作为React的核心概念之一,virtual dom从某种意义上改变了前端的现有体系。大部分人把virtual dom当做一种性能提升策略,因为它可以有效的减少直接操作DOM带来的消耗,从而提升脚本的执行效率。但是实际上,virtual dom并不完全是避免DOM操作的消耗,有的情况下,直接操作DOM可能来的更快,而virtual dom的真正意义,在于把直接的DOM操作和js编程,提炼成一个抽象层,virtual dom是对js操作DOM的抽象,对于今后的前端编程而言,developer无需再直接操作DOM,而是通过virtual dom去操作,这是它真正的意义。
本文是一篇对Virtual DOM原理和理念进行阐述的文章,因此希望做到脱离React,仅谈Virtual DOM.
Virtual DOM的知识内容
Virtual DOM这个知识点的内容包括:
- 将DOM树抽象成一个js对象
- 将抽象的Virtual DOM转换为真正的DOM
- Virtual DOM发生变化时,自动更新真正的DOM。包含两个内容:
- 通过一个diff算法,来比较新旧Virtual DOM之间的差异,并记录下来
- 将记录下来的差异,通过一个patch算法操作真实的DOM
接下来,我们就会对这些内容一一进行详解。
Virtual DOM的创建
将DOM树抽象成一个js对象,这个对象就是Virtual DOM。应该生成怎样的对象,这个对象有怎样的数据结构,生成的时候使用怎样的高效算法?
Virtual DOM的数据结构
和DOM一样,Virtual DOM也是由一个一个的节点组成,节点之间有父子关系,一个节点和它的子节点的引用,我们把组成的一个单元称为VNode(Virtual DOM Node),一个VNode应该包含哪些信息呢?
{
id: 1, // 标记这个VNode的唯一id,整个VTree可以完全用这些id图示出来,在diff中也有作用
name: 'div', // 标签名,甚至可以是自定义标签
props: { // 标签的属性
'id': 'my-tag',
'data-role': 'test',
'class': 'my-class the-class',
},
children: [ // 子VNode列表
{ ...another VNode... },
...
],
text: '...', // textNode, 如果标签直接包含文本内容的话,使用text,而非children
events: { // 绑定的事件
input: [ function(e) { ... } ],
},
}
上面的VNode仅是一个参考,而非标准,各框架(库)实现与此不同。但大体上,一个VNode对象,应该包含一个tag的完整内容,甚至它的上下文引用。
使用JSX生成Virtual DOM
在代码层面,我们是看不到Virtual DOM的真实内容的,我们无法通过console.log得到这个原始的js对象,因此也无法直接修改它。它是被封装在框架源码内部的一套格式,我们只管使用库提供的一些方法来生成它,而不用关心它是怎样的一种存在。当然,如果你要自己实现一套自己的Virtual DOM,也可以自己定义这些内容。
既然我们只能利用一些方法来生成Virtual DOM,那么就要找最简单的,那就是JSX。JSX用类似HTML的语法,实现Virtual DOM的生成。在掌握了少数与HTML不同的地方之后,使用JSX就像写HTML一样方便且直观易于理解。
例如,我们可以这样:
var node = (
<div id="my-tag" className="my-class the-class" dataRole="test" onInput={inputFunction}>
<span>text</span>
</div>
)
render(node)
用一段类似HTML的代码就可以生成一段VNode(包括children VNodes),而无需我们手工去写复杂的js对象。
实际上,在不同的框架体系里面,jsx的编译结果也不同,在React里面,会被解析为React.creatElement,而在vue里面,也会有自己的解析结果。但是JSX给了我们统一的生成Virtual DOM的接口,让我们可以不必因为不同的框架而撰写不同的代码。在不同的框架中,使用该框架提供的render函数去解析jsx即可。
render函数会将Virtual DOM渲染成真正的DOM,这我们将在下一节详细讲到。
将Virtual DOM渲染成真实的DOM
上一节提到,render函数会将Virtual DOM渲染为真实的DOM,虽然我们不用关心render的实现是怎么样的,但是为了了解其原理,还是要从代码层面去假装实现它。
现在,我们有了Virtual DOM(一个js对象),我们要利用它构建真实的DOM。在js中,我们使用document.createElement来创建一个标签,所以,实际上,渲染DOM只需要两步:createElement和insertElement。
function createElement(VNode) {
let node = document.createElement(VNode.name)
let props = VNode.props
let keys = Object.keys(props)
keys.forEach(prop => node[prop] = props[prop]) // 这里只是做个演示,实际上还需要详细考虑
return node}function insertElement(createdNode, parentNode, replaceNode) {
replaceNode ? parentNode.replaceChild(createdNode, replaceNode) : parentNode.appendChild(createdNode)
}
大致便是上面的思路,当然,在库具体实现的时候会复杂的多,比如事件绑定,比如在setInnerHTML的时候,要替换某个元素怎么办?但是,思路上就是这样,通过Virtual DOM创建一个真实的DOM元素,再将它挂载到适当的文档流中,或替换掉原来的某个元素。
diff算法
上述insetElement方法直接替换DOM或将Node插入到DOM中,虽然是由Virtual DOM转化而来,但是还不足以体现Virtual DOM的特性。Virtual DOM包含的一项内容,就是在上述insertElement之前,要进行新老Virtual DOM的对比,找出两者之间真正的不同之处,仅对这些不同之处进行更新。
现在的问题是,如何知道哪些VNode节点是要被更新的呢?这就需要一个diff算法来进行对比,而对比的时候,我们仅用到Virtual DOM作为对比的对象,而不涉及真实DOM。Virtual DOM更新视图之所以快,也是因此。
传统diff算法
传统 diff 算法通过循环递归对节点进行依次对比,效率低下,算法复杂度达到 O(n3),其中 n 是树中节点的总数。我们用代码来演示传统diff算法:
let result = [];// 比较叶子节点const diffLeafs = function(beforeLeaf, afterLeaf) {
// 获取较大节点树的长度
let count = Math.max(beforeLeaf.children.length, afterLeaf.children.length);
// 循环遍历
for (let i = 0; i < count; i++) {
const beforeTag = beforeLeaf.children[i];
const afterTag = afterLeaf.children[i];
// 添加 afterTag 节点
if (beforeTag === undefined) {
result.push({type: "add", element: afterTag});
// 删除 beforeTag 节点
}
else if (afterTag === undefined) {
result.push({type: "remove", element: beforeTag});
// 节点名改变时,删除 beforeTag 节点,添加 afterTag 节点
} else if (beforeTag.tagName !== afterTag.tagName) {
result.push({type: "remove", element: beforeTag});
result.push({type: "add", element: afterTag});
// 节点不变而内容改变时,改变节点
} else if (beforeTag.innerHTML !== afterTag.innerHTML) {
if (beforeTag.children.length === 0) {
result.push({
type: "changed",
beforeElement: beforeTag,
afterElement: afterTag,
html: afterTag.innerHTML
});
} else {
// 递归比较
diffLeafs(beforeTag, afterTag);
}
}
}
return result;
}
如果一棵树有1000个节点,那么如果全部进行比较,将会进行10亿次比较。以现代的计算机CPU算力,消耗的时间还是比较多的。因此,这不能作为virtual dom的diff算法来提升性能。
React的diff算法
React团队在研究了传统diff算法之后,结合web的特征,认为可以通过以下策略来简化传统diff算法:
- Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
基于上面的策略,React团队直接将传统diff算法中一些比较干掉,比如不去比较父节点不同的子节点,这样下来,复杂度直接降到了O(n)。
tree diff
不考虑DOM节点的跨级移动,在diff的时候,只对同一级的节点进行比较。
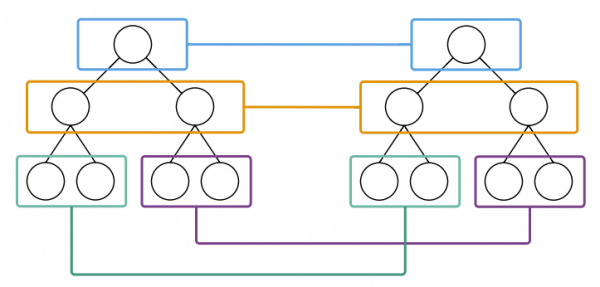
仅对同级节点进行比较,当同级节点存在差异时,不再进行子节点的比较
反过来说,两个节点是否要进行比较,只需要看他们是否属于相同的父节点。
在比较过程中,当新的Virtual DOM中某个VNode不存在于老的Virtual DOM中(同级同位置),那么这个VNode就会被认为是新增的节点。而如果某个VNode在老的Virtual DOM中有,新的Virtual DOM中没有,那么认为这个节点会被删除。
因为没有考虑移动的情况,所以,当在预期发生移动时,diff算法会怎么认为呢?比如:

diff算法不会把这种情况当做移动来处理,diff算法会认为,新的Virtual DOM中,原来的A节点会被删除,在D节点下会新增一个节点。这个新增的节点跟原来的A节点没有任何关系,虽然结构一样,但实际上它是全新的。
虽然这一做法不是很严谨,但是在实际的web项目中这样做并没有带来非常大的性能问题,相反,在处理细碎的大量变动时,反而带来了性能优势。不过React官方也建议,应该保持你的组件dom结构的稳定性,不应出现这种移动节点的现象。同时,由于A节点被移除时会被完全销毁,它的子节点也就跟着被销毁了,如果你要再次显示出来,就必须创建新的元素,所以,比较好的办法是使用css类来控制它的显示和隐藏,而不是通过数据变化因此Virtual DOM变化来更新视图。
component diff
React以组件作为自己的产出目标,组件与组件之间可以存在嵌套关系,所以组件本身的DOM也会遵循Virtual DOM机制。
- 如果是同一类型的组件,按照tree diff策略继续比较 Virtual DOM。
- 如果不是,则将该组件判断为 dirty component,从而替换整个组件下的所有子节点。
- 对于同一类型的组件,有可能其 Virtual DOM 没有任何变化,如果能够确切的知道这点那可以节省大量的 diff 运算时间,因此 React 允许用户通过
shouldComponentUpdate()来判断该组件是否需要进行 diff。
虽然两个组件的DOM可能完全相似,但是这种情况就没有必要创建两个组件,React官方认为不同类型的 component 是很少存在相似 DOM tree 的机会,因此这种极端因素很难在实现开发过程中造成重大影响的,因此他们毅然决然的采用了上述component diff策略,即使可能存在一定的性能误差。
element diff
当节点处于同一层级时,React diff 提供了三种节点操作,分别为:INSERT_MARKUP(插入)、MOVE_EXISTING(移动)和 REMOVE_NODE(删除)。
和tree diff不同,当对比同一组元素时,比如老的Virtual DOM中有一组p标签,和新的Virtual DOM中的这组p标签是同一个父节点,那么就要考虑这组p标签的实际情况,而不是一味的删掉再插入进来。比如新的Virtual DOM中,多了一个p标签,那么它可能是插入进来的;或者其中一个移动了;或者其中某个删除了。这个时候,在上面的Virtual DOM数据结构中的id就发挥作用了,在React中使用key作为这个标志。当一组p原本的id序列是1,2,3,4,5时,现在变成了4,2,1,5,3,那么可以通过重新排列它们就可以了。而如果现在变成了1,3,4,5,6,那么可以知道,2被删除了,6被插入进来。

所以,给每一个VNode一个唯一标识只非常重要,如果不存在这个标识,那么当遇到上述情况的时候,diff算法无法知道当前新的Virtual DOM中的元素和老的Virtual DOM中的元素是不是一样的,他们虽然name值可能一样,但是可能存在上下文的差别,比如绑定的事件不同,所以diff算法在无法获取这个唯一标识的情况下,只要发现不同,就会把对应那个位置的元素及其之后的所有元素都销毁,把新的Virtual DOM中对应的元素加进来,这样性能上就差了一大截。
差异的记录
diff算法的目标,是找出Virtual DOM在前后的差异,并把这些差异保存起来。但是有一个问题,保存在哪里?老的Virtual DOM保存在哪里?差异的记录保存在哪里?
React是以组件为单位的,因此,这个组件的Virtual DOM被保存在组件的特定属性里。当组件的数据发生变化的时候,会产生一份新的Virtual DOM,这份新的Virtual DOM会被用来和保存起来的老的Virtual DOM进行对比,当后续操作(patch)完成之后,新的Virtual DOM会被保存到该属性上把老的给覆盖。
diff算法没发现一个差异,就会把该差异记录到一个特定的变量中,保存差异的变量是一个数组,该数组的每个元素是一个对象,记录着差异的类型、结果、需要进行的操作。
function enqueueInsertMarkup(parentInst, markup, toIndex) {
updateQueue.push({
parentInst: parentInst,
parentNode: null,
type: ReactMultiChildUpdateTypes.INSERT_MARKUP,
markupIndex: markupQueue.push(markup) - 1,
content: null,
fromIndex: null,
toIndex: toIndex,
});
}
function enqueueMove(parentInst, fromIndex, toIndex) {
updateQueue.push({
parentInst: parentInst,
parentNode: null,
type: ReactMultiChildUpdateTypes.MOVE_EXISTING,
markupIndex: null,
content: null,
fromIndex: fromIndex,
toIndex: toIndex,
});
}
function enqueueRemove(parentInst, fromIndex) {
updateQueue.push({
parentInst: parentInst,
parentNode: null,
type: ReactMultiChildUpdateTypes.REMOVE_NODE,
markupIndex: null,
content: null,
fromIndex: fromIndex,
toIndex: null,
});
}
上面的updateQueue就是这个变量,它里面记录着每一个差异,其中有一个type属性,用来表示这个差异后续应该执行怎样的操作。
patch算法
当知道了哪些地方是有差异的,需要更新真实的DOM之后,我们就可以对真实DOM进行操作了。虽然我们可以像第二部分中一样,用一个render函数去重新渲染,但是通过这里的patch算法进行操作,效率会高很多。
function patch (node, patches) {
var walker = {index: 0}
dfsWalk(node, walker, patches)
}
function dfsWalk (node, walker, patches) {
var currentPatches = patches[walker.index] // 从patches拿出当前节点的差异
var len = node.childNodes ? node.childNodes.length : 0
for (var i = 0; i < len; i++) { // 深度遍历子节点
var child = node.childNodes[i]
walker.index++
dfsWalk(child, walker, patches)
}
if (currentPatches) {
applyPatches(node, currentPatches) // 对当前节点进行DOM操作
}
}
function applyPatches(node, currentPatches) {
currentPatches.forEach(function (currentPatch) {
switch (currentPatch.type) {
case REPLACE:
node.parentNode.replaceChild(currentPatch.node.render(), node)
break
case REORDER:
reorderChildren(node, currentPatch.moves)
break
case PROPS:
setProps(node, currentPatch.props)
break
case TEXT:
node.textContent = currentPatch.content
break
default:
throw new Error('Unknown patch type ' + currentPatch.type)
}
})
}
这里红色的currentPatches就是我们前面的updateQueue。其中,reorder和setProps都有具体的实现方法,无非都是通过JavaScript原生的dom操作方法进行操作。
数据响应
Virtual DOM确实让DOM操作变得抽象很多,但是还需要和数据结合起来。数据的变化会带来视图的变化。
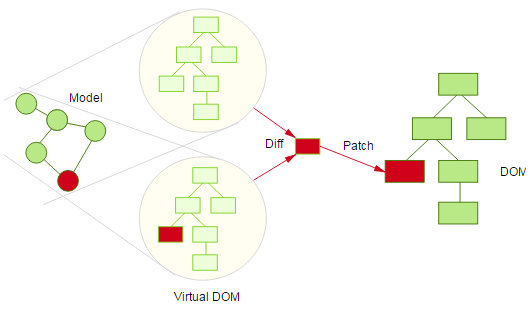
当model上的数据发生变化时,自动触发virtual dom的diff算法和patch操作
对数据的监听是model层面的逻辑,当监听到数据有所变化之后,需要重新调用render方法,调用时就会触发diff算法,进而进行patch操作:
import {Component} from 'react'
class App extends Component {
constructor(props) {
super(props)
this.state = {
value: '',
}
}
handleChange(e) {
let {value} = e.target
this.setState({ value })
}
render() {
return (
<div>
<input value={value} onChage={this.handleChange} />
<span>{value}</span>
</div>
)
}
}
在React中,执行上面红色的setState的时候,React内部会自己去调用render函数,得到Virtual DOM,完成Virtual DOM的diff和patch。当你自己实现了setState方法之后,你也就基本实现React核心的功能。
小结
在文章开头,我提到Virtual DOM的意义在于抽象。这是因为在性能上,其实它并没有占太大的便宜,只能说还过的去,从上面的分析中你就可以知道,非得用Virtual DOM来更新视图的话,有些原本用一个innerText就搞定的操作,却要在代码内部溜一大圈儿。但是,正是由于这种统一的封装,让你不用再去编写一整套的根据数据渲染DOM,监听数据更新DOM的操作。这让Virtual DOM在原始的js编程基础上更进了一步。将Virtual DOM应用到React Native,js程序就不用再关心底层是浏览器提供的DOM,还是手机提供的UI接口,在通过js去更新视图这个代码层面,就得到了统一。这才是Virtual DOM最大的意义。
2017-08-24 8780 React, Virtual DOM



您写的传统diff算法的代码演示,就是分层比较吧。
我看网上的搜索,传统的思路应该是对新的树每个节点遍历查找旧的树n^2,然后找到最小编辑距离n,合起来是n^3。但是这一块我在网上没找到代码。
是有问题
[…] 在我写完《Virtual DOM原理浅易详解》之后,我打算把Virtual DOM的体系拆解开。其中非常重要的一点,是我打算做一个HTML的解析器,在通过fetch抓取到某个网页之后,可以通过这个解析器,快速得到自己想要的数据。而这一部分,是Virtual DOM整个知识体系的一部分,即“DOM树抽象成一个js对象”这个部分。于是,我希望通过本文,详细阐述我是怎么创建自己的这个抽象js对象。 […]