我们尝试定义一下价格这个字段:
import { Meta } from 'tyshemo'
class Price extends Meta {
static name_zh = '价格'
static name_en = 'Price'
static font_size = 18
static font_color = '#660000'
static formatter = pipe(
thousands, // 千分位分隔符
fixed(2), // 保留两位小数
currency, // 我自己写了一个currency函数来自动添加货币符号
)
}你看,我们已经定义了 Price 的不少元数据了。
接下来,我们来看看表单中的情况。表单,我一直一来都认为是前端开发中,最复杂的场景之一,因为它要处理的东西实在有点多。不过对于价格这个字段,我们感知上应该还好,不会有特别复杂的逻辑。
- 是否必填?
- 是否只读?(某些情况下,一经发布,不允许修改商品价格)
- 是否隐藏?
- 是否禁用?
- 提交到后端时是 price 字段,还是 good_price 字段?
- 最大值/最小值?
- 用户填写的时候是否需要千分位格式化?(这个就有点难度了)
- 真实值和用户看到的值是否一致(是否需要省略小数部分)?
- 校验逻辑?(这个应该是表单标配)
你看,Price 瞬间就又复杂了很多不是吗?这些都不是全部的,我只把自己所能想到的都列了出来。现在看看代码实现:
import { Meta, Validator } from 'tyshemo'
const { max, min, required } = Validator
class Price extends Meta {
static required = true
static readonly = function() {
return this.is_expired // 模型上的 is_expired 字段为 true 时,价格只读,不能被修改
}
static setter = v => v === '' ? 0 : +v
static getter = v => v === 0 ? '' : v + '' // 当价格为 0 时,输入框为空
static validators = [
required('价格必须填写'),
min(0), // 不能小于 0
max(9999999),
]
static to = 'good_price' // 传给后端时使用 good_price 字段
static is_need_thousands = true // 给一个标记,由视图层处理交互逻辑
}表单中可能还会有其他的一些限制,总之,我们尽可能覆盖到各种场景,并在 Meta 中提前定义好这些元数据。当然,有的时候,在元数据中,有些定义是比较抽象的,比如上面的 is_need_thousands 这个属性,如果单纯看它,从字面意思确实可以理解,意思是需要千分位分隔符,但是问题在于,具体怎么实现呢?所以,这里就比较抽象,它实际上是前端约定好的一套交互协议,如果 meta 中 is_need_thousands 为 true,那么我们在前端视图层实现时,就会采用一个特殊的数字输入框组件,这个组件自带了方便的千分位分隔符能力。但是,对于非前端人员,阅读到这里,就会存在一定的理解障碍。这也是属于前端私有的领地。
另外,我们可能还会在元数据中定义一些其他的属性:
- 数据类型是什么?
- 后台接口中,如何获取 price 字段的值?是直接读 data.price 还是读 data.good_price?
- 在什么情况下不需要上传这个字段?
- 当这个字段的值发生变化时,是否需要执行某个函数?
这些属性的定义,都可以通过 tyshemo 这套系统来实现。
我们回到元数据这个话题。我在读大学的时候,我们管理学领域有一门分支学科,叫“信息资源管理”,里面提到一个论点,“管理要超前到信息产生之前“,也就是说对信息的管理,要在信息产生之前就进行,这叫“超前管理”。怎么做到超前管理呢?就是事先定义好元数据系统。当然,真正的工作并非那么简单,但是,从中可以看到,元数据是保证我们业务逻辑按照我们预先设计的规则进行的。
最近接到一个新的需求,我们要统一规划系统中所有字段的基本逻辑,包括所有字段的中英文、展示格式(一个字段可能多套)、校验规则等。这是一个复杂的需求,最理想的状态是做成一套线上系统,有点像 Headless CMS,可以自己对字段进行自定义。这个需求本身是复杂的,但我们单纯从前端角度来看,这个需求实际上可以为前端提供丰富的元数据,一旦这些规则都是定义好的,我们就可以通过一种协议,从后端拉取有关这个字段的元数据,获得该字段的所有规则,这有助于我们统一化前端字段的展示和编辑逻辑,完成之后,前端不需要自己再手写各种各样的校验逻辑,不需要再用像素眼盯着屏幕检查是否按照设计要求展示字体、颜色,有了这套系统,前端实际上代码量会下降一个量级(当然,实际上,复杂度提升了很多,对于那些反复强调“到时候新人看不懂”的团队,不适合拥有这类系统)。
什么是业务逻辑?
我写《前端数据治理之道》围绕一个中心词汇:业务。但我在一些文章的评论中收到“业务交给后端去处理,前端做展示就好了”类似如此的思想。这类思想我个人的理解,更多是站在后端开发者的角度看问题,因此,我打算写一篇文章,专门讨论什么是业务逻辑。
很明显,在部分场景下,前端是不可能只做展示的,随着B端、G端产品的强势,这种“前端只做展示”的应用架构已经不符合需求了。我观察到,业务在开发层面有两种存在形式:数据的业务,人机交互的业务。站在后端开发的角度,只看到第一种,但在实际开发中,前端开发需要兼顾两种业务,而且,很大程度上后一种需要以前一种为基础。
数据的业务由持久化数据和逻辑代码构成,基于这两个基础,可能还需要搭配各种系统来实现,例如需要消息通知系统来在每一个业务节点上推送催办消息给特定用户,例如需要利用定时任务系统来拉取第三方数据,例如需要队列服务来解决长串任务堆叠。总之,我们传统的后端系统基本上只关注这一层面的业务。
在前端,基于数据的业务也同样存在,举个例子,我们做了一套数据视图系统,对于用户而言,他们可以通过挑选几个字段的所有数据进行统计,并为了研究不同因子变化带来的结果变化,直接修改某些值来进行计算结果。很显然,这里用户进行的这些操作不会对线上数据库产生任何影响,因此也就不需要向后端提交数据。这些数据被存在客户端内存中,一旦用户离开这个界面,这些临时数据就可以销毁。如果按传统做法,前端必须将一大堆数据post到后端接口,由接口返回计算结果,然后再由前端来渲染。但是很明显,相同的计算在前后端执行得到的结果是一样的,而传统方式还要付出网络交互和前后端耦合的代价,而这类计算仅仅当前这个用户用到一次,不需要持久化,交给后端处理,还要让后端考虑性能、并发等风险。可见,这一业务虽然是数据业务,却可以在前端完成。
交互的业务是本专栏要关注的重点。人机交互大发展是当代计算机系统发展的重要一面,如果只重视数据业务而不关注人机交互,那么丑陋的命令行模式就可以完成大部分计算任务。但是如所有人所见,如今的业务系统需要用户在一个界面,结合界面上呈现的多维信息,完成不止一个操作。而且为了提升用户体验,产品设计人员想尽一切办法,让用户明晰每一个操作的作用,避免做了错误操作。现代应用的交互复杂度,以及交互后面所蕴含的业务逻辑,有时,让人望而生畏。
业务的逻辑,表面上可以用一大堆if…else来概括,但实际上除了判断之外,它还可能涉及形式。
很多人对“形式”这个词不敏感,但如果你研究过形而上学或符号学,就会不再那么轻松。形式在交互中极为重要,我们用一个具体的场景来解释。
现在有一个表单,里面有一个输入框,该输入框对应的字段,需要关联到系统中已有的某个对象,但也有可能用户不选择关联,使用输入的值作为结果。而如何用户选择使用输入的值作为结果,那么就有可能输入一个系统中已经存在的对象,而该字段的规则是不允许系统中有重复值。在这个场景中,是暂时没有数据参与的,也就是说,它的整个业务必须依靠前端来实现。
除了单点的复杂交互业务之外,还有连续的流程交互业务。以一个审批流为例,一个审批单发起、审批A、审批B、结项,这个流程环节必须走。暂不考虑流程分支流问题,后端自有后端的方式交互这一审批流管理起来,现在我要问的是,前端做了什么来合理管理流程业务?是只展示后端输出的内容,还是自己构建了一套流程模型?
现在我们再来看看什么是业务逻辑。
实际上,我们口口声声的业务逻辑,是只用代码实现的真实业务的规则映射。注意“规则”这个词,简单说,一个业务中,存在什么逻辑,可以通过在纸上画出不同业务对象之间的联系和约束,并将这些联系和约束一条条列出来,形成一个列表,而这列表中的每一条,就是一条规则,这些规则的总和,就是这个业务的业务逻辑,而且是全部业务逻辑,你不能再多列出一条了。
既然是一条条的规则,那么我们就可以在代码层面对规则进行管理。对于前端开发者来说,最熟悉的规则管理,莫过于路由管理。现在,我们做一个思想实验,将每一个route对应一条业务规则,每一个url对应某一时刻后端接口输出的业务数据,随着后端接口业务数据的变化,不同的业务规则会被使用,而没有匹配到的规则会被屏蔽,从而,在界面上呈现出根据业务逻辑而提供对应的人机交互的效果。
由于规则是有限的,我们可以借鉴有限状态机的开发范式来实现对业务逻辑的开发。有限状态机,很好的为我们提供了在不同规则之间转换的一种思路。当业务从一个状态切换到另一个状态时,可以很清晰的获取当前状态,以及下一步我可以做什么。业务切换也是这样,我们明确当前可以做什么,也知道下一步可以做什么,到具体要做什么,要看用户做了什么操作。
但和有限状态机不同,业务流转并不是状态切换,每一次流转,都可能牵涉一堆东西,例如从一个阶段进入下一个阶段,参与业务的业务对象变了,我讲过,业务流程是实体的进出和状态变化的总和,所以单纯靠有限状态机是解决不了的,但我们可以借鉴状态机切换状态的这个切换编程模式。
由于我并没有将所描述的这套东西实现成框架或库,所以无法再具体到细节处。
最后,前端处理业务逻辑不仅不是多余,而是当下复杂应用的趋势和要求。目前而言,前端领域还没有强大的针对这个领域的库或框架,因此,需要我们积极探索,重拾软件设计的技术体系,寻找更多可能性。
前端数据源治理
在我看来,前端数据问题分3个层次,分别是:
- 原始数据请求
- 数据请求抽象
- 数据源管理抽象
我们通过Restful API也好,websocket也好,或者本地缓存也好,都可以获得一些数据。但这些数据的获取和使用,如何在项目中具有更优雅的设计,至今我还没有看到满意的答案。我在《漫谈前端数据层》一文中提出,可以在前端借鉴数据仓库的概念,设计可以从我们常见的react数据请求编码方式中解脱出来的方案。不过在那篇文章中,对获取数据的这个环节的思考并不非常成熟。这篇文章表达我经过思考后,对这一问题的最终解答。
我们常见的做法,有两种,一种比较原始,直接在react组件中使用axios等库发出请求,请求回来后通过setState把数据拿来使用。另一种结合状态管理器,在独立的模块文件中,把相关的接口全部集中起来,形成一堆基于axios的async函数,并在状态管理器中调用这些函数,用到thunk、saga之类的工具来实现状态异步更新。这两种方式在我看来,都是原始方案。
所谓“原始”,就是直接按照ajax请求的思维,把最底层的xhr通过一层封装暴露出来,在使用时,需要遵循axios等库的细节,思维层面仍然是发出xhr之后等待接口返回结果的思维。它的问题在于,它只解决了ajax请求本身的问题,而如果你需要对数据进行处理、检查,或者对数据有什么要求,就需要自己解决。而之所以说“原始”,就是因为解决这些数据问题,都是散落在各个组件内,或者集中在一个文件的async函数内,每个地方都有类似的痕迹。而使用的人在通过浏览器devtool看数据时,并不清楚你真实处理成了什么数据。总而言之,原始数据请求的方式,就是看上去好像有封装,本质上和最早写xhr没有本质区别。
往上一层,我们要屏蔽这种底层的xhr编程方式。也就是我们要抽象数据请求本身。这听起来比较绕,但你一开始可以理解为,我们要做一层封装,把xhr的那种请求方式隐藏起来,让我们像做某种无感知的操作一样。我写了一个库专门做这一层,你可以了解一下我发明的这套ScopedRequestLanguage。它的核心思想是“把请求进行描述”。当你看到“描述”这个词的时候,你往往就会把它和“抽象”联系在一起。描述的内容总是静态的,但是基于这些静态的东西,我们却可以一眼了解关于该请求的细节,甚至在脑海中勾勒出一个场景发生时,具体将会出现什么状况。
我们用一个例子来解释。现在,我有这样一段描述:
GET "/api/xxx" -> {
name: string;
price: number;
total: number;
}你看,这段描述你是可以读懂的吧,我想但凡做过web开发的前后端程序员都能读懂这段代码。它是讲“你用一个GET请求/api/xxx接口时,将会得到一个含有name, price, total字段的数据对象“。我们基于描述来执行请求,演示代码如下:
const data = await requester.run(`
// 上面的描述文本
`)我们通过抽象请求本身,把请求转化为描述文本,进而实现屏蔽底层xhr请求的林林总总。而描述的作用就非常多,除了能够准确的获得需要的数据之外,它还可以被转化为用以检测后端接口是否按照既定规则给数据的检查器,也可以在前后端同学之间共同阅读,从而建立起更好的沟通模式。
虽然通过描述我们屏蔽了底层发出请求的细节,然而,这远远不够,因为它在屏蔽底层细节的时候,并没有屏蔽数据请求这个过程。
再往上一层,我们要屏蔽数据请求过程本身。我们要抽象的,是数据源本身。前端消费数据,虽然大部分来自Restfull API,但时常也需要从localStorage等其他地方拉取数据。单从从API请求数据而言,我们仍然需要谨慎的理解,“数据是不是还在请求?”,“数据回来了吗?”,“后端是不是出问题了?”等等类似的问题。我们要做的,就是屏蔽这些问题。
我们把数据源进行抽象后,对于数据的消费者,也就是业务代码的撰写者,思维上是消费数据,而不是请求数据。两个字的差别,就是一次思维上的飞跃。我们把数据源抽象为一个看不到内部细节的球,现在,我们要消费数据,于是我们向球说“我要你的数据”,于是它就把数据给你了。至于它的数据来自哪里,你并不需要关心,它向你屏蔽了数据请求的细节。
我们还是用代码来举例,假如我们现在有一个数据源叫做ProjectDataSource ,现在我们要消费这个数据源的数据,我们只需要:
const data = dataRepo.get(ProjectDataSource)此时,你得到的data就是你需要的数据。你可能会想“咦,我没看到你请求数据呀?你这个数据准不准确哦?”。这是你在用上一层的思维思考问题。你现在需要升级你的思维,你不要关心数据源内部的数据是怎么来的,就是是上帝说要有数据然后就凭空出现了数据,你也不要关心。你要关心的是,它给的数据,是否是按照我们的约定来给的,此时,你需要用上typescript。
const data: IProjectData = ...也就是说,对于你来说,只要它给你的数据符合你对数据类型的要求,那么你管他数据是哪里来的,你就认为这数据是合法的就好了,至于数据的准确性,你需要交给提供数据源的抽象引擎来做。这个抽象引擎解决你所考虑的所有问题。而你只需要消费这个数据即可。
好了,现在,让我们进入到球的内部,看看球里面到底发生着什么。
一个数据源的建立,最底层,还是要走ajax那一套,只是说,我们这些底层的东西,被提前封印在球内了。球内代码大致如下:
const defaultValue: IProjectData = { ... }
const ProjectDataSource = dataRepo.source(async () => {
const data: IProjectData = await requester.run(`
// 上面的描述文本
`)
return data
}, defaultValue)我们用上了第二层的抽象。但是它只负责请求的部分,而构成数据源的,除了请求,实际上还可以加入其他很多东西,例如缓存,你可以在第一个函数中加入一些缓存的逻辑,你也可以在这里对数据进行检查和提示。同时,它的第二个参数是默认值,就像 [state, setState] = useState(0) 在默认状态时为0一样,这个默认值保证了数据源在没有发出请求时,也是可用的,不会对界面造成破坏。
我在几年前写了一个叫databaxe的库,专门去做类似的数据源管理,前年在思考了很久之后,写了一个叫algeb的库,借鉴hooks的思维重新整理了这一整套数据源管理的逻辑。你可以通过这个库的思想,去窥探这一层次的内容。数据请求和数据管理是两码事,你一定要把他们分开,在你的项目中,应该更看重数据管理,因为数据管理的方式会通过抽象,屏蔽它底层的请求细节,让你的开发,具有“将不同的对象串联起来“的特征。
这就是我关于前端数据源的一些思考。当然,其实还有一点比较重要,就是你需要把3层的东西,结合到你的项目中去使用,而不是独立于你项目之外运行。我在我们项目中深度实践了这种抽象和整合,你可以关注本专栏,或者我的微信wwwtangshuangnet,通过我后续的文章了解相关的内容。
-
algeb的链接错了#1313 1 2024-04-23 11:51
-
已更正,谢谢指出#1314 回复给#1313 否子戈 2024-04-23 16:45

