Angular怎么实现依赖注入自动实例化的?
Nautil是基于react的完备的前端开发框架
完备前端开发框架需要具备啥呢?我想了很久,最终觉得,主要要满足如下条件:
- 模型系统
- 控制器系统
- 视图系统
虽然是传统的MVC结构,但是在这些年的前端框架发展过程中,没有发展出真正的MVC框架。为什么会这样呢?主要的原因是,前端框架只要解决好视图编程,就已经足够解决日常开发中的大部分问题。所以,jquery, react, vue都被称为是框架,它们提供了一种视图渲染的方式。但是,这些框架,本质上还是解决视图渲染问题,而没有解决数据的抽象(也就是数据模型),数据如何映射到视图,数据的变动映射到具体的行为,以及它们之间的联系,这一完整的链条。现有的所有前端框架,都没有实现这一完整逻辑。而我自己想要实现这一逻辑,以在复杂的2B型系统中,可以构建完整的开发逻辑。而Nautil实现了这一完整逻辑,虽然目前支持的还不够完整,我还在慢慢打磨它。接下来,我举个例子,以及用一些伪代码来描述,这里所谓的MVC架构,和现在市面上的前端框架到底有啥区别。
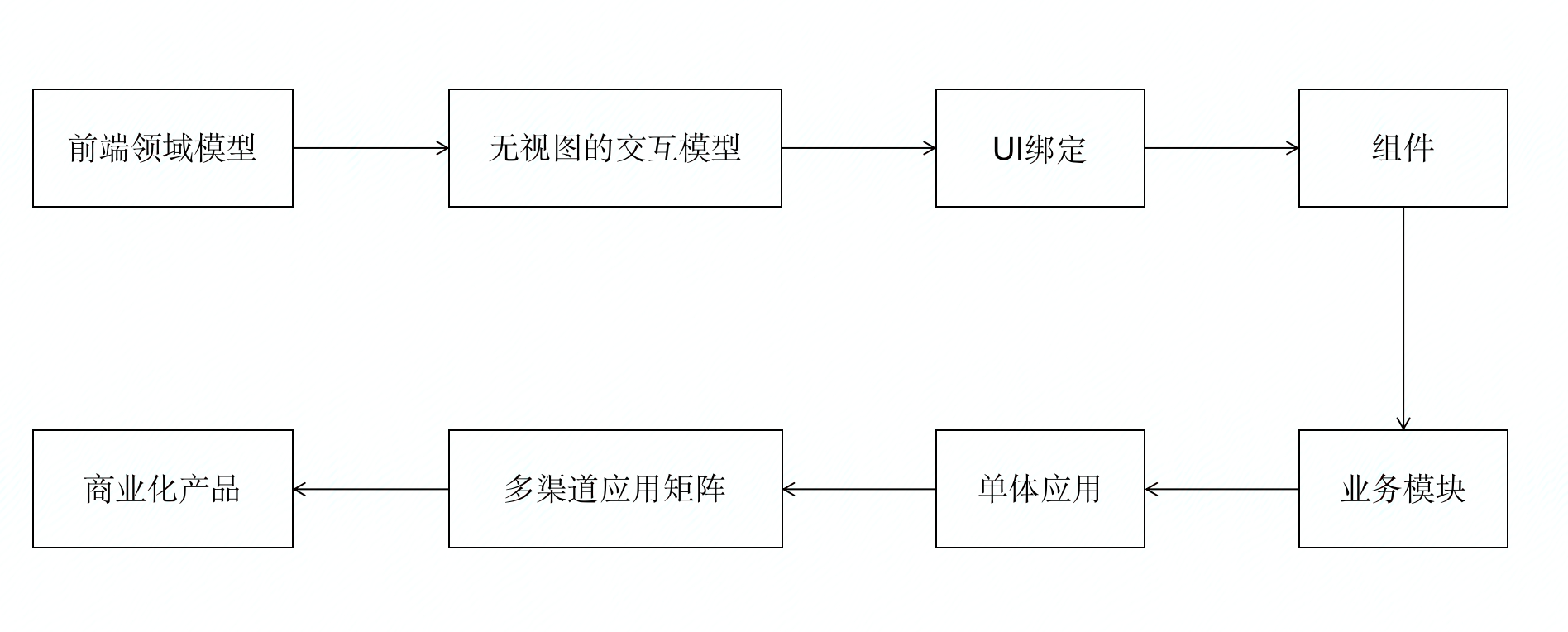
我在腾讯内总结的一套前端演进模式,对于应用团队而言,他们需要按照这个步骤,不断更迭自己的项目最终达到一个最大化效益的效果
首先看下“前端领域模型”。
在我的博客中,你可能已经了解过相关的内容,如果没有读过相关文章,可以通过我博客上方的搜索功能搜索一下。简单的说,在前端去构建一套有关前端如何使用业务对象所抽象的领域模型的一套实践。比如,你的主要业务是物流,那么就一定会涉及一个物流单,而这个物流单,会由寄件人、收件人、货物、保险、托运机构等等信息,整个业务还涉及支付、配送人等等。而由于这些所有信息,都不是确定的,需要通过系统进行填写补充。而这些动态的数据,字段与字段之间有一定的联系,字段本身还有一些规则(元数据),这些约束条件保证要处理的数据不是随随便便的,系统必须是在具有明确逻辑的数据流转下运行,而不是乱七八糟的数据。用以完成这种约束的,就是前端的领域模型,领域模型保证了系统中,数据的一致性和合理性。怎么建领域模型呢?其实很简单,主要要解决的,是一个业务对象所拥有的字段的元数据,以及可能存在的字段与字段之间的逻辑关系。例如我们这样定义货物这个对象:
class Kind extends Meta {
static default = 'life'
// 规定了type字段的类型,只能从这几个值中选择一个
static type = new Enum(['life', 'study', 'traffic', 'office'])
}
class Cost extends Meta {
static default = 0
static type = Number
}
class GoodModel extends Model {
static kind = Kind
static cost = Cost
}
这里定义了一个有关货物的模型,它由kind和cost两个字段组成。其中,规定kind字段必须是一组值中的一个,而cost字段必须是一个数值。
接下来看看“无视图的交互模型”。
在进入视图编程之前,我们要搞清楚,产品经理给的需求中,哪些是属于业务的交互逻辑,哪些是属于视图的交互逻辑。比如,一个按钮,点击之后,要将物流信息流转到下一个阶段,这是业务交互逻辑。一个按钮,点击时弹出一个窗口,询问用户要不要进入下一阶段,这是视图交互逻辑。但是很明显,这个业务逻辑是依托在交互逻辑上的,也就是说,只有完成这个交互,才能完成这个业务。
那这里就有一个问题,在产品经理提出这个需求时,他并不基于前端所使用的技术,因此,也不会考虑说,这效果是基于react的,还是基于vue的。我们有没有一种办法,可以在没有视图(框架)的前提下,对需求提出的交互,以及交互所连带的业务,做模型化编程?我们来看看我下面的这段代码:
class TransferController extends Controller {
static good = GoodModel // 使用到Good这个模型
CostInput(props) {
return [
'input',
{
...props,
type: 'number',
value: this.good.cost,
onChange: (e) => { this.good.cost = e.target.value },
},
]
}
}
这个控制器是对货物一些列逻辑的控制,它基于Good模型,并输出一个CostInput接口,这个接口是一个对交互的描述,它只描述了输出一个什么类型的组件,其属性有哪些。至于这个接口,将会被怎么渲染,则是视图层编程要做的事。
再看看“UI绑定”。
得到无视图交互模型实例之后,利用交互模型的接口,就可以完成对应的渲染,渲染过程,也就是UI绑定过程,通过react或vue进行绑定,比如上面我们创建的CostInput这个接口,我们用react来进行渲染:
class OrderView extends Component {
controller = new TransferController()
render() {
const { CostInput } = this.controller
return (
<div>
...
<CostInput className="form-item" />
...
</div>
)
}
}
在react组件中,我们通过某种处理,可以直接如上使用这个被输出的接口(组件)。而这个组件的业务和交互逻辑已经在controller中绑定了,在组件中,仅仅是为了实现视图层绑定(例如样式绑定)。
之后就是“组件”了。
在组件层面,我们需要完成和视图相关的交互逻辑,比如,我们要在打开一个弹窗之后,用户点击确定,才能能完成流转这个过程,其中的打开弹窗,点击确认这个过程,属于视图交互过程,在react组件中完成编程,而流转过程,我们已经在controller中定义完了。
组件之上的“业务模块”和“单体应用”,就是我们熟悉的react应用开发,这里就不赘述了。
接下来看看“多渠道应用矩阵”。
所谓多渠道,是指分发目标的多。比如,你有一个新闻网站,用户多起来了,又做了一个同名的APP。实际上,这个网站和APP,甚至直接将APP代码转化为微信小程序,这些渠道都是同一个应用的不同渠道。它们或许在某些方面有其独特的地方,比如说有些功能网站有APP没有,有些功能只有APP有。但是,本质上,它们是一个系统的多面,是为达到同一个业务目标完成的一系列布局,它们在业务上,为同一个目标服务,但是,它们在形式上,载体上,都不同,因此,称它们为“应用矩阵”。
最后看看“商业化产品”。
你可能非常熟悉Vue、React,同时,你也可能很熟悉AntDesign、ElementUI,还有,你还可能知道MySQL、Docker等。你一定听说过,一个免费产品背后,有一个付费版本的概念。没有错,商业化产品的目标,就是赚钱。一旦你要为商业化服务,那么你的应用形态就需要适应更加丰富的需求。比如我在腾讯内部,我们自己团队的应用一开始只服务与内部和合作厂商内部,后来,产品不错,就上腾讯云开卖了。另外,一些G类机构,还要求自己私有化部署。总而言之,言而总之,商业化产品要求你的应用架构可以做到无孔不入,不要上来你给我说“这个做不到”“那个做不了”,我只要通过把这个应用按照客户要求提供,躺着赚钱就行。这就是商业化。
通过这些思考,你可能会慢慢领悟,为什么前端现有的各种框架,都不是我想要的框架。这也是我做Nautil的核心价值。
ES查询相关知识

https://www.elastic.co/guide/en/elasticsearch/reference/7.x/index.html
https跨域net::ERR_SSL_PROTOCOL_ERROR
跨域跨域……哎!
我从一个https引入了一个http的图片,然后net::ERR_SSL_PROTOCOL_ERROR。我从一个https向一个http发送ajax,然后net::ERR_SSL_PROTOCOL_ERROR。我从一个https向一个https发送ajax,你TM竟然还net::ERR_SSL_PROTOCOL_ERROR。
鬼一样的net::ERR_SSL_PROTOCOL_ERROR是啥意思?劳资google了半天都没发现文档。最后在大佬的提携下,一点点终于搞掂疗。
![]()
https策略非常复杂,一时半会儿也说不清,仅针对我自己的问题。
图片问题,以及https向http ajax问题,是因为 https://blog.chromium.org/2019/10/no-more-mixed-messages-about-https.html ,垃圾 chrome 强制自动升级协议,我谢谢你全家。。。
而https向https ajax还报错问题,是因为我ssl没有正确部署。为什么呢?因为我自己的主域名放在 a.xx.com 下是一个子域名,而该子域名直接使用了 *.xx.com 泛域名证书,所以可以直接访问。但是,我另一个域名是 b.a.xx.com 是一个三级域名,而三级域名没有 *.xx.com 泛域名支持,所以不能https访问。我的大爷,被这个泛域名证书搞懵了,都是同一个证书,搞的我以为见了鬼,二级域名能访问,三级域名不能访问。最终原因是,理论上两个域名都不能https访问,只不过二级域名被强制 *.xx.com 泛域名覆盖了,所以能访问。
最后,把证书部署问题修好,一切OK了。折腾!
-
实习前阵子给人家写http请求相关的部分时候也是遇到这个错,后来发现是http和https,搜解决办法大家说没别的好办法只能统一https,摸不着头脑…… 结果拉着运维忙活了好一阵重新分配域名。#986 朔兔 2020-12-09 10:12
-
这种也不能埋怨说前端基础不好,这是真因为TM难调试啊,没有经验谁知道是在哪个环节有问题#987 回复给#986 否子戈 2020-12-09 10:51
用Proxy拦截class,这种骚操作闻所未闻!
一个突发奇想,如果要拦截class的属性变化,除了用defineProperty进行重写,难道不能用Proxy吗?于是,产生了下面这段代码。
class A {
name = 'aaa'
age = 0
constructor() {
return new Proxy(this, {
get: (_, key) => this[key],
set: (_, key, value) => {
console.log(key, value)
this[key] = value
return true
},
})
}
say() {
console.log(this.name, this.age)
}
update(key, value) {
this[key] = value
}
}
在构造函数中return new Proxy(this)真是够风骚的操作。
-
一般吾辈会用 class static function 或者注解来解决#985 rxliuli 2020-12-01 12:04
等等,这样讨论vue ref-sugar是不讲武德的!
我们讨论ref-sugar本质上在讨论三件事:设计原则,开发体验,实现魔法。
我们现在在该问题上争论,很多人直接从第三点出发,认为实现魔法不好,但实际上,根源在于第一点,vue3发布的ref没有遵循vue原有的设计原则,使得变量的使用在script和template中呈现了两种形态。
export default {
setup() {
const count = ref(0)
const plus = (inc) => count.value += inc // 脚本中使用 count.value
return { count, plus }
}
}
<div>{{ count }}</div> // 模板中使用 count设计原则
Vue的设计原则包含两个基本点:1.通过直接修改状态变量而非调用接口完成响应式,2.接近原始js变量操作而非复杂操作的0成本理解。简单说就是,vue帮你封装好响应式,你只要无脑使用,做到真正0心智模型。但在ref这个点上,0心智失效了,因为我们在脚本中经常忘记.value。
对问题的解决,不能超出设计原则,这是vue所坚守的,超出原则的设计,比如这篇文章,虽然可以解决问题,但是一旦泛滥,那么vue就没啥价值了。
开发体验
在开发体验道路上分出了两条岔路,AoT和Runtime。前者把活交给编译过程,能力实现全靠工具,但是可以随意发明语法,想怎么玩都可以,爽,缺点就是脱离了那套编译工具跑不了,典型就是svelte。后者需要自己写一套基于原始js能力的系统实现效果,提供接口,按照接口文档用就完事了,浏览器里面随便跑,缺点是运行时代码加大,心智负担加剧(要记住用法)。
vue想尽一切办法在两者之间做平衡,几年来,长期坚持能够纯runtime实现,还是干不过js语言本身的限制。所以,新提案ref-sugar妥协了,是纯粹的AoT实现方案。当然,AoT也可以在浏览器端搞编译,就像当年less搞的一样,但很明显,这是歧途,自己在浏览器里面解释执行js是不明智的,太不安全了。
对该方案的喷点,多多少少是由于这个原因。因为如果把解决问题的方法丢给编译器去解决,那还有啥是编译器不能解决的?
所以,能够平息这次风波的根本解决办法,一定是:0心智负担+runtime的方案。连尤大都掉坑的问题,是不是无解了呢?接下来看看实现魔法。
实现魔法
我想,尤大掉坑的根源,可能是对设计原则的误解,认为vue必须是基于单一方案实现响应式,所谓单一方案,就是vue里面只能有数据拦截这一套方案。但是,响应式方案真不止数据拦截这一条路。vue1,2采用了defineProperty方案实现响应式,而vue3采用了Proxy,开发者的心智没有任何负担,反而叫好,这说明,问题的根源不在于实现响应式的内部细节,而在最终表现出来的效果。
所以,为什么vue只能基于单一方案实现响应式?为什么不能同时用两套响应式方案?在ref这个点上,脏检查机制就是一个赠送的方案。(这想法不是我提的)
let a = ref(0, () => a)
function handle() {
a = a + 1
}<div @click="handle">{{ a }}</div>另外,js里面有一些魔法可以用上了,主要是valueOf和Symbol.toPrimitive,这两个属性可以帮助我们完成对象的值运算。我简单举个例子你就能明白其中的道理。
var a = {
value: 1,
valueOf() { return this.value },
}
var b = {
value: 2,
valueOf() { return this.value },
}接下来我们做这个运行:a + b得到的结果是3.我们还可以修改a.value = 2,再执行a + b结果是4. 道理就是这么简单。let a = ref(0, () => a) 中,a的结果是一个如上结构的对象,所以参与运行是OK的,对a.value进行改造,就可以做依赖收集了。比如:
let c = computed(() => a + b)由于上面式子中会调用a.value和b.value,所以可以知道c对a,b有依赖。下面是最关键的:
a = a + 1对a重新赋值,此时a的数据类型发生了变化,从对象变成了数字。但是没有关系,在computed进行依赖收集时,我们已经得到了一个计算公式:
c = (() => a)() + (() => b)()也就是说,无论a, b是什么数据类型,计算后得到的c的结果是确定的。而关键的问题在于,一旦a丢失了object类型,就没有办法依靠vue的响应式设计完成响应式效果。此时,脏检查就来了。
- 用callback包装handle(效果类似computed,主要做依赖收集): handle = callback(() => a = a + 1)
- 执行handle时,a.value被收集,代表handle函数有可能对a产生副作用,每次执行handle,可能收集到的ref变量不同,由if...else决定,根据这个情况,还可以做一些优化
- 当handle被调用结束时,对收集到的所有依赖进行检查,检查依据是上一个值和这一次的() => a结果
- 当发现值不相等时,表示依赖被更新了,此时回溯所有computed,如果发现对a有依赖,那么对应computed属性需要被更新
和angularjs的脏检查不同,因为这里我可以明确知道自己依赖了哪些变量,所以我做的检查范围会小很多。而且由于nextTick机制的存在,脏检查也仅限于数据层面,不会触发DOM的更新。
结束
你看,仅仅给ref加了第二个参数,就可以把这个issue给结了。但是,你可能会说,我() => a真不想写啊!!!要解决这个问题,最好的办法,就是你去做TC39主席,然后强推PrimitiveProxy,并且让Proxy完全适用于PrimitiveProxy,这下世界安静了。
用Algeb这个新轮子管理前端数据请求资源
一个前端项目需要管理一堆前端数据请求,现代前端应用,几乎没见过将数据请求直接写在业务代码中,大部分时候,我们都会将这些请求逻辑从业务代码中抽出来,集中管理。但随着业务开发的反复进行,我们会逐渐发现一些现象,我们对后端吐给我们的数据开始提出一些具体细节上的要求,就我个人而言,我总结出如下要求:
- 如何避免同一个请求被多次发起?
- 如何在某处发起请求,当数据回来后,另外一处使用了该请求数据的组件自动更新?
- 如何在第一次渲染的时候就可以正常渲染?
- 如何提供更优秀的编程体验和管理方式?
我在几年前写过一个库databaxe,提出一种新型的数据源理念,这种理念让我们可以写同步代码,把请求过程和数据进行分离,对前端而言,请求本身是不可见的。前端只需要从仓库中读取数据即可。但当时采用了具名方式规定每一个数据源的名称,获取参数对应关系比较复杂,需要监听,而且内置了axios作为数据请求器,对开发者而言是不开放的。
为了继续实践这种写同步代码的方式,同时使数据请求本身更开放,我写了algeb这个库
它的源码比databaxe少了n倍,使用方法简单了n倍。让我们来看看,我是如何做到的。
数据源
我们大多情况下是通过请求后端API获取数据,但API并不是唯一的数据源,在前端编程中,客户端持久化数据(例如存在indexedDB中的数据),websocket推送的数据,都是重要的数据来源。因此,我们要寻找一种编程方式,可以兼容不同形式的数据源,将不同形式来源的数据,通过一套方式进行管理。
Algeb的方式是,将数据源和数据使用进行隔离,如何从数据源获取数据不在Algeb的管辖范围内,但是开发者需要将一个函数托管给它,这个函数从数据源得到该数据源的数据。也就是说,它不关心获取的过程,只关心结果,也就是这个函数的返回值就是我需要的最终数据。
import { source } from 'algeb'
const Some = source(function() {
// ... 获取数据的函数,返回值即为被管辖的数据源数据
}, {
name: '',
age: 0,
})
复制代码但是有一个非常常见的问题,我们管辖一个数据源,却可能通过不同参数获得不同对象。例如:
async function getBook(id) {
return fetch(`/api/v2/books/${id}`).then(res => res.json()).then(body => body.data)
}
复制代码这是我们常见的一个用于获取一本书详细信息的函数。我们经常会传入id来决定获取哪一本书的信息。而面对这种情况,我们怎么去用Algeb管理呢?难道要为每一本书建立一个源?
当然不需要,Algeb所认为的数据源,并非指单一数据,而是获取形式相同数据的方法(也就是这个函数),并且以该函数的参数作为标记记录该源所有被使用到的具体数据颗粒。这个逻辑是内部实现的,开发者不需要关心,只需要记住一点,数据源函数参数最好越简单越好,这样有利于对参数进行计算,作为识别具体数据的依据。
const Book = source(getBook, {
title: '',
price: 0,
})
复制代码source函数的第二个参数是该源的默认值,我所崇尚的同步代码书写方式要求代码在执行一开始就是OK的,不报错的,所以,这个默认值非常关键,同时,通过这个默认值,也可以告诉团队其他成员了解一个数据源将获取到的数据的基本格式。
你可能会问,websockt推送的数据怎么办呢?由于algeb只关心获取数据的结果,所以开发者怎么从websockt获取数据我们并不关心。我自己想到一种方式是,用一个全局变量保管不同数据源来自websockt的数据,然后在数据源函数中,读取该全局变量上的属性返回。
组合
通常情况下,我们现有的数据源管理器只是简单的读写逻辑,并没有规定数据缓存的逻辑。我希望通过更抽象的方式,让开发者自己来规定数据再次请求的逻辑。通过Algeb的compose方法,可以组合一个或多个数据源,并附增特殊逻辑进去。
import { compose, query, affect } from 'algeb'
const Order = compose(function(bookId, photoId) {
const [book, refetchBook] = query(Book, bookId)
const [photo, refetchPhoto] = query(Photo, photoId)
affect(function() {
const timer = setInterval(() => {
refetchBook()
refetchPhoto()
}, 5000)
return () => clearInterval(timer)
}, [book, photo])
const total = book.price + photo.price
return { book, photo, total }
})
复制代码这是compose的一个例子。它通过组合book和photo两个对象,并附加算出这个订单的总价格,作为一个新的数据源返回。从“数据源”的定义上,Book, Photo, Order都是数据源,本质相同,只是类型不同而已。
有一个约定,虽然compose的返回值可以是任意的,但是它一定是同步执行完后返回,所以compose不接受async函数。
但凡是数据源,就可以在环境中(compose/setup)使用query读取,query函数接收第一个参数为一个数据源对象,后面的参数将作为数据源函数的参数进行透传。它的返回值是一个两个元素的数组,第一个元素是数据源根据该参数返回的值,第二个参数是刷新数据源数据的触发器(非请求器)。
在环境中,还可以使用affect等hooks函数,这些函数在环境中执行,例如上面这段代码中,通过affect规定了Order这个数据源一旦被查询,就会每隔5秒钟再查一次。这样,我们通过compose,实际上定义了一个不仅可以获取值的数据源,还定义了该数据源刷新数据的方式。
compose让我们可以在获取一个值的同时,还会触发其他源的更新。这在一些场景下极其好用。例如,我们有A、B两个源,当我们提交对A的更新后,需要同时重新拉取A、B的新值。我们可以通过compose来处理。
const UpdateBook = compose(function(bookId, data, photoId) {
const [book, refetchBook] = query(Book, bookId)
const [_, refetchPhoto] = query(Photo, photoId)
affect(function() {
updateBook(bookId, data).then(() => {
refetchBook() // 重新获取该书信息
refetchPhoto() // 重新获取图像信息
})
})
})
复制代码这个组合源只用于发送数据到服务端,发送成功后会同时抓取两个数据源的新数据。一旦新数据获取成功,所有依赖于对应数据颗粒(Book:bookId, Photo:photoId)的环境,全部都会被更新。
再算一次!
响应式应用框架的特征是自动将数值的变化反应为界面的变化。但如果你仔细观察我上述描述,就会发现,怎么实现响应式呢?这涉及到我们怎么去设计当数据源发生变化时,将这一变化产生的副作用即时反馈。
和常见的“观察者模式”不同,我借鉴的是react hooks的响应式方案,即基于代数效应的依赖响应。我们看react的functional组件,你会发现,它的响应式副作用,是“再算一次”!
再算一次!也就是组件function再执行一次,每次state被更新时,组件function被再次执行,得到新的组件树。神奇的“再算一次”特效,理论上会消耗更多性能,却让我们可以像撰写同步代码一样,从顶向底书写逻辑,并通过useEffect来执行副作用。
在Algeb中,我也是基于这种思路,但由于这是一个通用库,它不依赖框架,要去适应不同框架的差异,因此,我提供了一个setup提供执行上下文。
import { setup } from 'algeb'
setup(function() {
const [some, refetchSome] = query(Some)
affect(function() {
console.log(some.price)
}, [some.price])
render(`<div>${some.price}</div>`)
})
复制代码setup是所有algeb应用的入口,在setup之外使用algeb定义的源没有意义,甚至会报错。它接收的函数被成为执行宿主,这个宿主函数会被反复执行,它内部一定是会有副作用的,例如,上面这段代码,副作用就是render。当被query的数据颗粒获得新数据时,宿主函数会被再次执行,这样,就会产生新的副作用,从而反馈到界面上。
数据颗粒是指基于query参数的数据源状态之一,比如前面的Book这个源,每一个bookId会对应一个数据颗粒,每个数据颗粒保存着当前时刻该bookId的book的真实信息,一旦有任何一个地方触发了数据更新,那么就会让源函数再次执行,去获得新的数据,新数据回来之后,通过内部对比发现数据发生了变化,宿主函数就会再次执行,从而副作用生效。
如此循环往复,就会给人一种响应式的编程的感觉,而这种感觉,和传统的通过观察者模式实现的响应式具有非常大的感官差异,而这个差异,就是react践行的代数效应所带来的。
为了适应不同框架中更好的结合使用,我在库中提供了不同框架的使用。
React中使用
import { useQuery } from 'algeb/react'
function MyComponent(props) {
const { id } = props
const [some, fetchSome] = useQuery(SomeSource, id)
// ...
}
复制代码Vue中使用
import { useQuery } from 'algeb/vue'
export default {
setup(props) {
const { id } = props
const [someRef, fetchSome] = useQuery(SomeSource, id)
const some = someRef.value
// ...
}
}
复制代码Angularjs中使用
const { useQuery } = require('algeb/vue')
module.exports = ['$scope', '$stateParams', function($scope, $stateParams) {
const { id } = $stateParams
const [someRef, fetchSome] = useQuery(SomeSource, id)($scope)
$scope.some = someRef // { value }
// ...
}]
复制代码Angular中使用
import { Algeb } from 'algeb/angular' // ts
@Component()
class MyComponent {
@Input() id
constructor(private algeb:Algeb) {
const [someRef, fetchSome] = this.algeb.useQuery(SomeSource, this.id)
this.some = someRef // { value }
}
}
复制代码结语
在前端应用层和后端、持久化存储、websockt等原始数据交互时,对于前端而言,这种交互过程都是没有必要的,是和业务本身无关的副作用。Algeb这个库,试图用代数效应,参考react hooks的使用方法,实现前后端中间服务层的抽象。通过对数据源的定义和组合,以setup提供宿主,实现另一种风格的响应式。如果你认为这种抽象能激发起你一点点兴趣,不妨到仓库中一起讨论,写码。
-
当props里的id 为undefined时, 请求也会发起.这种情况怎么处理比较好?#975 ID_1188 2020-11-03 16:01
-
source函数里面拦截,返回undefined对应的值,能否请求是数据源函数的任务,与外部环境无关#976 回复给#975 否子戈 2020-11-03 16:58
-
偶尔会出现以下报错,应该是漏了forEach的参数i.
index.js:89 Uncaught (in promise) ReferenceError: i is not defined
at index.js:89
at Array.forEach ()
at index.js:86
```
atom.hosts.forEach(host => {
if (host.end) {
// the host is destoryed
atom.hosts.splice(i, 1);
} else {
host.next();
}
});
```#977 ID_1188 2020-11-04 10:31 -
确实是个bug,我修下发个版本#978 回复给#977 否子戈 2020-11-04 11:09
一种防抓取防复制的网页内容展示方法
https://codepen.io/tangshuang/pen/OJyxWjy
今天想到了这个方法,原理也很简单,就是将内容使用css的pseudo-elements保存,这种元素的conten无法被复制。

