实际上,flux和mobx都是一种观察者模式的实现,只不过flux将数据管理更加抽象出来,比简单的订阅-发布模式更加复杂,而mobx则相对而言更加贴近订阅-发布模式,因此使用起来更加简单,当然,有那么一句话,使用起来简单的东西,实现起来更复杂。相信两者都还有更长的路要走。
Redux和MobX是前端领域最前沿的两个状态管理library,前者遵循Flux思想,后者独树一帜,不过可以认为继承了observer思想。在具体本文的阐述前,让我们通过对这两种思想的简单讨论,来感受前端数据(状态)管理的复杂局面。
Flux vs. MobX
首先需要指出的是,“数据(data)”和“状态(state)”是不同的概念,但由于很多人对此只是心知肚明,所以就混用。在下一节我将专门探讨一下这个概念之分。总之,在讨论redux和mobx领域,你看到的“数据”其实都是指“状态”的概念,当然,有些状态是直接对数据的引用。
flux的思想中,对于一个应用它需要有一个或多个store来存储状态,redux为了简化,统一为只有一个store。
一个state对应来一个前端界面,这是一种新的思想,在angular的时代,我们强调数据驱动界面,但在react时代,驱动界面但是state,而实际上,state同时包含来对数据对引用和其它一些信息,比如你选择过了某个选项,界面就应该呈现出选中该选项对效果。特别是一个dialog,如果它的state中的isShow是true,就应该显示出来,如果是false自然应该隐藏起来。所以说,把显示界面的全部代码(component)当作一个纯函数,输入一个state,它每次输出的界面都是相同的。这种思想自然要比前一个时代更贴近真实。
store中存储了state,一个固定的state对应一个固定的界面,当store中的state发生改变时,界面也应该随之改变。现在的问题是,谁来将state存入store,谁来修改store中的state。在flux中,由action触发dispatcher来将state写入或修改入store中:
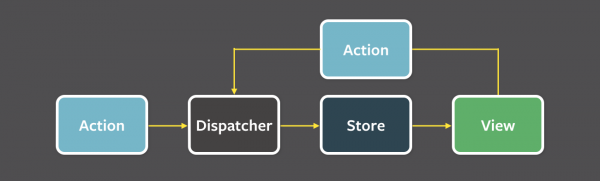
flux状态控制示意图(来源)
redux的store使用dispatch方法来传递action,而dispatcher修改store是通过reducer,通过subscribe方法让开发者自己控制当state发生变化时如何更新view。因此,redux是完全安装flux的思想实现的。
现在让我们来看下MobX的思想。
MobX也是管理状态,但是并不存在一个固定的store,它不需要store来存储所有的状态信息,你需要一个store时,立即通过一个observable方法封装一个state,就得到一个可被监控的state,这个state实际上被放在mobx的一个store中,你可以像普通的js对象一样,对这个state进行修改,而在修改时,store自动发生触发view的变化。这个过程里面你会发现,相比于flux,少来action和dispatcher这两个环节。虽然我们也对state进行来修改,但是这个修改不是通过store的方法实现的,而是我们自己像修改一个js对象一样随意改的。当然,mobx内部由于observer机制,是可以知道你进行来修改的,所以,当你修改的时候,store就会通知view进行对应的改动。当然,这里一个state对应一个view的原则是一样的。

MobX状态控制示意图(来源)这里需要注意的是“Action”并不是mobx的某个动作或元素,而是指开发者自己像修改js对象一样修改经过observable函数包装过的那个state,而“State”就是指这个被包装过的,或者说,被包装过的才叫state,不然只是个普通的js对象。
MobX的思想,建立这一个东西上,那就是observer,即state是可以被观察的,当像修改js对象一样修改state的时候,store是可以知道具体哪里被修改来的。而store修改views是通过observer方法实现的。因此,我称mobx的思想叫observer思想。
从两种思想的使用上讲,显然mobx的使用方法简单的多,但是对于使用者而言,mobx的理解成本要更大一些,使用时遇到的坑也可能更多。
总之,这两种思想是目前市面上对状态管理的主流思想,MVC或者MVVM基本上已经被打败了。
一个数据管理器的核心需求
但是,我们要讨论的,是如何来管理我们的数据,而非状态,我相信上面两种思想已经是解决状态问题的最好方案了。在讨论数据管理器之前,我们还是讨论一下data和state的区别,以避免在下文的阐述中你会反复问“已经有redux了,我为嘛还要一个数据管理器”这样的问题。
“数据”和“状态”的区别
其实区别是显而易见的,只是我们不愿意去承认。数据是我们从服务端取回,或本地已经准备好的固定格式的静态内容结构。注意“静态”这个词,它的意思是,一份数据,对于我们的应用而言,是不变的,你可以使用它,也可以在知道有新的数据可以代替它时把它丢掉。
从server side取回数据是我们要讨论的唯一话题,我们不考虑本地存储的数据的问题,因为本地存储的数据对应一个地址,它们两个都永远不会变。而服务端的一个地址,对应的数据却偶尔会变。因此,我们要关注的是后者。但是对数据的概念本身而言,一份数据一旦获得之后,就不会改变了,会改变的,是从同一个地址取回的两次数据不同这个变化。
而状态则是随时可以发生变化的内容结构。我都可以不用多解释你就可以理解,比如点击一个按钮,状态从display变为hidden。
为什么有了redux/mobx还需要datamanager
状态可以对某一份数据进行引用,这样,似乎状态管理器也可以对数据进行管理了。而且对于一个application而言,如果要求整个应用的所有界面都由state决定,那么把数据作为状态的一部分也是理所当然的。然而,假如我们使用mobx呢,我们很难说将整个application的状态交给一个store去管理,要知道整个界面的状态集合之大,到最后一定会逼近无法管理的零界点。
另一种想法是,我们的application不是由单一的技术开发完的,一个框架解决一类问题,如果同一个界面出现了两个不同技术实现的components,那么可能存在一种情况,它们可能并不依赖同一个state,却可能依赖同一个data。这种case导致我们需要有一种机制,保证它们两个使用同一个数据,请求数据不会重复发生,当一个component请求到最新的数据时,另一个component应该自动使用这个最新的数据。
总之,这里要说的就是,当redux/mobx无法适应对单纯数据管理的需求时,我们需要一个datamanager。
datamanager的基本功能需求
从功能上我们来看datamanager它应该包含什么样的需求。
首先是数据存储。它把涉及到的相关应用的数据统一存放,有需要,都从我这里取,不需要自己管理数据,甚至如果你需要对原始数据进行一定的格式转化,也可以交给我来处理。
其次是获取数据。应用只需要非常简单的方法就可以从我这里得到它想要的数据,当然,如果我这里确实还没有这个数据,只能返回undefined,但是这个时候我可以马上去取,以防止你下次来取时我还没有。但是对于使用者而言,它不需要关心这些,它只需要知道如何从我这里获取数据,有就得到,没有就得到一个undefined。
最后是获得通知。应用第一次通过get方法去datamanager取数据的时候如果没有得到想要的数据,那么当datamanager从服务端取回数据保存起来之后,应该有一个机制,告诉刚才来取数据的应用数据已经有了,你可以再次来取(还是用get方法来取)。
至于你得到数据之后,你要干什么我们一概不管,你是用来更新views还是怎么办,都不是我们要管理的内容。这是和state管理器巨大的不同,statemanager必须要确保state和views的一致性,而datamanager完全不管views。
总结起来,我们可以通过下面一张图来解释datamanager:

datamanager的数据管理模型
和flux、mobx思想比起来,由于data是静态的,因此没有被修改的概念。但是同一个地址对应的data是会被修改的,是在request请求完成之后被修改的。每一次datamanager发起request,都可能得到新的数据,把老数据替换掉。
datamanager的实现思想
如文章标题,我们通过对flux和mobx思想的结合,实现我们想要的datamanager。
register
对于应用而言,需要告诉datamanager我想要从哪个url获取数据,获取的方法是什么,当我准备get这个数据时,希望你做什么样的transform。注册数据源,基于这个数据源,应用才可以做get和be notified相关的操作,否则是无源之水。
对应flux,我们需要创建一个store,没有store后续什么都没有。
subscribe
应用订阅一个数据在请求发生后的变化通知,当数据请求结束后,datamanager中存放的这个datasource的数据如果发生变化,那么应该通知应用程序。
这对应的,是redux里面的subscribe方法,虽然datamanager不负责view的任何东西,但是注册回调机制是必须有的。在回调函数中应用自己去决定要做什么。
get
获取数据,通过该方法获取数据,没有数据就返回一个undefined。
补充:
有童鞋反应,get的使用让人比较难理解。确实,这需要从传统的request的思想中转换过来。为了提供一种过渡,我在最新版的datamanger中加入了request方法,它的职责与get不同,主要是用来返回一个promise,这样在编程上和get形成两个体系,开发者如果想从传统的方法写代码,可以使用request方法,在then中拿到返回的数据(虽然这里也会使用缓存,subscribe的回调也会在新数据返回时被执行),进行下一步操作。
这样,get的职责就更加明确,不再包含任何请求数据的意味,完完全全是从datamanager中获取被缓存数据的意思。当然,如果发现数据不存在或过期,也会在后台发起一个请求去取最新数据,但这对于开发者而言,是无感的。它更多的意义在于通过依赖收集,配合autorun,使得开发更加便捷。
autorun
这个概念在前面的mobx中没有讲到。autorun在mobx的意思是,当你有一个函数,它本身本身永远不会有观察者,所以没有办法在数据发生变化时即使响应来重新执行,这个时候,我们可以使用autrun方法来包裹它。这个函数内部可能对我们观察的其它东西有依赖(mobx就是对其中的某个state,在本文就是对某个datasource),那么当依赖变化时,就重新再执行一次。不过有一个前提,autorun方法会在包裹这个函数时提前执行函数一次,这样才能实现收集依赖。
在datamanager中,这个设计不是必选的,但是它可以大大提高我们的开发效率,使得开发者再使用datamanager时,不用写subscribe,代码简单很多。
autorun的实现背后是依赖收集的思想,也就是mobx中computed values的后背原理。
save
把数据保存到服务端也是个话题,但相对于获取数据,是一个相对比较隔离的,但是这里又不得不讨论,因为保存数据是不可避免的。save不参与前面讨论的那几个机制,也就是说,它是独立的一个操作,你只需要提供对应的datasource id和post data,就可以把数据save到对应的url去,因此,如果你一个api设计为restful风格,其实是可以被get和save重用的,这样可以减少register的次数。
save的重要创新是一个简单的事务机制,我之前写过js实现超简单setState事务机制可以在这里用上。简单的说,就是短时间内(同一段代码里两次执行save操作),如果执行了多次save同一个datasource的操作,那么这几个save操作其实可以合并,没有必要每次save都去请求api,而且如果多次请求,还可能导致一些错误现象的出现,比如网路震荡引起前一个request后达到,导致保存的数据反而被前一个数据覆盖。因此,保证每一个保存是所有操作最终的合并结果反而很重要。因此,save实现了这个机制。
通知什么时候被触发?
当应用通过get要取某个datasource的data时,datamanager会直接从缓存中获取值并直接返回。但是,当datamanager发现缓存中的数据不存在,或者过期,那么就会去服务端请求最新的数据保存起来。而如果请求到最新数据之后,就会立即发起通知,所有subscribe了该datasource的回调函数会被执行,所有通过autorun方法包裹的函数,如果自己内部依赖了该datasource,也会被执行。
这里需要理解的点是,一个datasource的回调函数不一定只来自于当前你开发的这个组件,也有可能来自其他人开发的组件,你的request可能会触发对别人组件的通知,当然,别人组件的request也可能触发对你的组件的通知。因此,subscribe其实是一个全局的考虑,不要仅仅想到你自己的代码里面什么地方request了,会得到什么结果。从事件的发生上看,subscribe和get/request应该是两个完全独立的逻辑,不应该有强联系。
没有dispatch操作
datamanager管理的是data,因此没有dispatch操作。虽然dispatch的实现也很简单,但是我们并不允许应用修改任何存储在datamanager中的数据。
为了防止用户直接操作修改通过get得到的数据,我们在get输出数据时,进行了一次深拷贝,这样对于应用而言,它即使强制修改了数据,也不能影响其它应用,因为从代码层面,实际上它们使用的根本不是同一个js对象(虽然性能上会有一定的影响)。
transform
如果get得到的是一个deep copy,那么问题来了,两个组件希望获取到的数据是经过格式化的,甚至我们可以假设这两个组建的格式化结果一模一样,那么怎么办?如果它们引用的是同一个js对象,一个组件改了数据,另一个组件也可以得到修改后的数据。但是现在不行。
我们提供了transform接口,在数据通过get方法流出datamanager之前,会经过transformers处理,如果两个组件对数据结构的格式化一模一样,可以在它们注册datasource的时候,传入同一个处理函数。
当然,transform并非为了解决这个特殊的case,实际上,transform是希望实现一种格式化机制,由datamanager来管理数据格式化,对于组件而言,只需要拿到数据,直接使用即可。
interceptor & adapter
最后一个比较复杂的问题是,如果对于每个请求,需要在请求之前进行鉴权信息的注入,那么应该提供一种方式达到这一目的。于是我加入来interceptor这一层,用于在request发出之前,可以对request信息进行修改。比如我们在发出每一个请求之前,必须先通过另外一个api接口,获得鉴权信息,得到正确鉴权信息之后,把该鉴权信息加入到当前request的headers中。通过interceptor就可以实现这一逻辑,在interceptor函数中,先去get auth token,获取之后调用一个next函数。
但是也有场景需要去验证response内容,比如如果发现状态码是206时,想要特殊处理。我们提供了adapter机制,和interceptor相对,adapter是对返回信息response的处理。在adapter函数内部,也可以通过next或stop方法决定该请求是否可以进入下一步处理。
共享单例
在开发中,我们存在两种不同的情况。第一种是组件开发团队仅关注自己的单独组件,因此,不会考虑外部其它团队具体怎么使用datamanager,另一种情况是不同组件之间共享一个datamanager单例,这样对于组件而言,完全把这个单例当作是一个依赖,调用该依赖的api即可。我们来看下共享单例的创建:
// datamanager.js const datamanager = new DataManager() datamanager.register([ ... ]) export default datamanager
在一个其它的module中,我们使用这个单例:
// componentA.js
import datamanager from './datamanager'
function render() {
let user = datamanager.get('user')
if (user === undefined) {
return
}
console.log(user)
}
datamanager.autorun(render)
我们在datamanager.js文件中注册来很多datasource,而且每一个datasource都包含了middlewares, modems, transformers等,所以,在具体组件使用中,仅仅使用对应的datasource id就可以得到想要的数据。多个组件完全是共享这些datasource以及它们的中间件、猫等信息。
这有点类似redux的store在整个application中使用一样,你可以创建不同的单例,运行在不同的部分,这样可以做到既共享数据,又隔离中间件、猫、转换器等。
总结
本文从两种不同的状态管理思想展开,探讨来一个独立的数据管理器的实现思想。它结合来flux和mobx的一些思想,根据data的静态特质,删除了dispatch操作。通过该思想,我已经实现了一个可用的datamanager,你可以通过这里查看源码和本地预览。当然,这里面还有很多值得探讨的问题,如果你有什么想法,欢迎在我博客下方留言。

