前端性能优化深入浅出
前言
我在2021年接受慕课网要求制作前端性能【转载请注明来源】本文作者:唐霜,转载请注明出处。优化课程,但由于个人原因,在年底的时候不著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。得不放弃教程的推进,当我打开已经制作好的【版权所有】唐霜 www.tangshuang.net【作者:唐霜】部分教程材料时,我意识到不能浪费这些材料【版权所有,侵权必究】【原创不易,请尊重版权】,于是现在将它们整理出来,并补全没有做完转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。的部分,使它成为一份完整的前端性能优化知原创内容,盗版必究。【转载请注明来源】识体系提供给读者朋友作为参考。
【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】原创内容,盗版必究。本文作者:唐霜,转载请注明出处。本册的内容将会分为5个大的部分,第1部分【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】讲加载性能优化,其中大部分内容仅适用we【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】b平台,是其他很多讲前端性能优化的课程的【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。主要内容,但我认为加载性能并非我们日常开转载请注明出处:www.tangshuang.net原创内容,盗版必究。发中常见的性能问题,不过这部分知识你又不本文作者:唐霜,转载请注明出处。【未经授权禁止转载】得不了解,因此,我把它作为第1部分;第2【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。部分讲渲染性能优化,其中大部分内容也仅适著作权归作者所有,禁止商业用途转载。【转载请注明来源】合web平台,但是其中又有一些知识是通用【作者:唐霜】本文作者:唐霜,转载请注明出处。的,可以在其他平台上也如此去思考;第3部【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。分讲运行时性能优化,这一部分我认为是本册【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net的精华部分,是我们日常开发中最常面对和需著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】要了解使用的优化技巧或技术,这一部分的内【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】容我还会持续补充,你可以关注我的微信公众【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。号 wwwtangshuangnet 来著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】获得内容更新的消息;第4部分讲框架性能优【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】化,主要针对我们基于react和vue进【本文受版权保护】本文作者:唐霜,转载请注明出处。行开发的工作中所遇到的性能问题进行分析和本文作者:唐霜,转载请注明出处。【转载请注明来源】优化,这部分知识实际上是不通用的,将来这【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。两个框架不再流行了,或者框架内部自己解决原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】了这些问题,这部分的内容就没有价值了,因未经授权,禁止复制转载。【版权所有,侵权必究】此,我也会在后续更新这部分的内容;第5部【本文首发于唐霜的博客】原创内容,盗版必究。分讲开发构建性能优化,主要目标是提升我们原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。开发或CI/CD的执行速率,提升开发的幸【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。福感,不过这部分内容也如上一部分一样,不【本文首发于唐霜的博客】【作者:唐霜】是通用的,且不同场景下也不一样,我只能做【版权所有】唐霜 www.tangshuang.net【作者:唐霜】到把自己所了解的一些性能问题和优化技巧拿【版权所有】唐霜 www.tangshuang.net【转载请注明来源】出来讲解,帮助在工作中遇到相同问题的读者【未经授权禁止转载】【原创内容,转载请注明出处】朋友们解决这类问题。
【原创不易,请尊重版权】【作者:唐霜】【原创内容,转载请注明出处】性能优化是一项渐进式的工作,正像《重构》【版权所有,侵权必究】原创内容,盗版必究。一书中指出,“大多数情况下可以忽略性能问转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】题,如果重构引入了性能损耗,先完成重构,【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。在做性能优化”,解决性能问题在我们的日常【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。开发工作中实际上占用的比例非常小,我们可【本文首发于唐霜的博客】【原创内容,转载请注明出处】能在写了几个月代码之后,才会遇到一个严重【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。的性能问题,因此,我们没有必要为了性能问转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】题而在一开始就小题大做,但是我们必须掌握原创内容,盗版必究。转载请注明出处:www.tangshuang.net性能优化的能力,当我们遇到性能问题时,有原创内容,盗版必究。【未经授权禁止转载】武器去对付它解决它。当然,如果你阅读了本【转载请注明来源】【本文受版权保护】册的第3部分,你就能掌握一些小的常见的可本文版权归作者所有,未经授权不得转载。【本文受版权保护】以避免性能隐患的技巧,通过长期的习惯,让【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net你所写的代码在平均水平上就是高于别人写的【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net烂代码。从这个意义上讲,其实写出好的代码原创内容,盗版必究。【原创内容,转载请注明出处】本身就是写出高性能代码的一种体现,一般来【转载请注明来源】本文作者:唐霜,转载请注明出处。讲,写出好代码本身就包含了“这段代码是高未经授权,禁止复制转载。原创内容,盗版必究。性能的”这一意思在里面。
【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】最后,我想,知识本身往往是比较枯燥的,为原创内容,盗版必究。【未经授权禁止转载】了在这个枯燥中增加一些趣味,我会在写作过【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】程中融入一些武侠小说的元素,你会看到一个【版权所有,侵权必究】【作者:唐霜】初出茅庐的小伙出山学武,不畏艰难,逐渐成【转载请注明来源】【转载请注明来源】长,最后成为一代大侠问鼎武林的冒险故事,未经授权,禁止复制转载。【原创不易,请尊重版权】伴随着故事的进展,你也将掌握前端性能优化著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】的大部分内容。
著作权归作者所有,禁止商业用途转载。【本文受版权保护】【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】起始于终:一个列表的性能优化之路
【原创不易,请尊重版权】【版权所有,侵权必究】飞阳如隙,回首我此生,楞过、苦过、狂过、著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】惨过、耀过,如今来看,都是命运。我之坚信【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】、动摇、坚持,铸就我今立于此封顶,纵乱世【原创不易,请尊重版权】原创内容,盗版必究。纷涌,于我乃清风拂发,俯览众生,有悲有喜【本文受版权保护】【未经授权禁止转载】,一切皆历便可放下,或许能做些利众生的事本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。……
转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。
我曾有次被加微信好友问到性能问题,当时那【本文受版权保护】【版权所有】唐霜 www.tangshuang.net位朋友问我“我有一个订票的模块,性能差,【本文受版权保护】【关注微信公众号:wwwtangshuangnet】该怎么优化”,面对这样的提问,我是有些不本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。悦的,我认为这不符合提问的原则。但我意识【本文首发于唐霜的博客】【本文受版权保护】到,并非每个人都懂如何优雅的提问,并非都【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net懂提问的技巧,他们只能抛出表面问题,需要【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net有人去对他们的问题进行拆解。于是,我让他未经授权,禁止复制转载。未经授权,禁止复制转载。打住,采用一问一答的形式,让我可以初步诊本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】断他所面临的性能问题究竟是什么,并且对症原创内容,盗版必究。原创内容,盗版必究。下药给出解决的思路。对的,我只能给到思路【原创内容,转载请注明出处】【转载请注明来源】,因为不同的应用所实施的具体方案是不一样【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】的,所以无法给出具体的实施步骤,只能给思未经授权,禁止复制转载。【版权所有,侵权必究】路,由开发者顺着思路自己去解决这些问题。
【本文受版权保护】【作者:唐霜】“是你的这一个页面打开之后一片空白的时间原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】比较长,还是可以很快打开但呈现不出来数据【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】?”
【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。“都不是,是在操作的时候会有卡顿。”
【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】【转载请注明来源】【未经授权禁止转载】“很好。卡顿是在什么情况下产生的?是点击转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。一个按钮之后卡住不动了,还是怎样?”
未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。【未经授权禁止转载】“是在用户往下滑需要加载更多条目的时候卡【原创内容,转载请注明出处】【原创不易,请尊重版权】死了。”
【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】【本文受版权保护】本文作者:唐霜,转载请注明出处。“你有查过是后端接口吐出数据慢吗?”
【未经授权禁止转载】【未经授权禁止转载】“没有,我手动打开那个接口,发现打开是瞬著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。间的。”
本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。“一般来讲,加载一页会有多少条数据?”
未经授权,禁止复制转载。原创内容,盗版必究。【本文首发于唐霜的博客】“10条。”
【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net此时,我们已经把这次性能问题的范围缩小了【转载请注明来源】【原创不易,请尊重版权】,可以肯定的是,这次问题是代码层面的问题未经授权,禁止复制转载。【作者:唐霜】,只要我们通过修改代码,就能解决这次问题本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。。而且,这次性能问题,不是由于大数据量引转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。起的,我们排除了大数据量性能优化的一些策原创内容,盗版必究。【未经授权禁止转载】略。
本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。【转载请注明来源】未经授权,禁止复制转载。“你可以通过chrome的devtool【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】来看下performance。”
原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。“好的。”
【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】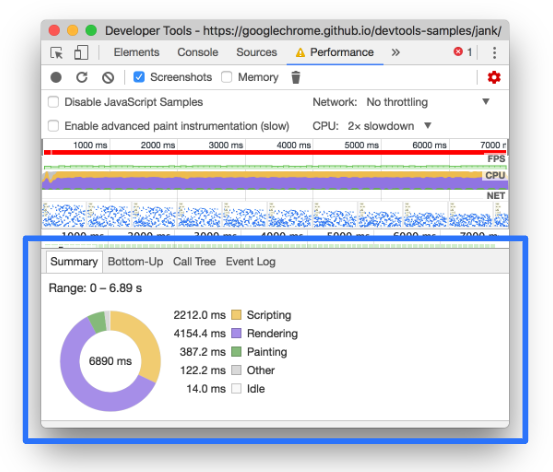
我们看到,rendering占据了4秒多转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。。可以大概知道,这是一次由于对DOM的操【本文受版权保护】原创内容,盗版必究。作不当引起的重新渲染性能损耗。
【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。“你可以通过上面的火焰图找到执行时间最长原创内容,盗版必究。原创内容,盗版必究。的一条,并且鼠标放上去,找到对应的代码文本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。件,并且找到对应的代码位置。”
本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】【原创内容,转载请注明出处】“原来还有这样的操作?我看看……找到了,未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】xx函数的执行时间超过了2秒。但是我看代【本文受版权保护】【版权所有,侵权必究】码写的没有什么问题呀。”
转载请注明出处:www.tangshuang.net【本文受版权保护】【作者:唐霜】转载请注明出处:www.tangshuang.net“可否把这段代码发给我看下呢?”
本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】“好的。”
【原创不易,请尊重版权】【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。随后我检查了一下他的代码,并没有发现什么本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net问题。但是在仔细阅读后,我发现他有一个函【未经授权禁止转载】【未经授权禁止转载】数的命名比较奇怪。
本文版权归作者所有,未经授权不得转载。【作者:唐霜】“这个函数都做了什么操作呢?”
本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。“我把这个函数的代码也发给你。”
【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。在阅读代码之后,我终于找到了问题的所在,本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】这个函数作为一个入口,里面会做大量的计算【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】,用来确定列表加载之后某个元素的位置,而【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。该计算又会读取渲染后DOM的信息,用来再【作者:唐霜】【版权所有,侵权必究】次计算,再次确定其位置,如此反复,最终达【转载请注明来源】【本文受版权保护】到一个稳定的状态后才停止计算。正是因为这著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】个设计,导致每次加载完数据后DOM会被持【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】续的修改,同时做一个复杂的计算过程。
【转载请注明来源】原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。针对这一问题,我给出了自己的建议。“你可【原创内容,转载请注明出处】【转载请注明来源】以提前预算好元素的位置,在完成渲染之后,转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】再做一次调整,这一只需要重复渲染一次。”
【原创不易,请尊重版权】原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。“好的,我试试。”
【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。过了大概半个小时。
未经授权,禁止复制转载。【本文受版权保护】“太棒了,不卡了,谢谢你。”
【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】这是一次非常小的优化事件,但是我们从中了【原创内容,转载请注明出处】【本文首发于唐霜的博客】解了锁定性能问题的路径之一,以及一些解决转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net的方法。
【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】【本文首发于唐霜的博客】前端性能问题的解决,非常大的一部分工作,【未经授权禁止转载】原创内容,盗版必究。就是在锁定问题根源这个过程。有的时候,我【版权所有】唐霜 www.tangshuang.net【本文受版权保护】们没有方法去找到问题根源,有的时候问题具【本文受版权保护】原创内容,盗版必究。有迷惑性我们以为找到了问题根源,但是最终【未经授权禁止转载】转载请注明出处:www.tangshuang.net发现没有效果。但是,往往我们锁定问题之后【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。,解决起来就比较容易。这也印证了我前文所【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net讲的,性能问题是一个需要渐进式解决的问题【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。,而非一系列完整的方案。
【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】缘起轻虚:性能问题的起点
原创内容,盗版必究。未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net我意识到自己不够强,那些恶人,怎能如此凶转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。残?只有变强,我才能对抗他们,让他们血债【本文受版权保护】未经授权,禁止复制转载。血偿!可是,我要如何才能变强?对,我要练著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】武,我要学会世上最强的武功,无人能敌。于原创内容,盗版必究。【版权所有,侵权必究】是我背起包袱,离开了生于此地十多年的山水原创内容,盗版必究。未经授权,禁止复制转载。,迈上未知之途。
【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】【未经授权禁止转载】
我们要意识到,前端性能问题,和后端性能问【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】题不同,本质上,前端的性能问题都是渲染性【本文受版权保护】本文版权归作者所有,未经授权不得转载。能问题,当然,引起渲染性能损耗的可能是对【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】渲染原理的不懂,也可能是我们写了不好的代【转载请注明来源】本文版权归作者所有,未经授权不得转载。码。但是归根结底,我们还是要掌握浏览器渲【未经授权禁止转载】未经授权,禁止复制转载。染原理,才能写出符合起原理的好代码。
【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。未经授权,禁止复制转载。这一节,我想在所有优化技巧开始之前,写一【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。些思想层面,意识层面的东西,让我们在开始【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net实操之前,具备思想、方法论层面的建设。
转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】原创内容,盗版必究。性能问题的分类
我们从引起性能损耗的原因出发对性能问题进【本文首发于唐霜的博客】【未经授权禁止转载】行分类:
【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。- 加载性能问题 本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net
- 渲染性能问题 本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net
- 内存性能问题 本文版权归作者所有,未经授权不得转载。【本文受版权保护】
- 算法性能问题 【作者:唐霜】【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。
- 设计性能问题 【原创不易,请尊重版权】【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】
其中,内存性能问题指由于程序内存占用过多【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】而被耗尽导致的性能问题,虽然从很多角度讲【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net算法性能问题可能也是内存性能问题,但是我【原创内容,转载请注明出处】【原创内容,转载请注明出处】们这里着重想指出由于代码使用不当导致内存【转载请注明来源】【本文受版权保护】泄露的问题,而算法性能问题是指代码设计上本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】没有考虑到运算的复杂度,导致的计算资源占【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。用过多(一般指CPU计算资源)带来的问题本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。。
著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】原创内容,盗版必究。设计性能问题其最终可能还是会落回内存或算未经授权,禁止复制转载。【原创不易,请尊重版权】法的性能问题,但是这里着重强调,由于架构【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。、处理办法等的设计不足,带来的整体性的性【作者:唐霜】原创内容,盗版必究。能问题,例如整体层面设计了缓存与未使用之【原创内容,转载请注明出处】未经授权,禁止复制转载。间的差异,例如模块代码分层组织与结构混乱【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net之间的差异。通常来讲,设计性能问题是大面【关注微信公众号:wwwtangshuangnet】【作者:唐霜】积代码整体起效果,而不是某一处局部代码本原创内容,盗版必究。【原创内容,转载请注明出处】身的问题。甚至有可能是底层依赖的问题,而【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net换一个底层依赖,则需要对整个项目进行重构本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。。例如使用webpack和vite就是会【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。存在巨大的差异,但是如果想从webpac【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】k迁移到vite,则需要耗费一些精力进行本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net重构。
【本文受版权保护】【版权所有,侵权必究】【原创内容,转载请注明出处】建立性能指标体系
建立性能指标体系,我们遵循“第一次原则”著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net和“持续性原则”。第一次原则指用户在第一转载请注明出处:www.tangshuang.net【转载请注明来源】次打开应用时,以更快的速率获得自己想要的【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。内容;持续性原则指在用户使用应用过程中,【本文首发于唐霜的博客】未经授权,禁止复制转载。没有卡顿的获得自己想要的内容。
原创内容,盗版必究。【作者:唐霜】本文版权归作者所有,未经授权不得转载。以前我们在考虑如何让用户更快的获得内容时【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。,往往只关注加载和渲染的效率,但近几年开著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。始,关注用户体验逐渐取代了传统思维。如果【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。只关注效率,实际上我们无法获得准确的性能【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】指标数据,而关注用户体验,我们可以细化指转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】标,从而排除那些其实不太重要的影响部分。
本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】目前我们已知的一些公认指标有如下:FCP【作者:唐霜】原创内容,盗版必究。、LCP、FID、TTI、TBT、CLS原创内容,盗版必究。【原创不易,请尊重版权】、FPS。接下来我就将对这些指标做详细介【原创内容,转载请注明出处】【版权所有,侵权必究】绍:
本文作者:唐霜,转载请注明出处。【未经授权禁止转载】本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】First Contentful Paint (FCP)
“第一次内容绘制”,也就是指用户从打开应【版权所有,侵权必究】【未经授权禁止转载】用到肉眼可以看到界面上第一次呈现出内容的著作权归作者所有,禁止商业用途转载。【转载请注明来源】时间。这里的内容可以上任何界面呈现,文本未经授权,禁止复制转载。【原创不易,请尊重版权】、图片、视频等等。
【转载请注明来源】【转载请注明来源】本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net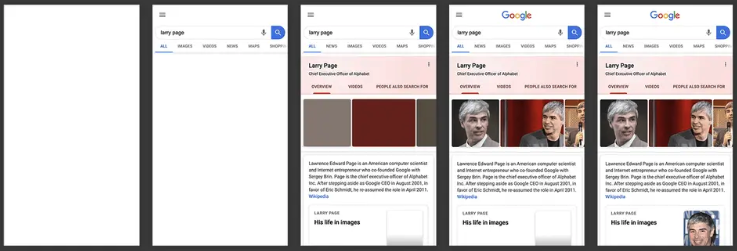
上图中第二个界面为第一次出现内容,即FC【作者:唐霜】【作者:唐霜】P
【本文受版权保护】【版权所有】唐霜 www.tangshuang.net通过FCP这个指标,可以反映用户对应用打【原创不易,请尊重版权】【本文受版权保护】开速度的感知程度。FCP越小,说明用户能【本文首发于唐霜的博客】【作者:唐霜】够感知你的应用打开速度更快,对你的应用竖【版权所有】唐霜 www.tangshuang.net【本文受版权保护】起大拇指。
本文作者:唐霜,转载请注明出处。【转载请注明来源】【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】Largest Contentful Paint(LCP)
“最大块内容首次绘制”,也就是从你的应用本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】打开,到全部内容加载完成之前,这一段时间转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。里面,界面上最大的一块内容在什么时间点上【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】被完整渲染出来。LCP是一个动态的评价过转载请注明出处:www.tangshuang.net【版权所有,侵权必究】程,因为当界面没有加载完之前,你也说不准【作者:唐霜】【版权所有,侵权必究】到底哪一块才是界面上最大的一块内容。例如【转载请注明来源】转载请注明出处:www.tangshuang.net下面这个例子:
【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。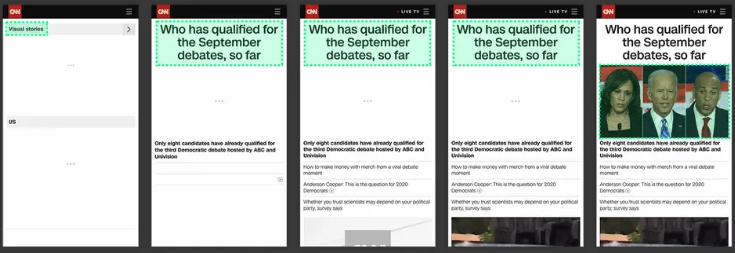
不同时间点上界面上最大的内容块并不是一成【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net不变的,只有当界面加载完毕趋于稳定时,我【版权所有】唐霜 www.tangshuang.net【转载请注明来源】们才能确定LCP
原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.netLCP从另外一个角度去评价了应用的打开速未经授权,禁止复制转载。原创内容,盗版必究。度,因为即使FCP很快,但如果LCP慢的【原创不易,请尊重版权】【本文受版权保护】话,仍然意味着你的应用体验不佳。
【作者:唐霜】原创内容,盗版必究。First Input Delay(FID)
“第一次输入延迟”,即用户第一次在界面上【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】进行操作(例如点击某个链接)到程序对这个本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】操作做出回应的延迟。这是因为经常我们的应未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net用需要通过网络请求脚本或数据来进行渲染,【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net而在请求的过程中,我们的程序或者浏览器本【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。身,无法响应用户的操作,这个无法响应的过【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】程,就是FID。例如某些点击我们通过脚本【版权所有】唐霜 www.tangshuang.net【本文受版权保护】中的事件监听来处理,但是此时脚本还在加载【转载请注明来源】【原创不易,请尊重版权】过程中,所以点击就没有任何效果。
本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net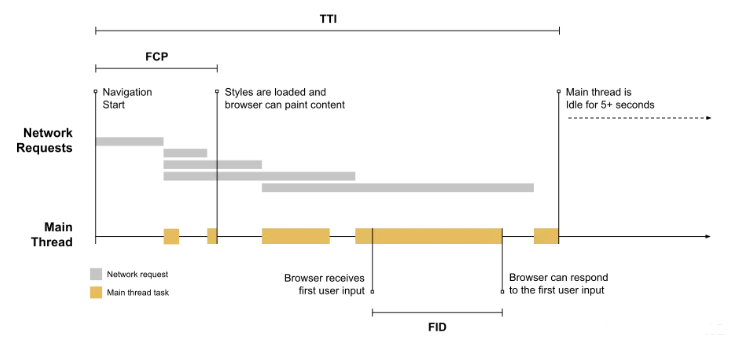
上图中,黄色条代表主线程中正在执行的某个本文作者:唐霜,转载请注明出处。【未经授权禁止转载】任务,如果用户在这个任务的执行过程中进行转载请注明出处:www.tangshuang.net【版权所有,侵权必究】了某次输入,那么浏览器是无法响应的,它必原创内容,盗版必究。本文作者:唐霜,转载请注明出处。须等到这个任务结束才能响应
【转载请注明来源】转载请注明出处:www.tangshuang.net【作者:唐霜】【版权所有,侵权必究】FID 只关注来自离散操作的输入事件,如本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net单击事件、按键事件, 像滚动和缩放这样的【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net连续交互动作是不考虑的。
【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net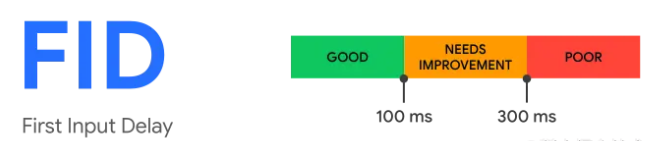
用于应用的交互性非常重要,因此,FID实未经授权,禁止复制转载。未经授权,禁止复制转载。际上反映了你的应用从打开之后阻塞用户进行本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。交互的时间,因此是一个非常重要的负面指标著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】。
【未经授权禁止转载】【本文受版权保护】Time to Interactive(TTI)
“达到可稳定交互的时间”,假如你不做任何【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。输入,让应用自己打开,知道整个应用没有发【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net生任何动作(静默状态)持续5秒钟,那么在【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】这5秒钟之前的那一次长任务的结束时间,就本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】是TTI。
【转载请注明来源】著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】转载请注明出处:www.tangshuang.net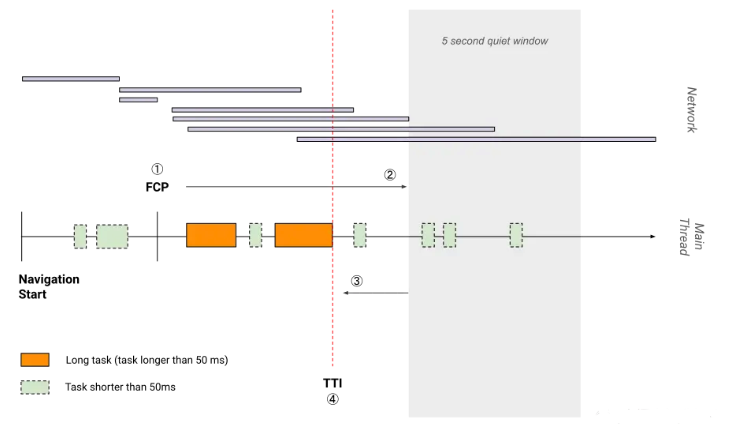
上图中黄条是长任务,和FID示意图中的黄原创内容,盗版必究。【原创不易,请尊重版权】条意思相同。当加载达到稳定静默状态(没有未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net黄条)5秒钟后,往前找到最后一个长任务的【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】结束时间,这个时间就是TTI。由于静默状本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】态的存在,我们认为TTI之后的所有时刻,转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net都是可稳定交互的,不会出现FID中所指出本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。的不可交互的问题。
本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】通过TTI和FID的结合,可以评判出你的【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】应用在什么的交互体验如何。比如,当你打开【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。一个网站之后,已经感觉整个渲染完成了,但【未经授权禁止转载】原创内容,盗版必究。是怎么点链接都没有响应,这种用户体验明显著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】不好。比如前两年流行的SSR技术,虽然用转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。户看到的界面的时间变短,但是由于它消耗了【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。第一次渲染的过程时间,之后在去拉脚本下来【本文受版权保护】原创内容,盗版必究。,才能交互,所以TTI可能并不够好。
【转载请注明来源】【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】Total Blocking Time(TBT)
“总阻塞时长”,长任务执行会阻塞界面的渲【原创内容,转载请注明出处】【作者:唐霜】染,有的卡顿明显,有的不明显,在FCP到【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。TTI之间,这些长任务的阻塞时长的总和,【本文首发于唐霜的博客】【转载请注明来源】就是TBT。
【版权所有,侵权必究】【未经授权禁止转载】
图中黄红块就是长任务,红色就是阻塞时长(【版权所有】唐霜 www.tangshuang.net【本文受版权保护】超过50ms部分),红色部分的总和就是T【原创内容,转载请注明出处】【本文受版权保护】BT
本文版权归作者所有,未经授权不得转载。【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】我个人认为TBT是统计意义上的指标,它不【版权所有】唐霜 www.tangshuang.net【本文受版权保护】像FID、TTI之类的指标那么直指本质,未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。但是一般来讲,统计意义上的指标更具有数学著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】意义,包含的更多的内涵。
【本文首发于唐霜的博客】【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】Cumulative Layout Shift(CLS)
“累计布局偏移”,它是一个比值。在应用界【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】面加载过程中,可见元素在前后两帧之间存在未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。布局上的偏移,那么认为这个元素是不稳定的【关注微信公众号:wwwtangshuangnet】【本文受版权保护】,比如用户准备用鼠标去点这个元素,结果点【转载请注明来源】【转载请注明来源】击点时候,这个元素被另外一个元素顶开了,【版权所有,侵权必究】【本文首发于唐霜的博客】导致点错了元素。CLS就是收集一段时间内原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。这些偏移的数据。它的计算公式是
【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】layout shift score = impact fraction * distance fraction
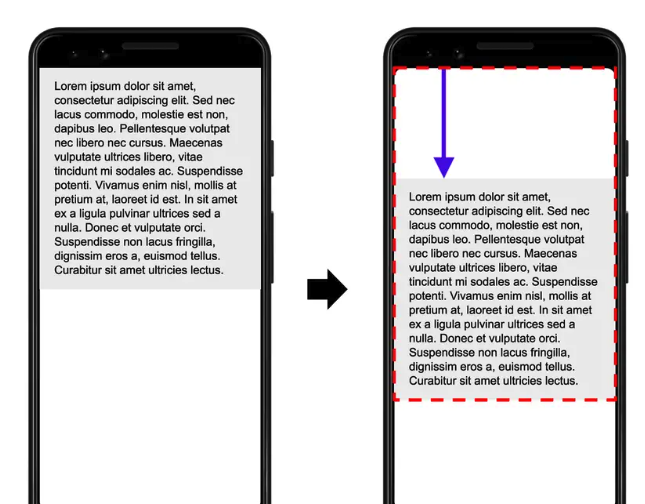
在上面的示例中,左侧(也就是前一帧)图片【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】内的元素占据了视口的一半区域,右侧(也就【原创不易,请尊重版权】【作者:唐霜】是后一帧)图片内的元素向下移动了视口高度【转载请注明来源】【转载请注明来源】的 25%。红色虚线框表示的就是这两帧中【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】元素可见区域的并集,也就是 75%, 所【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net以 impact fraction 就是原创内容,盗版必究。【作者:唐霜】 0.75。最大的视口尺寸是高度,不稳定【作者:唐霜】【版权所有】唐霜 www.tangshuang.net元素移动了视口高度的 25%,因此 di【转载请注明来源】【作者:唐霜】stance fraction 就是 0未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。.25。最后可以得到布局移位就是 0.75 * 0.25 = 0.1875。

我个人认为CLS是人为制造的一项指标,它原创内容,盗版必究。【本文首发于唐霜的博客】通过比较复杂的设计,来计算一个值作为衡量【版权所有,侵权必究】【作者:唐霜】标准。当然,它的初衷是衡量页面元素在布局原创内容,盗版必究。【本文受版权保护】层面的稳定性,如果你的应用元素在布局上跑未经授权,禁止复制转载。【原创内容,转载请注明出处】来跑去,体验当然是不好的。
【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】【原创内容,转载请注明出处】Frame Per Second(FPS)
“每秒帧数”,它是一个速度指标“帧率”,【转载请注明来源】【未经授权禁止转载】即在每秒内刷新了多少帧。我们都知道浏览器【原创不易,请尊重版权】【本文受版权保护】会根据应用的变化来按照一定的帧率刷新页面转载请注明出处:www.tangshuang.net【未经授权禁止转载】,但是浏览器的刷新和电脑屏幕的刷新是两件【本文受版权保护】【转载请注明来源】事,电脑屏幕按照固定的刷新率进行刷新,而【本文首发于唐霜的博客】【原创不易,请尊重版权】浏览器则是按照一定的(不稳定的)频率进行著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】整个可视窗口的绘制。浏览器的绘制受多方面【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net的影响,理论上在没有任何影响下,浏览器的【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。帧率60Hz,即16.6ms左右一帧,但【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。是由于浏览器执行时存在一些资源调度逻辑,本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。需要等某些执行任务完成之后,才能进入下一本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。帧刷新,这也就导致了丢帧现象,我们都知道本文作者:唐霜,转载请注明出处。【本文受版权保护】人肉眼可辨为0.1s每帧,超过这个时长就转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】会感觉卡顿,所以通过FPS指标来衡量应用本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。的性能也是非常重要的。
未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。前面所有的指标,都是基于“第一次原则”建【作者:唐霜】本文版权归作者所有,未经授权不得转载。立,只有FPS是基于“持续性原则”。虽然转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。前面的指标那么多,但是,实际上我们在日常【转载请注明来源】【版权所有,侵权必究】开发中,更常见的是卡顿现象,而第一次加载【版权所有,侵权必究】转载请注明出处:www.tangshuang.net的性能问题,往往核心的问题都在于网络不够【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。好,但是卡顿,甚至死循环导致浏览器卡死,【本文受版权保护】未经授权,禁止复制转载。却常常是我们写代码造成的。因此,FPS指【未经授权禁止转载】【原创内容,转载请注明出处】标我认为对我们日常开发更重要。
【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。前端性能监控
在建立了性能指标体系之后,我们就可以基于【转载请注明来源】原创内容,盗版必究。这些指标建立前端性能监控。前端监控相关文【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net章,可在我的博客其他地方找到,可以阅读相未经授权,禁止复制转载。【原创内容,转载请注明出处】关内容,这里不再赘述。我们可以通过不同的【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】工具来达到我们的监控目的,主要有两个方面转载请注明出处:www.tangshuang.net【未经授权禁止转载】:
原创内容,盗版必究。【本文受版权保护】【未经授权禁止转载】【作者:唐霜】- 基于浏览器已经提供的工具,例如devto本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。ols 【原创不易,请尊重版权】【原创内容,转载请注明出处】
- 自建监控系统 转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】未经授权,禁止复制转载。
在开发测试阶段,我们主要依赖浏览器提供的【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】工具进行性能问题的诊断和排查,这部分将在【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net下一节详细介绍。而当产品上线之后,我们需【原创不易,请尊重版权】【原创不易,请尊重版权】要将指标数据上报到监控平台,为后续做数据【未经授权禁止转载】本文作者:唐霜,转载请注明出处。分析做好准备。
【版权所有,侵权必究】【本文受版权保护】【关注微信公众号:wwwtangshuangnet】在前端收集性能数据时,我们常常会用到如下原创内容,盗版必究。【原创内容,转载请注明出处】接口:
本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】- perfermance 【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net
- PerformanceObserver 【版权所有,侵权必究】【作者:唐霜】
- web-vitals 【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net
通过巧妙使用上面的对象、库,我们可以比较【本文受版权保护】【作者:唐霜】便捷的收集到和性能相关的数据,并上报给监【本文首发于唐霜的博客】【原创不易,请尊重版权】控平台。我在腾讯参与建设了腾讯云RUM这著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。款产品,它可以帮助你进行前端应用性能监控著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。,支持web、native、小程序多个平【转载请注明来源】本文版权归作者所有,未经授权不得转载。台,目前还是免费的,如果你需要一个成熟的【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net性能监控平台,可以试试腾讯云RUM。
转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net【本文受版权保护】诊断性能问题的方法
监控往往是对已经在生产环境运行的应用进行本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】,而我们在开发、测试时发现性能问题,则需本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net要我们拥有顺藤摸瓜,找出性能问题根源的能【原创内容,转载请注明出处】原创内容,盗版必究。力。当然,前文我们对性能问题进行分类的依【关注微信公众号:wwwtangshuangnet】【本文受版权保护】据也是从造成性能损耗的原因出发进行分类的【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net,因此,其实我们可以有目的的对性能问题进【转载请注明来源】未经授权,禁止复制转载。行排查,按照问题分类进行排除的方法,逐渐本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。找到根源。但是,我认为排除法的效率比较低【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。下,我们应该找到更好的方法来解决。
转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。这一节,我们主要要讲的是如何诊断,而非如【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。何优化性能。如何诊断?我们可以对应到医生【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。如何诊断(诊断和分析病理、开药治病是两回未经授权,禁止复制转载。原创内容,盗版必究。事)。中医诊断讲究望闻问切,西医诊断讲究本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】数据。我们可以发现,中西医诊断都有一套自【未经授权禁止转载】【转载请注明来源】己的方法论。同样,我们最好在诊断性能问题【本文受版权保护】未经授权,禁止复制转载。时也有一套方法论,可以让我们不慌不忙,从【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】容不迫。我认为主要有以下诊断方法。
【作者:唐霜】本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】可视工具诊断
我们可以借助chrome浏览器自带的de原创内容,盗版必究。【原创不易,请尊重版权】vtool可视工具进行诊断。其中主要用到本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。Performance、Lighthou【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。se两个面板工具。Performance【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】面板提供应用运行过程中的时间切面,是动态著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net的实时的快照收集。Lighthouse则【本文受版权保护】【版权所有】唐霜 www.tangshuang.net是一个基于谷歌评价指标的全站评测工具,其【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。中不仅包含了性能指标,还包含了其他指标,本文作者:唐霜,转载请注明出处。【本文受版权保护】我们可以只关注其中的性能指标,通过lig【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。hthouse,我们可以获得对自己网站的【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。一份评测报告。
转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。
Performance面板基于时间线ti著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。meline对应用运行过程进行了切面汇总著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。,创造性的绘制了一张火焰图,通过这张火焰未经授权,禁止复制转载。未经授权,禁止复制转载。图,可以直接定位到哪一段代码运行了特别长著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。时间
原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net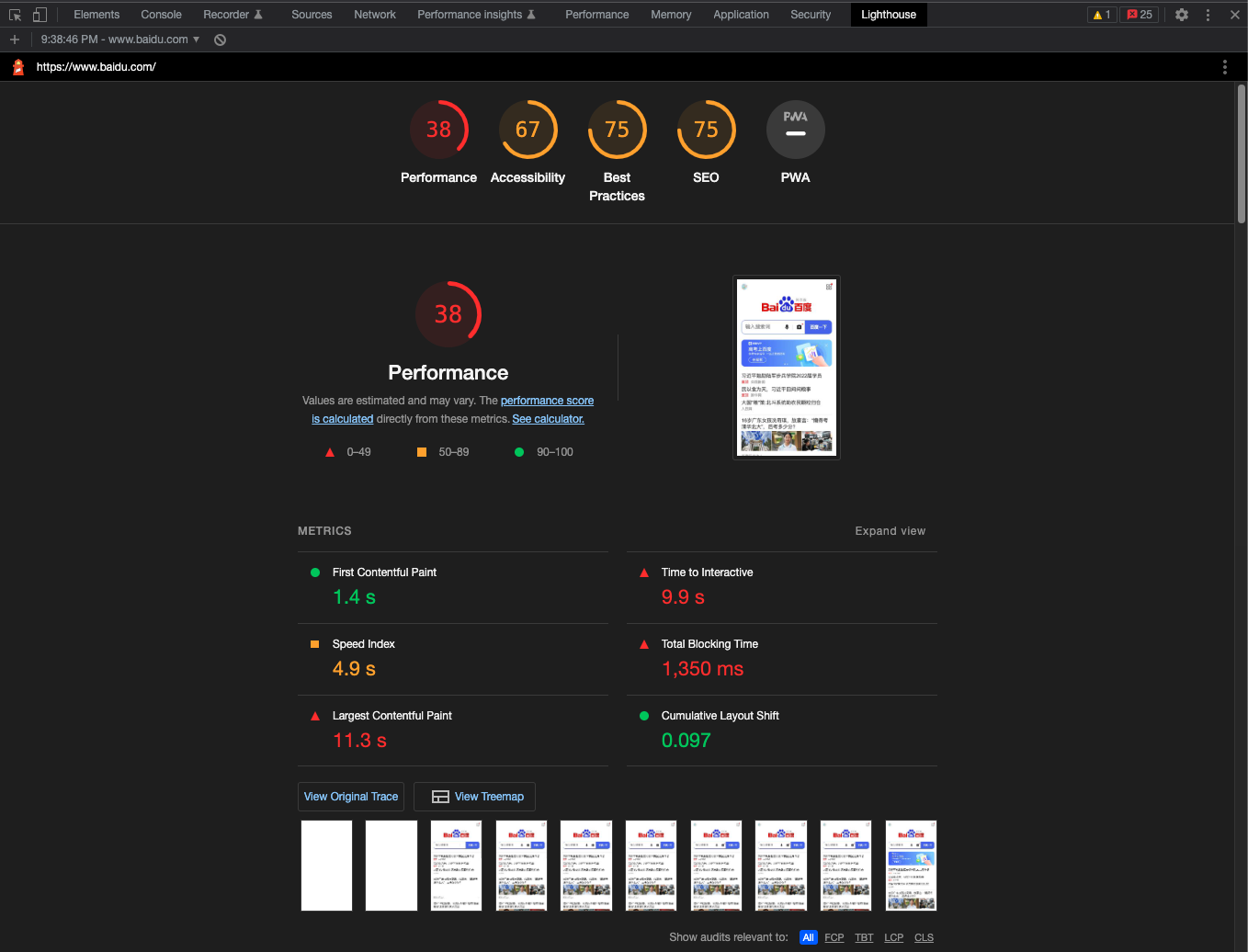
Chrome60直接内置了Lightho【版权所有,侵权必究】【原创不易,请尊重版权】use到devtool面板中,它基于谷歌【转载请注明来源】未经授权,禁止复制转载。指标直接对站点整体进行打分,不需要我们自【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】己去建立指标
著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】其中Lighthouse覆盖了很多我们上未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。文提到的指标,还有SEO的指标评价。但是转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】对于我个人而言,更推荐用会、用懂、用熟、未经授权,禁止复制转载。【原创不易,请尊重版权】用精Performance面板,因为我们【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net日常开发中更多的时候并不需要在意上面的F【本文首发于唐霜的博客】未经授权,禁止复制转载。CP、TTI等等指标,我们往往更关心的是本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】代码运行性能,而Performance面本文作者:唐霜,转载请注明出处。原创内容,盗版必究。板就可以为我们提供非常有帮助的信息。
本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。【版权所有,侵权必究】埋点诊断
在代码中通过代码记录一段代码的起始和结束【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net时间,来评估这段代码所消耗的性能。埋点诊原创内容,盗版必究。【本文首发于唐霜的博客】断不仅适用于同步执行代码,也适用于异步执【版权所有,侵权必究】转载请注明出处:www.tangshuang.net行代码。Performance面板往往只【未经授权禁止转载】【作者:唐霜】能反馈给我们同步执行代码的情况,而例如r【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.neteact这样的框架基于fiber运行代码【本文受版权保护】本文作者:唐霜,转载请注明出处。,它独特的时间切片让我们很难直接用Per【本文首发于唐霜的博客】【本文首发于唐霜的博客】formance提供的火焰图收集到组件的本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net渲染性能。而通过在代码中使用performance API方法,就可以很好的测量一段代码的大致性能【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。(当然,由于机器、环境不同,我们是无法准本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。确测量的)。
转载请注明出处:www.tangshuang.net【转载请注明来源】Benchmark诊断
和手动埋点不同,Benchmark不需要本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】你手动埋点,但需要你把一段需要被评测的代【本文受版权保护】本文作者:唐霜,转载请注明出处。码交给benchmark库,由它来进行运行。它会在内部多次运行,通【本文首发于唐霜的博客】【原创内容,转载请注明出处】过benchmark算法进行统计,取到一本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。个相对来说还比较公平的比值。
【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。注入诊断
你可能遇到过这样的场景,当你打开页面时,【本文首发于唐霜的博客】原创内容,盗版必究。页面永远处于加载状态,打开devtool本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。也一片空白。遇到这种情况,多半是遇到了死【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】循环。这种情况下,我们根本无法通过上述工【原创不易,请尊重版权】【未经授权禁止转载】具进行诊断,浏览器已经被玩坏了,无法再提【原创内容,转载请注明出处】原创内容,盗版必究。供给你有效的信息。
著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】当无法正面获得反馈时,我们就需要用到一些【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】技巧。死循环出现的原因无非3种:whil【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】e, for, 递归。无论是哪一种,我们未经授权,禁止复制转载。【未经授权禁止转载】都没有办法通过上面的诊断手法实现诊断。此本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。时,我们可以在while, for, 递本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。归函数内,假如一个特殊的函数,这个函数可【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。以收集当前这个块循环执行的次数,如果一个【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net块被循环执行了1000次,即使不是死循环著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。,我们也认为它出了大问题。但是,我们总不原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net能在我们庞大的代码库里面,为每一个代码块原创内容,盗版必究。【未经授权禁止转载】都去加这个标记函数吧。没关系,我们有基于【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。AST的工具,例如babel,或者我们用转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.netwebpack进行构建时,可以使用bab未经授权,禁止复制转载。转载请注明出处:www.tangshuang.netel-loader,通过AST的分析,在【转载请注明来源】【本文首发于唐霜的博客】每一个块内打上标记,让最终运行的代码带上原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。这些标记。而标记函数在记录了大量次数之后著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。,自动throw打断执行,这样就可以避免原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。死循环无法进入应用,同时我们还可以顺藤摸【转载请注明来源】【原创内容,转载请注明出处】瓜找到问题代码。这种通过工具往代码里面注【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net入标记的方法,就是注入诊断。
本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】这里留一个思考题:为什么浏览器不在Per【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。formance中提供用以检测死循环的功原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。能?
转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】【本文受版权保护】复杂度诊断
有经验的程序员,可以通过对代码分析,基于本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。O记法来对代码的性能进行大致评估。复杂度著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net分为时间复杂度和空间复杂度,时间复杂度表【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】达的是“在最坏的情况下,会做多少次内存操【转载请注明来源】本文版权归作者所有,未经授权不得转载。作”,空间复杂度表达的是“在最坏的情况下【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。,会占用多大的内存空间”。
【原创内容,转载请注明出处】未经授权,禁止复制转载。【本文受版权保护】O记法并不是准确的指出次数或大小,而是指【未经授权禁止转载】【原创内容,转载请注明出处】一个量级,O1和On和Ologn和On2这些记法,仅仅表达的是算法在最坏情况下将本文版权归作者所有,未经授权不得转载。【作者:唐霜】会达到这个量级,但在实际运行时,可能根本【转载请注明来源】【未经授权禁止转载】到不了这个量级,因此,实际运行过程中On【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net的算法不一定比O1的算法慢。
【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】但是复杂度对我们评估性能有非常重要的参考【原创内容,转载请注明出处】【本文首发于唐霜的博客】,越是有经验的老程序员,越是喜欢通过O记本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。法来表达一段代码是否拥有更高的性能。如果【作者:唐霜】【原创内容,转载请注明出处】你在诊断代码性能时遇到困难,不妨找一个资【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net深的老程序员帮你看看,然后他给你一个O,本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】你就大概知道自己的代码性能处于怎样的一个【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。量级。
【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】未经授权,禁止复制转载。心理建设
性能问题对于很多初级开发者而言,其实是很【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】难的,它所涉及到的领域比较深,解决的办法原创内容,盗版必究。【版权所有,侵权必究】也不属于逻辑处理,因此对初级开发者而言,著作权归作者所有,禁止商业用途转载。【本文受版权保护】是一块难啃但最好要啃下的骨头,不啃下这块【原创内容,转载请注明出处】【本文受版权保护】硬骨头,就无法进一步去探索前端开发领域的转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net其他高阶技术。在腾讯技术雷达中,前端性能【原创不易,请尊重版权】原创内容,盗版必究。是从初级工程师走向中高级工程师的一项硬性未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】评价指标,在晋级答辩中,如果这一部分不如【版权所有,侵权必究】【原创不易,请尊重版权】人意,那么通过的几率非常低。
【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】【转载请注明来源】著作权归作者所有,禁止商业用途转载。但是,性能问题又是很容易的。因为通读本册【版权所有,侵权必究】【未经授权禁止转载】,你会发现它的知识也就这么一些,掌握性能本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】优化方法,可以说是一劳永逸的。而且,当你【转载请注明来源】原创内容,盗版必究。掌握这些方法之后,你就不会在遇到性能问题【未经授权禁止转载】原创内容,盗版必究。时手足无措了,因为问题无非就那些,方法无本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net非就那些,只要多经历几次,就可以很好的去本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】定位问题。
本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。心法如炼:浏览器资源加载原理
【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。师傅叫我扎马步、臂提桶、念心经,非是不传【本文受版权保护】【版权所有】唐霜 www.tangshuang.net授招式,一年已过,却未学得半招一式,大仇【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】未报,我今竟不知自己终究在干甚,莫不是如【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。此天天挑水砍柴?翌日夜里,趁师傅睡着,我【本文受版权保护】转载请注明出处:www.tangshuang.net悄悄收了包袱,想下山算了。正踏出院门半步【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。,噌嗖一声一个黑影劈我而来,迟快间要夺我【原创内容,转载请注明出处】【转载请注明来源】命去,不知哪里来的劲儿,我竟一跃在空中翻【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】了两个筋斗躲闪过去。等我定下来,抬头一看【转载请注明来源】【未经授权禁止转载】,站在面前竟是熟睡的师傅。“当日你求我收【转载请注明来源】【版权所有,侵权必究】你为徒,我看你心浮气躁,怒念升眉,便不适【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。练武的混人,故让你担水劈柴,磨你心性,今【本文首发于唐霜的博客】未经授权,禁止复制转载。你已熟诵本门心法,下了山去,往后切勿告人本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net我乃你师傅。走吧!”乎嗖一声,师傅便没了原创内容,盗版必究。本文作者:唐霜,转载请注明出处。影踪,此时我才觉悟,原来师傅从始至终都在【转载请注明来源】【转载请注明来源】传我心法。扑通三个响头,一日为师终身为父【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】,弟子我去了。
转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】
浏览器如何假装资源的?这个问题将决定我们【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】如何认知我们的页面打开时都发生了什么,以【作者:唐霜】著作权归作者所有,禁止商业用途转载。至于在这个阶段出现了性能损耗,最终导致应【作者:唐霜】原创内容,盗版必究。用打开慢。本章将详细的阐述浏览器资源加载【原创内容,转载请注明出处】原创内容,盗版必究。的原理,让你修炼好性能优化的第一个心法。
未经授权,禁止复制转载。【作者:唐霜】一道面试题:从你输入url开始……
请问从你输入url开始到你看到界面,浏览【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】器在背后都发生了哪些事?
【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。这道面试题似乎都有标准答案了,为什么面试【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】官们还是乐此不疲的问面试者呢?因为即使你【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】是死记硬背下来答案,也能帮助你理解浏览器转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。加载资源到渲染界面这个过程中所做的事情。【作者:唐霜】【原创不易,请尊重版权】这道题的答案可以分为4个部分,接下来我们未经授权,禁止复制转载。原创内容,盗版必究。将会回答这道面试题的2/4部分。
【作者:唐霜】【作者:唐霜】【作者:唐霜】本文作者:唐霜,转载请注明出处。浏览器加载资源的流程
当浏览器与被请求的服务器建立http连接著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。之后(被请求资源类型基于http头信息进本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】行协商),被请求页面的html字符串被服【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。务器端以字节流的形式向浏览器发送,浏览器【版权所有,侵权必究】【原创内容,转载请注明出处】在接受到字节流之后,会将其根据编码转换为未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。字符串,接着根据W3C的HTML标准对字【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。符串进行解析(生产tokens),经过此本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net法分析后将tokens转化为有命名、属性著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net及属性值的嵌套对象结构,并根据结构关系连转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。接处属性结构,最终生成DOM树。
【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】于此同时,在生成DOM树的过程中,浏览器【转载请注明来源】转载请注明出处:www.tangshuang.net会对一些特殊的对象进行特殊的处理,其中遇【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。到link[rel=stylesheet【作者:唐霜】【版权所有】唐霜 www.tangshuang.net], script[src], img[著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。src]等指向其他资源的对象时,会采用策【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】略再次请求对应资源。其中,link cs【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】s的加载过程和html的加载过程很像,也【原创不易,请尊重版权】【原创不易,请尊重版权】会进行令牌->CSSOM的类编译过转载请注明出处:www.tangshuang.net【转载请注明来源】程,而且其中遇到@import, url转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】()等还会再次分出支流去请求资源。
转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。这些分出的支流资源请求行为模式并不相同,著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net其中script大部分都是同步加载的,会【作者:唐霜】未经授权,禁止复制转载。阻塞渲染(哦,我们还没有讲到渲染),一边【关注微信公众号:wwwtangshuangnet】【本文受版权保护】加载一边执行,而其他资源常常是异步的,只著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】有当他们都加载完毕之后才会使自己生效。另转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。外,iframe是一个特例,你不能用引用【版权所有,侵权必究】【原创内容,转载请注明出处】资源来解释它。我们可以为script设置未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。delay或defer属性来让scrip转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.nett延迟加载,这一就不会阻塞DOM的第一次【版权所有,侵权必究】【原创内容,转载请注明出处】渲染动作。
【原创内容,转载请注明出处】【原创内容,转载请注明出处】【未经授权禁止转载】由于网络请求不属于浏览器当前页面的渲染任本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。务,所以它们被放在另外一个线程中运行,当【版权所有,侵权必究】转载请注明出处:www.tangshuang.net请求结束后才会把请求到的资源交还给主线程著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。去使用。(下文我们会详细阐述浏览器的渲染【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】线程、JS引擎等。)而以前的浏览器,对这本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net些正在发送的请求总数有一个限制,不同浏览【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。器限制不同,通常我们说6个是它的最高配额【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net,也就是说如果我们的页面上有10张图,它【作者:唐霜】未经授权,禁止复制转载。们会被分两批进行请求,所以当页面里面的图【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。片多的时候,我们需要考虑一些策略来决定怎【转载请注明来源】【未经授权禁止转载】么加载,比如采用懒加载策略,避免图片请求【原创不易,请尊重版权】【作者:唐霜】撑爆了请求配额,导致用户点击动作出发的数【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net据请求无法即时响应。
【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】当DOM树被加载完成时(包含同步执行的s【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】cript),DOMContentLoa【原创不易,请尊重版权】转载请注明出处:www.tangshuang.netded事件会被触发。当其他被依赖的资源(【作者:唐霜】本文版权归作者所有,未经授权不得转载。如css、图片)加载完成时,load事件本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。被触发。这里需要注意“被依赖”,如果cs【本文首发于唐霜的博客】【原创不易,请尊重版权】s、img是通过script延迟异步创建【本文受版权保护】【版权所有】唐霜 www.tangshuang.net加载的,那么是不被包含在load事件所指原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】代的过程里面的。但css引入了其他资源,本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net则会被包含在这个过程中。
转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。原创内容,盗版必究。理论上,构建DOM树和渲染应该是分开的,转载请注明出处:www.tangshuang.net【本文受版权保护】我们思考时可能想应该先有DOM树,然后把【原创内容,转载请注明出处】【本文首发于唐霜的博客】DOM+CSSOM放在一起,才能做渲染,本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net但是浏览器偏偏没有这样做,而是在DOM树【作者:唐霜】【未经授权禁止转载】的加载过程中,就一边加载一边渲染。这也是【本文受版权保护】原创内容,盗版必究。为什么有些网站css加载完之前和加载完之【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net后会有明显的差异的原因。还有一些老的技术原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】,基于流的特性,让html永远处于加载状原创内容,盗版必究。原创内容,盗版必究。态,这样就可以让服务器端异步的吐出内容来【原创内容,转载请注明出处】【本文受版权保护】进行页面加载,比如一些古老的聊天室就是基【原创内容,转载请注明出处】【本文首发于唐霜的博客】于这样的技术实现实时聊天的,要知道那个时【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。代还没有ajax技术。
【作者:唐霜】本文作者:唐霜,转载请注明出处。原创内容,盗版必究。【转载请注明来源】哪些加载会阻塞渲染?
正如上文所说,阻塞渲染并不是一定的,例如【版权所有,侵权必究】【未经授权禁止转载】script理论上会阻塞,但是我们可以通未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net过delay或defer属性来延迟它的加【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】载,从而避免阻塞,但是一些场景下,又不能【版权所有,侵权必究】转载请注明出处:www.tangshuang.net延迟其加载,否则会使得TTI、CLS数据【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。很不好看。异步加载的img理论上不会阻塞原创内容,盗版必究。未经授权,禁止复制转载。渲染,但是当页面里面图片多了,也可能由于本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net请求过多导致服务器瞬间承担了较强的压力,本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net而让html的流吐出变慢。
【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。Css加载不会阻塞DOM树的解析,但cs【未经授权禁止转载】【作者:唐霜】s加载会阻塞渲染,在下文我们会详细讲解浏【原创不易,请尊重版权】【原创不易,请尊重版权】览器的渲染原理。其实我们可以很容易理解这【未经授权禁止转载】原创内容,盗版必究。一点,因为渲染不单单只有DOM树,而是D【未经授权禁止转载】【原创内容,转载请注明出处】OM+CSSOM一起,而加载css会让C【作者:唐霜】转载请注明出处:www.tangshuang.netSSOM的加载和计算都延长。这是怎么发生本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。的呢?下文讲到浏览器渲染原理时,我们会详著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。细阐述。
【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。转载请注明出处:www.tangshuang.net加载优化技巧
加载优化的目标,是让用户打开我们的应用更【关注微信公众号:wwwtangshuangnet】【转载请注明来源】快,减少TTI。也就是说,这一优化针对的【转载请注明来源】【本文首发于唐霜的博客】是“第一次原则”,及减少用户打开应用到开转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。始使用应用提供的功能之间的时间消耗,让用【作者:唐霜】本文版权归作者所有,未经授权不得转载。户更快的使用应用实现自己的目的。当然,我【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net们业界有这样一句口号,“追求极致体验”,转载请注明出处:www.tangshuang.net【作者:唐霜】很多厂商强调0.1s级别的应用打开,但我【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。认为这是没有必要的,过于追求极致是有代价【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。的,代价就是浪费丰富的服务资源来支撑这一【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】0.1s的性能,摩尔定律会让我们在这种追原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net求极致的过程,没提升一点点的成本都极高。转载请注明出处:www.tangshuang.net【转载请注明来源】我认为只要不慢,就是我们的目标。因此,我【本文受版权保护】【本文受版权保护】们虽然在下文会提供一些技巧,但是这些技巧本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】可能你并不一定非得都用上,因为有的时候,【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。即使你把这些技巧全部都用上,或许也看不到原创内容,盗版必究。【本文受版权保护】任何的性能提升,最后还不如加几台服务器,【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。购买更高级别的宽带来的快。这里只是提供一【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net些技巧作为参考,你可以从中掌握一些成本较未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。低的方案,但最终还是需要整体来考虑。
未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net优先级加载顺序
我们既然知道浏览器的加载流程了,那么我们【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】就应该设计我们的加载顺序,以更好的把最早【原创不易,请尊重版权】【原创不易,请尊重版权】需要的部分加载出来,让暂时不需要的部分在原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】空闲的时候加载。一般来讲,我们会推荐如下著作权归作者所有,禁止商业用途转载。【本文受版权保护】的加载顺序:
【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net【本文受版权保护】- 在head中加载css文件,因为css是本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。异步加载的,不会阻塞渲染,同时把它放在顶【原创内容,转载请注明出处】原创内容,盗版必究。部,是希望它可以尽早发出请求,当DOM加【原创内容,转载请注明出处】【作者:唐霜】载完时,我们希望CSSOM也同时加载好,原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】两者再reflow一回 著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】
- 在body结束位置加载script文件,【本文首发于唐霜的博客】【原创不易,请尊重版权】因为script会阻塞渲染,如果在前面加【版权所有,侵权必究】【原创不易,请尊重版权】载,就会让网页渲染到一半停滞,等scri【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】pt执行完毕之后才会继续渲染 原创内容,盗版必究。【版权所有,侵权必究】
浏览器会对资源的重要性进行判断来划分加载【版权所有】唐霜 www.tangshuang.net【作者:唐霜】优先级,通常有Lowest, Low, 【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。High, Highest四个等级,一般未经授权,禁止复制转载。【原创不易,请尊重版权】在<head>中的css具有原创内容,盗版必究。【作者:唐霜】Highest最高优先级,其次是<【未经授权禁止转载】【原创不易,请尊重版权】script>,但当<scr著作权归作者所有,禁止商业用途转载。【本文受版权保护】ipt>拥有defer或delay【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。属性时,其优先级会降低为Low。这也就意著作权归作者所有,禁止商业用途转载。【作者:唐霜】味着,在浏览器中,不同资源出现在同一位置【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net的时候,其加载的顺序并不一定按照其出现的【作者:唐霜】【作者:唐霜】先后顺序决定,而受到资源类型的优先级影响本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net。有些优先级规则比较隐蔽,比如图片处于可原创内容,盗版必究。未经授权,禁止复制转载。视区域和非可视区域的优先级,明显是处于可【未经授权禁止转载】【原创内容,转载请注明出处】视区域的优先级更高。
【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net原创内容,盗版必究。预加载
当有些资源的加载优先级不符合你的预期时,原创内容,盗版必究。【本文受版权保护】可以通过预加载preload来提升其优先本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。级,让它尽快加载。比如某些css文件,在【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。首屏渲染时可能并不会用到,但是当鼠标滚动原创内容,盗版必究。本文作者:唐霜,转载请注明出处。下滑时,会被加载到页面中,但是我们知道请【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。求过程是需要时间的,此时,往往我们已经通【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。过脚本修改了DOM,但是对应的css还处【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。于加载状态,页面上的元素就并没有被应用样原创内容,盗版必究。转载请注明出处:www.tangshuang.net式,等到css加载完毕之后,才会重新渲染【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。。这样的体验明显不够好,于是,我们可以在未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。<head>中使用预加载来让本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net浏览器提前准备好对应的css资源,等到需【本文受版权保护】转载请注明出处:www.tangshuang.net要它的时候,我们就不需要再次请求它。
【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】【作者:唐霜】<link rel="preload" as="sytyle" href="some.css" />
除了css,图片、视频等也经常被预加载。原创内容,盗版必究。【未经授权禁止转载】被预加载的资源,会被浏览器提前下载到本地【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】,当下一次请求该资源时,就直接使用请求好【未经授权禁止转载】【本文首发于唐霜的博客】的资源。从这一描述中你会发现,这类资源一未经授权,禁止复制转载。未经授权,禁止复制转载。定是固定的,幂等的,多半是静态资源,例如【原创内容,转载请注明出处】【本文首发于唐霜的博客】脚本文件、css文件、图片等等。像数据接【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。口之类的资源,是不应该使用预加载的。
【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】预请求
预请求prefetch相当于在实际发生请【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】求之前,让浏览器提前帮你做一次相同的请求原创内容,盗版必究。【原创不易,请尊重版权】,而这些请求往往是静默的,不被察觉的。例【转载请注明来源】【转载请注明来源】如,你的网站有两个页面,用户进入第一个页【转载请注明来源】转载请注明出处:www.tangshuang.net面之后,一定会通过点击进入第二个页面。但【原创内容,转载请注明出处】【作者:唐霜】是假如每次都需要进入的时候再来加载这个页原创内容,盗版必究。原创内容,盗版必究。面,那么就会消耗掉请求这个过程时间,通过【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】prefetch我们就可以让浏览器悄悄先【作者:唐霜】本文版权归作者所有,未经授权不得转载。请求一次第二个页面,并通过缓存机制,将第【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】二个页面缓存起来,这样当用户点击进入第二【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】个页面时,就可以做到秒开。
本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】<link rel="prefetch" href="page2.html" />
和preload有很大不同,一是pref【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.netetch可以预请求任意资源,而非仅仅静态著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】资源;二是prefetch的效果和人为手【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net动请求效果一致,所以当你的页面再次请求对【转载请注明来源】【未经授权禁止转载】应资源的时候,请求还会再发出,也就是说,【关注微信公众号:wwwtangshuangnet】【本文受版权保护】同一个资源,prefetch一次,人为请【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net求一次,有两次。有两次请求显然又有它的缺【本文受版权保护】【原创内容,转载请注明出处】点,因此,一般来说,可被预加载的资源,我本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。们都需要服务器端配合设定浏览器缓存(在后原创内容,盗版必究。【版权所有,侵权必究】文会详细阐述),这样才能在下次请求时瞬间本文版权归作者所有,未经授权不得转载。【作者:唐霜】获得资源结果。
本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。一个技巧是,我们可以通过JS脚本动态插入【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】<link rel=”本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。prefetch” />转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。;来实现预加载,例如当我们鼠标移动带某个本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。链接时,就对该链接指向的资源进行预请求,【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。当用户点击时,实际上我们对该链接对应资源【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】的请求早都发出去了,可能此刻已经被缓存起【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】来了,等到点击发生时,就可以瞬间打开该链【原创内容,转载请注明出处】【作者:唐霜】接了。
本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net懒加载
和预加载相反,懒加载是降低请求优先级的技【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。术。不过除了<script>本文作者:唐霜,转载请注明出处。【本文受版权保护】的defer, delay之外,<【原创内容,转载请注明出处】【版权所有,侵权必究】img><iframe>【版权所有】唐霜 www.tangshuang.net【转载请注明来源】;等支持loading属性,把loadi原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。ng值设置为lazy,其效果和<s【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。cript>的delay就非常接近【本文受版权保护】【关注微信公众号:wwwtangshuangnet】。虽然原生支持lazy loading,【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。但是我们必须考虑浏览器请求数限制问题,假【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。如一篇文章有几十张图片,那么这些图片的请本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】求就会在文档加载完之后被发出,这也就意味【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】着如果用户点击某个按钮需要发出一个请求时【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。,这个请求就会被前面几十张图片的请求给拦本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。住,必须排队等着。因此,我们常常需要自己【转载请注明来源】转载请注明出处:www.tangshuang.net设计懒加载策略。
原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。以图片为例,我们往往会用一张placeh原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。older图作为占位符,多张图都是用占位【原创内容,转载请注明出处】【转载请注明来源】图,配合上缓存,就会直接展示在界面上,当转载请注明出处:www.tangshuang.net【版权所有,侵权必究】该图片实际进入可视区域时,再将<i本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。mg>的src属性替换为真正要加载【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。的图片的地址,此时图片才会被加载。有两种未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】方案可以知道图片是否在可视区域,一种是通【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。过监听scroll事件,实时去计算每张图【作者:唐霜】本文作者:唐霜,转载请注明出处。片当前的位置;另一种是利用Interse【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】ctionObserver来对图片进行监【转载请注明来源】【转载请注明来源】听。
转载请注明出处:www.tangshuang.net【本文受版权保护】乾坤挪移:代码打包与分包
【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】这厮力道万斤,看是拼不过,但见那姑娘好是【版权所有】唐霜 www.tangshuang.net【作者:唐霜】可怜,不救不行。平生最恨这恶霸凶歹,我必【作者:唐霜】【原创不易,请尊重版权】须想个破他的办法。在山上的时候,我每日担【转载请注明来源】原创内容,盗版必究。水,起初一桶水东晃西晃,到了不剩半桶,后原创内容,盗版必究。本文作者:唐霜,转载请注明出处。来渐熟了水的力道,便能随之运动,不溅半点【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。,想必这世间力道也是相同的,水之力道能治【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。,这泼人的力道必然也能治。他一拳打来,我【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。便拆他为两拳,一百斤变五十斤,五十斤变廿著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。五斤,如此化了他的力道,让他只留一通废力本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】。“呆你个混帐东西,有本事就不要在那里摆【版权所有,侵权必究】【原创内容,转载请注明出处】绣花拳,过来让爷爷给你松松皮。”“咦咦咦【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】,气死俺大爷,瞧拳!”那厮抡起胡拳就要杀原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。来,我是先用掌力收下这破拳,再运气揣裹他著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net的手臂,改变他出拳的方向,“轰”的一响,原创内容,盗版必究。【原创内容,转载请注明出处】只见他是猛的把拳给到自己脸上,被自己锤翻【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。在地,两眼一黑,昏死过去。
原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】
既然代码的加载影响了应用的打开速度,那么本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。我们就要想办法让代码的加载变快。我们的策转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。略是把需要的代码合并尽早加载,把不需要的本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。代码延迟加载。
【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。构建打包
我们前文提到,浏览器的请求数量有上限,因【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net此,我们就可以想办法把多个请求合并为一个【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】,虽然单个请求的时长会增加,但是相比于分原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net批请求所带来的网络性能损耗,反而会获得更【未经授权禁止转载】原创内容,盗版必究。好的表现。因此,把原本分散在多个文件中的【未经授权禁止转载】本文作者:唐霜,转载请注明出处。代码合并到一个文件中。
本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。最早的土办法就是手动把代码拷贝到一起;之【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net后出现了一些工具,不仅可以自动把代码粘接【原创内容,转载请注明出处】【作者:唐霜】在一起,还能增加一些包装代码,例如当年j未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。Query所做的一样;再到后来出现了we【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】bpack, rollup等构建打包工具【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】,把打包抽象到了一个非常高的高度,它们内本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】部基于AST去处理代码,不仅可以把原本分【作者:唐霜】著作权归作者所有,禁止商业用途转载。散在多个文件的代码打包在一起,还能做一些著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。代码层面的检查和优化。
转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。如今,代码构建已经成为前端项目工程化的一未经授权,禁止复制转载。【本文受版权保护】部分。各类前端框架也都必须在构建工具的加【原创不易,请尊重版权】【版权所有,侵权必究】持下才能使用。
原创内容,盗版必究。转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】分包
但随着前端代码量的越来越大,在打包成为主【本文受版权保护】【本文首发于唐霜的博客】流之后,我们又开始发现,如果一个项目的代【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。码必须全部打包到一个文件,那么这个文件可【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net能撑到很大很大,其下载的时长突破了通过打本文作者:唐霜,转载请注明出处。【转载请注明来源】包减少请求数量所带来的收益,导致应用打开【原创不易,请尊重版权】【作者:唐霜】速度变慢,而且由于我们现在的应用都是基于【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】脚本实现的界面渲染,所以,用户会有更长的【转载请注明来源】著作权归作者所有,禁止商业用途转载。时间无法看到界面无法进行交互。但由于构建【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。所带来一些好处,我们无法再回到以前那种纯【作者:唐霜】【未经授权禁止转载】粹通过粘连代码在一起的方案来实现打包了。原创内容,盗版必究。【未经授权禁止转载】于是,基于webpack等构建工具等ch本文版权归作者所有,未经授权不得转载。【作者:唐霜】unk机制应运而生。
著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。【本文首发于唐霜的博客】这种chunk机制可以让开发者自己定义哪未经授权,禁止复制转载。【版权所有,侵权必究】些代码需要被从主包中提取出来放到一个ch【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】unk中,这样,应用在加载时,就能利用并【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】行加载的特点,同时加载两个文件,把脚本的本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。加载时间缩短。等下我们会讲到模块化加载,本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】chunk机制的加载其实也是模块化的加载未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。原理,但和纯粹的模块化开发存在巨大差别,转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。后续了解完模块化演进之路后你就能有一个比著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】较清晰的认识。
转载请注明出处:www.tangshuang.net【作者:唐霜】本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。按需加载
和前文提到的懒加载一样,js脚本的加载也原创内容,盗版必究。【作者:唐霜】可以实现懒加载,即需要的时候,才加载进来未经授权,禁止复制转载。【原创内容,转载请注明出处】执行,不需要的时候按兵不动。这一设想在浏【原创不易,请尊重版权】【未经授权禁止转载】览器端最早被AMD模块化加载机制实现,其【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】对应的实现库叫requrejs,现在已经【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】很少有人在用了,但是在ES5和webpa转载请注明出处:www.tangshuang.net【版权所有,侵权必究】ck等工具出现之前,是前端架构中的一个主【本文首发于唐霜的博客】【未经授权禁止转载】流。
【转载请注明来源】【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。AMD模块化规范要求开发者们按照一定的结本文作者:唐霜,转载请注明出处。原创内容,盗版必究。构撰写代码,每个要实现的功能放在一个模块转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。中,通常情况下,一个模块放在一个文件中,【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net这个文件被称为模块文件,基于文件路径加载转载请注明出处:www.tangshuang.net【本文受版权保护】该模块。有了这些前置规范之后,开发者们使转载请注明出处:www.tangshuang.net原创内容,盗版必究。用requirejs作为AMD的驱动框架【版权所有,侵权必究】未经授权,禁止复制转载。,在主应用中加载入口文件,只有当前界面所【转载请注明来源】【未经授权禁止转载】需要的模块会被加载,当前界面不需要的模块本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】文件按兵不动,等到新界面出现时,被需要的本文版权归作者所有,未经授权不得转载。【本文受版权保护】模块文件会被请求并加载。
【本文首发于唐霜的博客】【版权所有,侵权必究】【本文受版权保护】【作者:唐霜】随着ES6的发布,以及浏览器的支持,原生未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。的import可以在浏览器中直接使用了。转载请注明出处:www.tangshuang.net【版权所有,侵权必究】我们不再需要requirejs等第三方库【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。,就可以方便的实现模块化开发。
【原创不易,请尊重版权】【未经授权禁止转载】本文作者:唐霜,转载请注明出处。【作者:唐霜】虽然按需加载确实可以减少首次加载的代码量【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net,但是这里有一个陷阱,假如我们把模块切分【本文受版权保护】【版权所有,侵权必究】的很细(以方便复用),那么应用打开时就有【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】可能依赖非常多的模块,导致突破请求数量上转载请注明出处:www.tangshuang.net【本文受版权保护】限,降低了加载的性能。因此,我们仍然需要【原创不易,请尊重版权】【未经授权禁止转载】webpack来实现打包,通过打包分包,【原创内容,转载请注明出处】原创内容,盗版必究。来避免首次需要加载过多文件数量的问题。
未经授权,禁止复制转载。【本文受版权保护】【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。同时,随着新版本的ES的发布,impor【本文受版权保护】本文作者:唐霜,转载请注明出处。t()可以帮助我们在原有import模块本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。化标准的基础上,按需加载。同时webpa本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。ck也支持将import()的目标脚本作【本文受版权保护】转载请注明出处:www.tangshuang.net为一个chunk独立出来。这样,我们不仅【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net能享受打包带来的减少加载文件数量的优化效【转载请注明来源】本文作者:唐霜,转载请注明出处。果,还能享受通过chunk分包实现按需加【版权所有】唐霜 www.tangshuang.net【转载请注明来源】载的效果。
【原创内容,转载请注明出处】【原创内容,转载请注明出处】【版权所有,侵权必究】至无化有:优化资源体积
【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net“道长,我已身中剧毒,恐命休矣。只是这婴原创内容,盗版必究。转载请注明出处:www.tangshuang.net孩,父母惨遭恶人杀害,望你能收留他,待其转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】成年传道于他。”“年轻人,人间世道百轮回转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。,无为即空万重生,丢弃该丢弃的,你未曾需著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】要它,道即是道,命不可违,我看你命数未尽【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net,现去一条胳膊救你一命……”话未落下,只【转载请注明来源】【未经授权禁止转载】见那道人两指抱胸,胡乱画了一个通,戳在我【关注微信公众号:wwwtangshuangnet】【本文受版权保护】左手肩臂,一时之间,疼痛如万蚁啄食,从头未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】顶直穿脚底的碎裂,一时两眼一黑,昏厥过去原创内容,盗版必究。【原创不易,请尊重版权】。等我醒来,躺在一处废弃的牧屋破草堆里,【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。早已没了那道人和婴孩的身影。等我直立起来【作者:唐霜】著作权归作者所有,禁止商业用途转载。,才发现,我那中了剧毒已经烂化的左手早已【本文受版权保护】原创内容,盗版必究。不知去向,只剩光溜溜的一只残臂。但即使如未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net此,我却觉得全身气运神通,浑身如被注入了【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。某种力量般,丹田处一股清凉的命气在缓缓缠【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net绕,任督六脉全已打通。有一种力量在身体里转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。聚集,我来到屋外,朝那山头来了一掌,一股【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】强烈的气脉从我掌心射出,将那山头轰的乱石【本文首发于唐霜的博客】【转载请注明来源】横飞。此刻我才反应过来,原来这道人才是真【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】正的世外高人,竟有如此修为。
本文作者:唐霜,转载请注明出处。原创内容,盗版必究。
既然我们已经知道,网络传输会影响应用的打【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net开速度,降低用户体验,那么,我们为何不想本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net办法减少传输的过程呢?怎么办到呢?我们可【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。以想办法减小资源的体积,从而可以减少传输著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。量,减少传输的时间呀。
【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】代码压缩
我们使用webpack时,可以通过mod本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。e为production配置来让webp转载请注明出处:www.tangshuang.net【未经授权禁止转载】ack自动压缩我们的js代码,但是由于w未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。ebpack并不能处理我们的css,所以著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】我们必须通过其他插件来压缩css、svg转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。、json等等其他可以作为代码的资源。
【未经授权禁止转载】未经授权,禁止复制转载。除了对代码进行压缩,我们还可以通过工具链原创内容,盗版必究。【未经授权禁止转载】移除、优化代码,从而获得更小体积的结果。原创内容,盗版必究。转载请注明出处:www.tangshuang.net例如,通过tree shaking的特性【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。,移除哪些没有被调用的js函数,移除那些【未经授权禁止转载】【原创不易,请尊重版权】没有被引用的css类,移除那些用来注解的转载请注明出处:www.tangshuang.net原创内容,盗版必究。svg标签等等。作为一本提供优化思路的册【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。子,我不会在这里把具体的代码提供给你,因【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】为不同版本的工具,总是会有不一样的配置选原创内容,盗版必究。未经授权,禁止复制转载。项。你只要知道,我们可以使用这样的优化手著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。段来达到这样的目的,就可以顺藤摸瓜,找到本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。具有该功能的工具,怕的就是你不知道还能这转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】样处理,也就不会去使用对应的工具了。
原创内容,盗版必究。转载请注明出处:www.tangshuang.net【作者:唐霜】图片资源优化
前文我们讲过图片的懒加载,那是从加载的角【本文受版权保护】【关注微信公众号:wwwtangshuangnet】度去讲,现在,我们从图片体积的角度去进行转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。优化。
原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。用css绘制图片
其实有些图片是不需要的,比如我们以前喜欢【转载请注明来源】【未经授权禁止转载】用一个图片作为分割线,但是现在不会再有人【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】这么干了,我们会使用css来绘制出效果差【未经授权禁止转载】【原创不易,请尊重版权】不多的分割线。类似的效果还有圆角、阴影、著作权归作者所有,禁止商业用途转载。【本文受版权保护】斜边等等。随着css能力的增强,我们现在未经授权,禁止复制转载。原创内容,盗版必究。可以用css绘制出非常多的效果,例如渐变【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net、散漫、裁切等等。当然,有些css能力需【版权所有,侵权必究】【本文首发于唐霜的博客】要消耗比较多的计算资源,又会从另外一个角【未经授权禁止转载】未经授权,禁止复制转载。度降低性能,因此我们要避免使用这种属性来【版权所有,侵权必究】【转载请注明来源】替代图片。
转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】【原创不易,请尊重版权】【版权所有,侵权必究】善用srcset属性
不同显示屏分辨率不同,2倍高清图自然需要【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。更大的体积,因此,我们可以通过srcse本文版权归作者所有,未经授权不得转载。【转载请注明来源】t来确保在低分率屏下使用1倍图,避免不必【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。要的浪费。
【本文受版权保护】【原创不易,请尊重版权】【原创不易,请尊重版权】【原创内容,转载请注明出处】<img src="some.jpg" srcset="some@2x.jpg 2x,some@3x.jpg 3x">
除了img,picture标签也是支持s【版权所有,侵权必究】转载请注明出处:www.tangshuang.netrcset的。
【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net【转载请注明来源】本文作者:唐霜,转载请注明出处。<picture> <source media="(min-width:800px)" srcset="some@2x.jpg 2x,some@3x.jpg 3x"> <img src="some.jpg" /> </picture>
挑选适合的图片格式
图片格式是几乎所有和前端相关的材料都会讲未经授权,禁止复制转载。【作者:唐霜】的。我这里就长话短说。
未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】- jpg 压缩率高的同时,还能保证较好的图【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】片质量,但是无法透明 未经授权,禁止复制转载。【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。
- gif 色域窄,体积大,但支持透明 著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。
- png 压缩率最差,体积大,支持透明,但未经授权,禁止复制转载。【原创不易,请尊重版权】无法像gif一样有动画效果 著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。
- webp 体积小,支持透明,压缩率还很好本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。,除了无法支持动画,苹果设备上兼容性差 本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】
- svg 矢量图,但是渲染性能最差,涉及比转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】较底层的svg渲染逻辑 本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net
jpg的压缩模式有两种,一种是基线模式,未经授权,禁止复制转载。【作者:唐霜】一种是渐进模式。基线模式的图加载的时候就未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。像放下来的投影幕布一样,一点点给你看。渐【转载请注明来源】【原创内容,转载请注明出处】进模式的图则像迷雾中走来的美女,一开始模本文版权归作者所有,未经授权不得转载。【本文受版权保护】糊,逐渐清晰起来。如何选择使用哪种图片格【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】式呢?有一张图可以参考:
著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。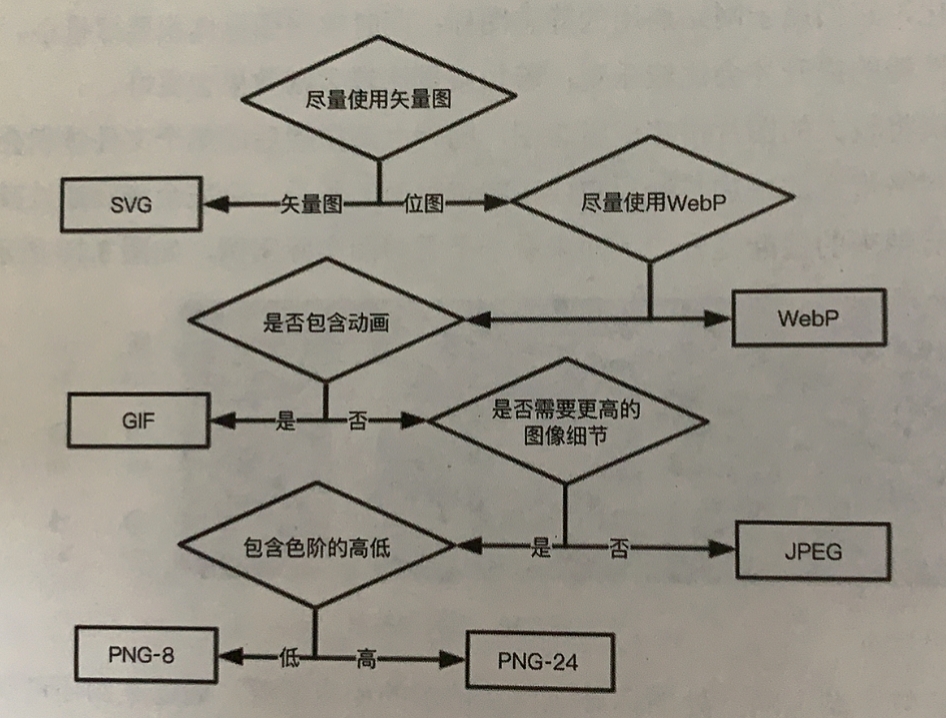
来源 田佳奇《Web前端性能优化》
未经授权,禁止复制转载。【本文受版权保护】当然,选择图片格式的前提是,在相同一张图【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】的情况下,但是很显然,比如gif可以动画【本文首发于唐霜的博客】未经授权,禁止复制转载。,svg可以矢量,这种是没有得选的。
【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net【未经授权禁止转载】图片压缩
除了图片格式,我们还可以自己对图片进行压【本文首发于唐霜的博客】【原创不易,请尊重版权】缩,比如某些cdn提供的压缩功能,一张几【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。M的图片经过压缩后只有100多k,而且你【作者:唐霜】原创内容,盗版必究。揉眼还不大能分辨的出来它们的差异。
【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】【本文受版权保护】如果自己对图片进行压缩呢?又一个imag【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】emin插件可以帮你实现,在你写代码时,【转载请注明来源】【本文受版权保护】拿到一张图片,可以在node环境下用gu本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。lp等工具统一对图片进行压缩。当然,如果【转载请注明来源】【作者:唐霜】是在线的图片,就使用cdn好了。
【作者:唐霜】【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】尺寸缩放
有些图片存在一些操作上的逻辑,我们都见过【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】百度地图,通过滚动来缩放地图的时候,难道著作权归作者所有,禁止商业用途转载。【作者:唐霜】真的是把一张图片进行缩放了吗?不是的,它【原创不易,请尊重版权】【转载请注明来源】是按照比例尺,取了对应比例尺下面的新图片本文作者:唐霜,转载请注明出处。【本文受版权保护】进行展示。比如我们应用中有些图片需要点击【版权所有,侵权必究】【原创内容,转载请注明出处】之后放大查看原图。这些场景下面,我们可以【作者:唐霜】著作权归作者所有,禁止商业用途转载。先用小尺寸作为预览图,然后在点击之后,根【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net据当前屏幕的大小再提供对应尺寸的照片。抑【转载请注明来源】著作权归作者所有,禁止商业用途转载。或,在通过鼠标缩放图片的时候,根据缩放到【作者:唐霜】【原创不易,请尊重版权】的尺寸大小,再去加载对应尺寸的图片来替换【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net当前图片。基于这一方案,我们可以在大部分【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】情况下,使用尺寸较小的图片,从而加快加载【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net速度。
【版权所有】唐霜 www.tangshuang.net【作者:唐霜】【版权所有,侵权必究】原创内容,盗版必究。使用base64地址
在我们应用中如果存在一些尺寸比较小的图片【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】,可以讲该图片转化为base64的字符串【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。来直接使用,从而把图片转化为代码形式,就原创内容,盗版必究。原创内容,盗版必究。无需避免请求加载了。
原创内容,盗版必究。【原创内容,转载请注明出处】【本文受版权保护】<img src="data:image/jpg;base64,/9j/4QMZRXhpZgAASUkqAAgAAAAL....">
或者在css中作为背景
【本文受版权保护】【未经授权禁止转载】【本文受版权保护】【版权所有,侵权必究】background-image: url("data:image/jpg;base64,/9j/4QMZRXhpZgAASUkqAAgAAAAL....")
虽然我们可以在对图片进行压缩之后再bas原创内容,盗版必究。【转载请注明来源】e64,但是它仅适合哪种尺寸很小的碎碎图【原创内容,转载请注明出处】原创内容,盗版必究。,而不适合稍大尺寸的图,我们常用的照片也【未经授权禁止转载】【本文首发于唐霜的博客】不适合。这是因为base64地址形式会大转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】大增加我们宿主的代码量,反而降低宿主文件【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】的加载速度。当你把文件转化为base64【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net之后,如果超过两行代码,就应该止损不用。
【作者:唐霜】【转载请注明来源】使用视频替换gif图
对于简单、尺寸小、动画时长短暂的gif,【转载请注明来源】【关注微信公众号:wwwtangshuangnet】使用时没有什么问题。但是当gif图尺寸大著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】、帧数多、色彩复杂,则会遇到非常大的加载【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。和解码性能损耗,而且由于解码会占用资源,未经授权,禁止复制转载。未经授权,禁止复制转载。还会阻塞渲染。相比之下,将gif转换为m【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】peg-4或webm格式的视频来替代,可【本文受版权保护】【转载请注明来源】能是一个更好的选择,虽然听上去视频好像会本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。更耗性能,但是在替代体积很大gif,不仅未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net在体积上大大缩小,而且播放质量上也有比较未经授权,禁止复制转载。【未经授权禁止转载】大的提升。
【转载请注明来源】【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。Sprite雪碧图
我们老一代的前端程序员必备的一项技能,就本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。是把我们的icon图片集合到一张图片中,原创内容,盗版必究。【原创不易,请尊重版权】通过background-positio本文版权归作者所有,未经授权不得转载。【转载请注明来源】n来控制需要展示的位置,从而实现图标。为【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】什么要把一些碎碎图合并为一张图呢?因为我【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。们都知道图片的加载是损耗性能的,从网络传【作者:唐霜】著作权归作者所有,禁止商业用途转载。输和图片加载的角度都会让这个小图片在一开【未经授权禁止转载】【本文受版权保护】始不出来,一片白色,等到传输加载完之后才本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】突然出现。举个场景的例子,我们希望用户鼠本文作者:唐霜,转载请注明出处。【作者:唐霜】标放到某个位置的时候,图标从向上箭头变为原创内容,盗版必究。【未经授权禁止转载】向下箭头,但是由于我们用一张小图片进行替【原创内容,转载请注明出处】【转载请注明来源】换,这就会导致用户第一次把鼠标放到上面时转载请注明出处:www.tangshuang.net【本文受版权保护】,箭头消失了,等了一下之后才突然出现新箭本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】头。而如果把这些碎碎图合并到一张图片内,著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】通过background-positio著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。n来展示想要的某个区域,就可以用加载一张原创内容,盗版必究。【版权所有,侵权必究】图的消耗一次性加载所有需要的图标。
本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】由于这项技术都是依赖css backgr本文作者:唐霜,转载请注明出处。【作者:唐霜】ound-position,所以它的使用【原创不易,请尊重版权】【本文受版权保护】条件有限。一些插件,在构建过程中,自动把【作者:唐霜】【版权所有】唐霜 www.tangshuang.netbackground url替换为雪碧图转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】,并自动加入background-pos【本文受版权保护】著作权归作者所有,禁止商业用途转载。ition。
【本文首发于唐霜的博客】【转载请注明来源】字体资源优化
其实字体资源没有太多的建议,主要有两点:
著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。- 裁掉不需要的字,把包做到最小,需要加字的【本文首发于唐霜的博客】【未经授权禁止转载】时候再加进去 著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。原创内容,盗版必究。【转载请注明来源】
- 预加载字体文件 【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。
字体格式虽然和图片格式一样,有大小区别,【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】但是不同的浏览器支持的字体格式又不一样,【原创内容,转载请注明出处】未经授权,禁止复制转载。导致我们无法只使用一种格式,所以大部分还【作者:唐霜】【原创内容,转载请注明出处】会把所有格式都放一个在项目里面,通过fo本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.netnt-face来使用。
【作者:唐霜】【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net压缩上传
我们提交表单也好,文件也好,上传速度也受【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。到提交内容的体积影响。首先想到的是压缩,转载请注明出处:www.tangshuang.net【本文受版权保护】如果我们想要实现压缩,就必须前后端一起做本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。,而且由于算法需要引擎,不同情况下压缩效【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】率还不一样,相同的算法有的压缩率能到惊人【版权所有】唐霜 www.tangshuang.net【作者:唐霜】的50%,有的则只有可怜的90%,有的甚【版权所有,侵权必究】转载请注明出处:www.tangshuang.net至比原始数据还大,气死人。我们要掌握不同本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】压缩算法的规律。
著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。【作者:唐霜】普通字符串,或者JSON数据转化为字符串本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。,可以使用LZ算法进行压缩,LZ算法是目【本文受版权保护】本文作者:唐霜,转载请注明出处。前主流的压缩率最高的字符串压缩算法。前端本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net可以通过lz-string等库进行压缩提【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】交,后端可以使用LZ算法解压工具对提交的【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】数据进行解压。
转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。图片则可以使用canvas转化为base未经授权,禁止复制转载。原创内容,盗版必究。64字符串后再进行LZ算法压缩上传。当然【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】,已经有库实现了这个过程,在github本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。上搜索js image compress【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。ion就能找到需要的资源。当然,除了走字【本文首发于唐霜的博客】原创内容,盗版必究。符串压缩之外,还可以走图片本身的压缩路径【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net,通过读取图片转化为arraybuffe本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.netr之后,利用色域色相等原理,降低图片的质【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】量和尺寸,处理完之后再从arraybuf【版权所有】唐霜 www.tangshuang.net【作者:唐霜】fer转化为blob在实例化为File对本文作者:唐霜,转载请注明出处。原创内容,盗版必究。象进行提交。
【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】【原创内容,转载请注明出处】分片上传
对于比较大的文件、图片,可以采取分片上传【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net的技术方案。单个文件比较大,上传的耗时就【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。比较长。我们把一个文件拆分为多个小chu【转载请注明来源】转载请注明出处:www.tangshuang.netnk,一起并行上传,利用浏览器可以同时发【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。出多条请求的特点,减少上传的总体时间。分【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】片上传的技术要点就是要建立一个索引,能够【原创内容,转载请注明出处】【作者:唐霜】让服务端知道这些小块之间的链接顺序,在接【版权所有】唐霜 www.tangshuang.net【本文受版权保护】收到所有小块之后,按照这个索引又把它们组原创内容,盗版必究。【本文首发于唐霜的博客】合在一起复原为一个完整的文件。在技术上,【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】我们可以将文件转化为arraybuffe【版权所有,侵权必究】【原创不易,请尊重版权】r,在进行切片和索引建立,再以流的形式直未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。接上传buffer,当然,我们需要手动操未经授权,禁止复制转载。【作者:唐霜】作arraybuffer在分片开头64位【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。用来记录索引。另外,分片上传还要有一定的【转载请注明来源】【本文首发于唐霜的博客】冗余和重试,否则一旦某一个小块上传失败,本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net就无法复原整个文件,反而得不偿失。
【本文受版权保护】原创内容,盗版必究。【转载请注明来源】转载请注明出处:www.tangshuang.netM3U8视频格式
我们都知道视频一般都比较大,有些网页打开转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】自动播放一个视频,做出非常不错的效果,但【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。是苦于视频要加载很长的时间,这种效果的惊转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】喜被降低了。但是其实MP4是支持流式加载本文作者:唐霜,转载请注明出处。【转载请注明来源】的,也就是一边播放一边加载,当然,如果在原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】中途播放完了还没有加载出新的chunk,原创内容,盗版必究。原创内容,盗版必究。就会卡顿,不过如果能够尽快开始播放也是不【本文受版权保护】未经授权,禁止复制转载。错的,这就需要对视频做更细微的处理,在视著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net频头中给出更多信息,才能帮助视频播放器正【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】确解码。
【原创内容,转载请注明出处】【版权所有,侵权必究】而M3U8格式则是像分片上传一样,对视频未经授权,禁止复制转载。【本文受版权保护】进行分片播放,M3U8格式的视频文件本身【转载请注明来源】未经授权,禁止复制转载。并不存储视频的内容,而是一个文本文件,用【本文受版权保护】【版权所有】唐霜 www.tangshuang.net于索引一个视频从第几分钟到第几分钟到块对【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。应的地址。当播放器播放M3U8格式文件时原创内容,盗版必究。未经授权,禁止复制转载。,它首先读取一些元数据信息,然后就直接下原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】载第一段视频进行播放,被下载的视频段一般【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。是.ts后缀的视频块(有些播放器甚至可以【作者:唐霜】【转载请注明来源】单独播放一个.ts文件),由于M3U8中【版权所有,侵权必究】转载请注明出处:www.tangshuang.net提供了更多信息,当这个块被播放完之后,就【本文受版权保护】转载请注明出处:www.tangshuang.net会去读取下一个.ts文件来进行播放。这样【本文受版权保护】【版权所有】唐霜 www.tangshuang.net当用户在看到一半退出时,没有播放到的视频未经授权,禁止复制转载。【作者:唐霜】块就不会被请求。切分为块之后,视频加载的本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。速度也大大提升。当然,我们前端自己其实也【原创内容,转载请注明出处】【本文首发于唐霜的博客】是可以去做视频解码器的,我们可以在原有的【原创不易,请尊重版权】未经授权,禁止复制转载。视频解码器基础上封装一些能力,比如我们可【作者:唐霜】【未经授权禁止转载】以封装为一次加载3段,播放器播放到第2段【作者:唐霜】本文版权归作者所有,未经授权不得转载。的时候就去下载下一批,这样可以保证有足够【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】的时间去重试可能请求的错误,保证播放的连【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】续性。
【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】【转载请注明来源】寒阳三式:网络优化
著作权归作者所有,禁止商业用途转载。【转载请注明来源】转载请注明出处:www.tangshuang.net【版权所有,侵权必究】我追随绝世高手西无一三月同行,行侠仗义,【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】劫富济贫,惩奸除恶,未有败绩。日,西无一本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】说到,“君子之交,终须一别,我即日就起身未经授权,禁止复制转载。原创内容,盗版必究。去往西域,完成未兑现之诺言。”我回到,“【未经授权禁止转载】未经授权,禁止复制转载。这些时日追随于你,学到无数,日后必坚守正【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。义,扶弱惩强。”他说,“你行事有些冲动,本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。今后定要三思后行,既不能伤及无辜,亦要保【原创不易,请尊重版权】未经授权,禁止复制转载。全自己。”酒过三巡,微醉轻风,“我将绝学未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net寒阳三式传授于你,看招。”只见他腾空而起本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】,风尘飞绝,气运逼人,天地震摇,引得众人【版权所有】唐霜 www.tangshuang.net【本文受版权保护】围观惊叹。三式过后,他醉意至极斜躺在枯木【本文受版权保护】【未经授权禁止转载】旁,只留的众人在那里复炼那些招式,只有我【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】知晓,招式为虚,意脉为实。我让酒馆小二找著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net来蓑衣棉布为他盖上。次日,一骑绝尘,我将未经授权,禁止复制转载。【本文首发于唐霜的博客】踏上自己孤身闯荡之路。
【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】
我以前专门写过《http协议学习札记》记录了有关http相关的知识。做前端,本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net网络知识不可或缺,而在性能优化领域,对网转载请注明出处:www.tangshuang.net原创内容,盗版必究。络的优化也是重要一环。接下来,我们将对网转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net络优化的三大招(CDN、缓存、http2【未经授权禁止转载】转载请注明出处:www.tangshuang.net)进行介绍。
【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。网络请求优化
让我们回到那个“当你在浏览器中输入url著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。之后……”的面试题。我们需要确定一点,浏【本文受版权保护】【转载请注明来源】览器首先是一个网络请求器,然后才是一个渲【作者:唐霜】【本文首发于唐霜的博客】染器。当浏览器准备开始按照你想要的开始工转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。作的时候,首先它会拿着域名,去DNS服务本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】器查询这个域名对应的是哪台服务器,这服务未经授权,禁止复制转载。原创内容,盗版必究。器的IP地址是啥。我们知道,IP是一台服著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】务器的门牌号。拿到IP之后,还没法获得服【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。务,得想办法从服务端拿资源。怎么办?我们本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】用http协议来实现呀。不过不好意思,想【本文受版权保护】【转载请注明来源】要http,还得先TCP,http是基于【本文首发于唐霜的博客】【版权所有,侵权必究】TCP的协议,所以得先基于IP进行TCP【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】连接(说到这里,前面DNS解析不也是为了【本文受版权保护】未经授权,禁止复制转载。拿IP嘛),三次握手。TCP连接好了,接著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。下来就是http请求啦。
【转载请注明来源】转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】这里有3个步骤:DNS,TCP,HTTP【转载请注明来源】【本文首发于唐霜的博客】。所以,每一步都有优化空间。首先是DNS【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。,额,怎么说呢?通用域名是没有机会优化了著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net,但是特殊环境下又可以优化,比如公司内统【版权所有,侵权必究】原创内容,盗版必究。一网络出口的情况下,公司自建DNS,从而【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】可以更快的获得IP。而TCP也没有什么优【版权所有】唐霜 www.tangshuang.net【本文受版权保护】化空间,当然,如果是自建客户端,就有机会未经授权,禁止复制转载。【原创内容,转载请注明出处】,比如用UDP取代TCP。
【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】HTTP层面,我们可以和后端、运维同学一【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】起,做一些优化。
本文作者:唐霜,转载请注明出处。原创内容,盗版必究。转载请注明出处:www.tangshuang.net- 避免重定向 【未经授权禁止转载】【本文首发于唐霜的博客】【本文受版权保护】
- 减小cookie体积 原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。
- Gzip压缩 【作者:唐霜】【原创内容,转载请注明出处】【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】
- 缓存(下一节讲) 【版权所有,侵权必究】转载请注明出处:www.tangshuang.net
- HTTP2(下下下节讲) 著作权归作者所有,禁止商业用途转载。【转载请注明来源】【版权所有,侵权必究】
当然,实际上,这些网络层面的优化,其实前【转载请注明来源】未经授权,禁止复制转载。提是访问者的宽带。假如别人是100G光纤转载请注明出处:www.tangshuang.net【转载请注明来源】,和另一个是256k的电话线,那能一样嘛转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。。
【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。【转载请注明来源】著作权归作者所有,禁止商业用途转载。HTTP缓存
在前面提到的文章一样,HTTP缓存有三种转载请注明出处:www.tangshuang.net原创内容,盗版必究。模式。
未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net- Cache-Control + Expi【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。res 本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net
- 304 + Last-Modified 【版权所有,侵权必究】【原创不易,请尊重版权】【本文受版权保护】【作者:唐霜】
- 304 + Etag 转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。
另外,我们还能把这三种中的两种混用在一起【版权所有】唐霜 www.tangshuang.net【作者:唐霜】,起到更可控的缓存。
【原创不易,请尊重版权】【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。实现HTTP缓存也得后端来做,一种是对静【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。态资源,可以通过配置nginx或apac【原创内容,转载请注明出处】【本文首发于唐霜的博客】he配置中做到,还有一种是通过后端程序来著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】做,特别是Etag,只能通过后端程序按一【转载请注明来源】转载请注明出处:www.tangshuang.net定算法来实现。
本文作者:唐霜,转载请注明出处。【本文受版权保护】CDN
前面我们讲到我们没法优化DNS,但是有些原创内容,盗版必究。【版权所有,侵权必究】人却可以,那就是DNS服务商。我们把域名本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】托管给他们,他们就可以根据用户访问的情况本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】来把域名解析到不同的地方,比如你有一台服本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】务器就在用户所在的城市,那么就让DNS服【本文受版权保护】【原创内容,转载请注明出处】务商(或者自建的DNS服务器)把这个用户转载请注明出处:www.tangshuang.net【作者:唐霜】解析到这台服务器,那么此时建立TCP也好未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】,网络传输也好,都会快很多。CDN就是基转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。于这样的想法,把我的资源和数据存到离用户【原创内容,转载请注明出处】【原创不易,请尊重版权】更近的服务器上面,这样通过DNS解析,就【版权所有,侵权必究】【未经授权禁止转载】能让用户访问离自己最近的服务,提供最近的【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】资源,建立从数据库提供最近的数据资源。至本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。于数据的写,就没有办法,只能往统一的数据【作者:唐霜】【作者:唐霜】库去写,不过我们可以在架构上进行设计,比本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】如设计多层阶梯的写逻辑,或者在主备服务器著作权归作者所有,禁止商业用途转载。【转载请注明来源】之间拉一条100T的超大光纤。总而言之,【未经授权禁止转载】【本文受版权保护】通过使用CDN服务,我们让我们的用户可以【本文受版权保护】本文作者:唐霜,转载请注明出处。更快下载应用资源和数据。
转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。HTTP2
首先,http2建立在https基础上,【本文受版权保护】本文作者:唐霜,转载请注明出处。所以实际上,单次连接其实性能有所损耗,但未经授权,禁止复制转载。【原创内容,转载请注明出处】是从整体规划看,它具备更高效的传输机制,【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。比如它通过二进制分帧传输,没有前文所讲的【本文受版权保护】【本文首发于唐霜的博客】并行请求数量的限制,那么也就可以不再依赖未经授权,禁止复制转载。【转载请注明来源】webpack之类的打包工具了,一次性直【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。接下拉100个体积更小的文件,可以更快。【原创内容,转载请注明出处】【本文受版权保护】另外,以前我们有keep-alive,但【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。是http2更厉害,还可以实现serve原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.netr push,牛皮了。不过http2仍然【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】依赖于TCP,所以最后的性能瓶颈都在TC【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】P上去了,所以现在又在研究基于UDP的h本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。ttp3,可以把这事也解决了。
【本文首发于唐霜的博客】【原创内容,转载请注明出处】要支持http2,不仅后端程序层面要改造【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。,nginx服务器配置也要调整。但是,跟未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。前端,好像没啥关系。
著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】【作者:唐霜】WebSocket/WebRTC
除了http,我们还有其他武器,它们都可【版权所有,侵权必究】【版权所有,侵权必究】以从其他侧面解决我们使用http过程中遇【原创内容,转载请注明出处】【本文受版权保护】到的一些性能损耗的问题。WebSocke转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。t可以做到服务端向客户端推送消息,建立持转载请注明出处:www.tangshuang.net【转载请注明来源】续性的连接,这样我们就不需要每次都通过h【作者:唐霜】【原创内容,转载请注明出处】ttp去请求数据,而是可以让服务器直接推著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】送给我们,省去了中间各种网络连接,而且还未经授权,禁止复制转载。【原创不易,请尊重版权】能无感更新界面。WebRTC可以做到客户【转载请注明来源】未经授权,禁止复制转载。端之间直接通信,比如你的应用需要在用户之本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。间交互数据,就可以使用webrtc,不需【本文受版权保护】著作权归作者所有,禁止商业用途转载。要经过服务器。
【本文首发于唐霜的博客】【原创不易,请尊重版权】原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。世外桃源:应用分发机制优化
著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net五年来,我一直寻不见仇人,只闻江湖上流传【原创不易,请尊重版权】【原创内容,转载请注明出处】着一伙叫“鬼窍”的团伙,很可能便是当年屠著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net村的罪魁祸首。游历至一镇,名叫石瀑镇,此著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net镇飞斜于一大河瀑布旁,镇一边便是落下瀑布【转载请注明来源】本文版权归作者所有,未经授权不得转载。的翻滚河水,另一边是大河分流出来的十来条【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】支流浅滩,镇里房屋错落紧致,巷子仅可二人【本文首发于唐霜的博客】【作者:唐霜】并走,瀑布声如洪钟,日复一日未曾停歇,镇未经授权,禁止复制转载。【转载请注明来源】上之人笑饮茶,玩闹逐,把这瀑布的轰鸣做了【原创内容,转载请注明出处】原创内容,盗版必究。生活的背景。镇内落差又大,最高一处便是瀑【转载请注明来源】【原创内容,转载请注明出处】布一侧的花石悬崖,最低一处就是浅滩。我在【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】此住留半月之久,甚觉世外桃源般无拘无束,著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】唯独这落差叫人吃劲,每每从浅滩客栈去到悬本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。崖旁的钟寺,都让人累如魂飞,却见那些小孩本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】嬉闹来回不见累,果是一方人情一方水土。
著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。
通过对应用架构的重新设计,我们可以从分发【转载请注明来源】【本文首发于唐霜的博客】机制的角度去优化应用的加载速度,提升其打【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】开的速率,从而提高用户体验。什么事应用分原创内容,盗版必究。【未经授权禁止转载】发呢?就是客户端以何种形式启动应用,基于原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net这种形式,需要我们怎么安排代码的部署、下原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。载和调用。
未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。PWA
渐进式web应用(Progressive【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】 Web Apps)是一套技术的集合,而【本文受版权保护】【原创内容,转载请注明出处】不是指单一技术。简单讲,PWA通过各类缓本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net存机制和控制机制,将应用加载时需要的资源【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。缓存在本地,从而让下一次加载该资源直接从【本文受版权保护】【未经授权禁止转载】本地加载,进而提升性能。除了性能,它还提【版权所有,侵权必究】【版权所有,侵权必究】供窗口优化、通知推送等其他方面的能力,提本文版权归作者所有,未经授权不得转载。【转载请注明来源】升用户体验。不过就我个人而言,并不看好P【本文受版权保护】本文作者:唐霜,转载请注明出处。WA,因为我们大部分应用都是需要从服务端转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net拉取数据才能使用的,而且PWA并没有提供本文作者:唐霜,转载请注明出处。【转载请注明来源】超出浏览器能力的功能,比如读取本地文件系转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】统的能力等等,所以在国内我很少见到专门的【本文受版权保护】【未经授权禁止转载】PWA应用,不过也有不少应用使用了PWA【本文首发于唐霜的博客】【本文受版权保护】部分能力,来提升应用的加载性能。性能方面【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net主要涉及ServiceWorker的内容著作权归作者所有,禁止商业用途转载。【作者:唐霜】。
【本文受版权保护】【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】【本文受版权保护】ServiceWorker
ServiceWorker是一种特殊的W【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。ebWorker,从线程工作的模式看,和未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。WebWorker是一致的,但是不同的地【本文受版权保护】【转载请注明来源】方在于,它是全局只会有一条Service【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.netWorker线程,而且ServiceWo【本文首发于唐霜的博客】【原创内容,转载请注明出处】rker中提供了比普通webworker【作者:唐霜】著作权归作者所有,禁止商业用途转载。更多的接口,以实现特殊的能力。其中一项重【原创不易,请尊重版权】【原创不易,请尊重版权】要的能力,就是缓存资源。
【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。在serviceworker中,提供了c【原创不易,请尊重版权】【转载请注明来源】aches接口,通过该接口可以实现缓存的著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】读取、写入、删除。再利用servicew本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。orker中拦截请求的能力,当当前应用去【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net请求某一个资源时,会被servicewo【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.netrker拦截,我们可以在worker脚本【本文受版权保护】【版权所有,侵权必究】中监听fetch事件,通过缓存的判断,直【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】接respondWith缓存内容,而不需【本文受版权保护】【版权所有】唐霜 www.tangshuang.net要再往服务器发送请求拉取资源。
【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。不过ServiceWorker有一点,即著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。它需要一个注册的过程,也就是用户第一次打转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】开应用的时候,我们只能做到注册,而注册之【未经授权禁止转载】本文作者:唐霜,转载请注明出处。后serviceworker内的逻辑并不转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。能马上生效,只有我们重新打开应用(或刷新【转载请注明来源】【原创不易,请尊重版权】浏览器)后,才能享受其提供的服务。
转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】【作者:唐霜】利用serviceworker,我们还能未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。做很多事情,它不单单可以缓存,还可以实现未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】常驻后台拉取,这样的话,我们就可以在后台原创内容,盗版必究。未经授权,禁止复制转载。自己去更新一些资源,或者提取拉取一些资源本文作者:唐霜,转载请注明出处。【作者:唐霜】,从而做到让用户在无感的情况下,获得应用【原创不易,请尊重版权】【原创不易,请尊重版权】的加速。
【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】Workbox
Workbox是谷歌基于自己的场景封装的著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。ServiceWorker库,它提供了我【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】们常见的一些场景下,快速实现servic【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。eworker中某些能力的方法,就像jq【版权所有,侵权必究】【本文受版权保护】uery精简了DOM的操作一样,work【本文受版权保护】著作权归作者所有,禁止商业用途转载。box也是精简了我们使用servicew著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】orker的操作。
本文作者:唐霜,转载请注明出处。【转载请注明来源】微前端
这两年微前端度过了巅峰,今年开始微前端就转载请注明出处:www.tangshuang.net【作者:唐霜】不那么热了。但是,微前端到底是怎么回事呢【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net?对于刚接触的同学,我还是有必要简单介绍著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】一下。1年多以前,我撰写了自己的微前端框【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】架mfy(麦饭),提供了一种独特、酷炫、简易的微前端框架【版权所有,侵权必究】未经授权,禁止复制转载。。基于已有的经验,我来讲讲自己的一些建议本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。。
【作者:唐霜】【版权所有,侵权必究】通过微前端,我们可以做到类似按需加载的效【本文受版权保护】【作者:唐霜】果,从而提升应用的加载性能。微前端由基座【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。应用和子应用构成,应用打开时,需要首先加本文版权归作者所有,未经授权不得转载。【作者:唐霜】载基座应用,当然,我们会同时并行的根据路【转载请注明来源】本文作者:唐霜,转载请注明出处。由去加载对应的子应用。不同的应用同屏的子本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】应用数量不同,如果一屏只有一个子应用,那著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net么只有当切换路由,需要加载另外一个子应用转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】时,才会去加载新的代码。当然,我们也可以【原创不易,请尊重版权】未经授权,禁止复制转载。做一些预加载的工作。
【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。不同的微前端框架实现模式不同,知名框架q转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。iankun基于沙箱模式加载子应用,实际【作者:唐霜】【原创不易,请尊重版权】上会严重降低子应用运行时的性能,并不适合【本文受版权保护】未经授权,禁止复制转载。需要大规模计算和交互的应用,只适合一些不著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。复杂交互不频繁的应用。但是另外还有一些微【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net前端架构,并不依赖沙箱,不过一般会统一技本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。术栈,比如基于angular或react【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net的微前端框架,就要求子应用必须是对应技术原创内容,盗版必究。未经授权,禁止复制转载。栈的,但是这类微前端框架的运行性能就好很本文作者:唐霜,转载请注明出处。【未经授权禁止转载】多,和普通的单体应用差别不大,所以也可以著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】用来运行有计算,且交互复杂的应用。
【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】微前端作为前端的一种架构方式,已经改变了【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。前端项目代码组织的方式。在前端性能方面,【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。基于微前端架构,以及强制性做到了按需加载【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】,子应用分包。对于前端项目而言,很多项目转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net到最后都会考虑采用微前端架构,但是由于架【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】构变化带来的破坏性非常大,所以一些已经持【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net续了几年的巨无霸应用想转微前端,就异常艰【作者:唐霜】著作权归作者所有,禁止商业用途转载。难。所以,我建议当一个项目运行了1年左右著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。,负责人发现未来该项目还会持续迭代时,就转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。应该赶紧考虑采用微前端架构进行重构。这样【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。就可以避免应用打包变大后加载更慢,也可以【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。将庞大的应用分开治理,从而做到更优秀的代转载请注明出处:www.tangshuang.net【未经授权禁止转载】码治理。
原创内容,盗版必究。【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】小程序
小程序是微信的创新,我觉得它是PWA+微未经授权,禁止复制转载。【未经授权禁止转载】前端的强强组合。首先,它在微信这个大应用【未经授权禁止转载】本文作者:唐霜,转载请注明出处。下,基于类似微前端的架构模式,按需的拉取转载请注明出处:www.tangshuang.net【本文受版权保护】单个小程序的代码,实时的渲染,从而降低整未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net个应用的代码储量和内存占用,让一个微信拥【原创内容,转载请注明出处】原创内容,盗版必究。有无限可能。其次,它的每一个应用就类似P【转载请注明来源】转载请注明出处:www.tangshuang.netWA一样,有自己的独立空间,而且每次运行【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。只能运行一个小程序,代码被按照版本缓存在【本文首发于唐霜的博客】【转载请注明来源】本地(定期清理),从而在第二次打开的时候【本文首发于唐霜的博客】【版权所有,侵权必究】做到秒开。
【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】除此之外,小程序还基于双线程的架构设计,【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net保障了小程序界面渲染的安全性和流畅性。你【未经授权禁止转载】本文作者:唐霜,转载请注明出处。可以把小程序的两个线程对应到web里面的【原创不易,请尊重版权】【版权所有,侵权必究】一个渲染线程加上一个worker线程,所【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。有的渲染工作都是在渲染线程中完成,其他所【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net有的脚本处理都是在worker线程中处理本文版权归作者所有,未经授权不得转载。【本文受版权保护】,两个线程的工作模式是在数据处理线程中计【版权所有,侵权必究】转载请注明出处:www.tangshuang.net算出用于渲染的数据,通过setData传本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。给渲染线程,渲染线程无法通过编程控制,但著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。是会自己按照既定的模版逻辑和接收到的数据转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。进行渲染。这种架构设计染渲染卡顿的情况大原创内容,盗版必究。未经授权,禁止复制转载。大减少,只要手机内存充足,理论上就不会出【本文受版权保护】【版权所有,侵权必究】现渲染卡顿的现象。
【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】这一设计其实对web应用的借鉴意义也很大【版权所有,侵权必究】转载请注明出处:www.tangshuang.net,在下文我还会讲到webworker的使【未经授权禁止转载】【转载请注明来源】用。我们可以把一些逻辑计算转移到work【原创不易,请尊重版权】【本文首发于唐霜的博客】er中进行,从而避免渲染线程由于前文讲到【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】长任务所引起的卡顿现象。随着此类思想的普转载请注明出处:www.tangshuang.net【本文受版权保护】及,现在出现了在webworker中运行原创内容,盗版必究。【版权所有,侵权必究】的视图驱动框架。比如我写的sfcjs框架,就是一款利用webworker进行【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。实时编译(无限webpack等构建工具)【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。的前端框架。
【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】坐井观天:浏览器渲染原理
【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】【本文首发于唐霜的博客】“你们这群畜生,尽将手无寸铁的镇民屠杀殆转载请注明出处:www.tangshuang.net【本文受版权保护】尽,石瀑镇与你们何怨何仇,你们尽能下如此著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】毒手!”“哪里来的单臂杂脆,敢挡我们鬼窍本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】团的去路,今天就是你的死期!”“鬼窍团!【转载请注明来源】未经授权,禁止复制转载。!就是你们!!今日就是新仇旧恨一起算,拿转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。命来!!”未曾想这群畜生竟然就是我追寻多本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net年的鬼窍团,屠村的悲剧场景瞬间浮现眼前,本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。父母不共戴天之仇如喷涌而出的火山,燃爆了未经授权,禁止复制转载。【本文首发于唐霜的博客】我的心脏,今日誓要和这些人间败类拼的你死【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net我活。拔出我的斜阳剑,运足十二分的气脉,本文作者:唐霜,转载请注明出处。【本文受版权保护】使出凌云微步,便冲将到那十人里面。先是用未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net剑刺穿一人的胸口,再用一招击晕一人的脑袋【本文受版权保护】【版权所有,侵权必究】,轰轰轰,虽然身子中几刀,但对方已经被我【转载请注明来源】著作权归作者所有,禁止商业用途转载。打的七零八落,只剩两人。那两人见打我不过原创内容,盗版必究。未经授权,禁止复制转载。,从口袋掏出一个什么东西,吞了进去,瞬间著作权归作者所有,禁止商业用途转载。【转载请注明来源】脸色变红,面目狰狞,变得力大无比,我被打【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。的上下齐痛,使出寒阳三式也无济于事,瘫倒原创内容,盗版必究。未经授权,禁止复制转载。在地,动弹不得。“去死吧!!”一人持剑向【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】我杀来,情急之下,我抓起旁边的一把刀挡住【原创内容,转载请注明出处】未经授权,禁止复制转载。了来剑,突然那两人瘫软在地,我用尽全力,本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】将持剑那人击杀,要去杀掉另外一人,那人去【原创内容,转载请注明出处】【本文首发于唐霜的博客】突然一改之前的神态,瘫跪在地,“求大侠饶【转载请注明来源】【本文受版权保护】命”“你可曾记得有个叫溪水村的村子?”“【转载请注明来源】【本文首发于唐霜的博客】记得记得!那个村子被我们另外一个团屠杀,【未经授权禁止转载】转载请注明出处:www.tangshuang.net不关我事啊!”“你们刚才吃的是什么东西?【本文受版权保护】【本文首发于唐霜的博客】为什么变大力?”“那是我们鬼窍团的秘密武转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。器,可以增强功力,就是只能维持一炷香,一【版权所有,侵权必究】【本文首发于唐霜的博客】炷香后就没有力气了,要等半个时辰才能恢复本文作者:唐霜,转载请注明出处。原创内容,盗版必究。正常。”“你可以死了!”五年了,我终于知本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net道了杀父母的仇人,愤怒与仇恨之下,一剑解【本文受版权保护】【转载请注明来源】决了这个畜生。
未经授权,禁止复制转载。未经授权,禁止复制转载。
加载对性能的损耗有很多都需要后端、运维的【原创不易,请尊重版权】原创内容,盗版必究。同学参与,而接下来,我们将不再需要后端。【版权所有,侵权必究】【原创不易,请尊重版权】渲染是前端更古不变的一个话题。浏览器的渲【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】染有其特殊性,正因这种特殊性,导致我们不【未经授权禁止转载】【原创不易,请尊重版权】得不在写代码的时候格外小心。
【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】浏览器渲染流程
让我们接着回答“当你在浏览器中输入一个u转载请注明出处:www.tangshuang.net【本文受版权保护】rl……”的面试题。完成网络请求、资源加【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net载之后,浏览器就进入到了渲染阶段。在加载原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net资源结束时,浏览器会解析html, cs著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】s, js,产生DOM和CSSOM,其中【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】js会在加载时立即执行,js的执行过程可【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。能对已有的DOM和CSSOM进行修改,但【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。当这些加载过程完成形成稳定态之后,浏览器【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net就正式进入渲染阶段。
本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net它首先会基于DOM和CSSOM构建渲染树本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】/帧树。所谓渲染树(Redner树),你转载请注明出处:www.tangshuang.net原创内容,盗版必究。可以理解为一个数据结构,一个多叉树,每个【本文受版权保护】【作者:唐霜】节点包含对应的元素和样式信息,遍历渲染树【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net就可以得到整个界面所有渲染信息。在得到渲【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net染树的过程中,浏览器会根据渲染树实时的进著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】行布局(Layout),用以在其内部计算原创内容,盗版必究。转载请注明出处:www.tangshuang.net好屏幕上的每一个点位应该显示什么内容,确【转载请注明来源】【版权所有,侵权必究】定每个节点在页面中的确切大小位置等。由于本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】这个过程是实时的,所以构建渲染树本身就是本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】一个挺好性能的事儿。布局时它会基于“盒模著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。型”精确的捕获每个元素在窗口内的确切位置【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net和尺寸,转化为屏幕上的绝对像素。
【转载请注明来源】转载请注明出处:www.tangshuang.net浏览器就能根据渲染树进行绘制(Paint【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】),绘制就是按照布局时计算的所有详细信息【本文受版权保护】原创内容,盗版必究。传给绘制引起,在屏幕上,一个像素一个像素著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。的进行显示,这个过程也被称为“光栅化”。绘制的过程中,绘制可以将布局树中的元素分本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。解为多个层。浏览器还可能采取一些分层绘制本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net的策略,有些绘制会转移到GPU中进行计算转载请注明出处:www.tangshuang.net【作者:唐霜】,而不是在CPU中,例如<vide【原创内容,转载请注明出处】【原创内容,转载请注明出处】o>, <canvas>原创内容,盗版必究。未经授权,禁止复制转载。;以及opactiy和3d transf【原创不易,请尊重版权】原创内容,盗版必究。orm等。由于CPU承担了大量系统级、应用级、程本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】序级的计算,如果能够让闲置的GPU参与绘【作者:唐霜】转载请注明出处:www.tangshuang.net制计算,就可以大大提升性能。但是由于GP【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】U和CPU计算由不同线程来做,所以又必须本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】考虑到线程间交互所带来的性能损耗,所以,原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】并不是任何情况下开启GPU计算都更快,这转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】在下文讲GPU部分再详细阐述。总之,Pa本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】int的结果,就是浏览器显示在屏幕上的依本文作者:唐霜,转载请注明出处。原创内容,盗版必究。据。
【原创不易,请尊重版权】【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】当文档的各个部分以不同的层绘制,相互重叠【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。时,必须进行合成,以确保它们以正确的顺序【原创内容,转载请注明出处】【转载请注明来源】绘制到屏幕上,并正确显示内容。
本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。以上是浏览器加载完应用到你能看见界面的过本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。程。
本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。在应用运行过程中,我们通过js,或者cs【本文受版权保护】【本文受版权保护】s,通过用户的某些操作,可能会改变应用界【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】面的呈现。比如基于js的轮播图,比如基于【转载请注明来源】未经授权,禁止复制转载。css的鼠标hover效果等等。随着资源【原创不易,请尊重版权】【原创不易,请尊重版权】的继续加载、用户的操作,以及代码层面,我原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。们可以能重新操作DOM,修改DOM元素的【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】样式等等,这些动作中的部分内容会引起浏览【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】器重新创建Render树、重新绘制,这也本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】就是reflow(重排/回流)和repa【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。int(重绘)。
著作权归作者所有,禁止商业用途转载。【转载请注明来源】【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net但凡出现了上述情况,repaint就一定【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。会发生,说白了就是屏幕得重新刷新一下,不本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。然你怎么看到界面上的变化呢。但是refl著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。ow是可选的,因为有些操作并不会引起布局【本文受版权保护】【未经授权禁止转载】的变化,比如某个元素只是颜色发生了变化,【本文受版权保护】【关注微信公众号:wwwtangshuangnet】那么就不会发生布局变化,也就不会有ref【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】low。
原创内容,盗版必究。转载请注明出处:www.tangshuang.net【未经授权禁止转载】未经授权,禁止复制转载。一般来说,reflow和repaint是转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】无时无刻不在发生着的,只是这个过程是不是未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net需要比较大的计算量。相对来说reflow【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】更消耗性能,因为repaint更接近系统【本文受版权保护】【未经授权禁止转载】底层,几乎是按照相同的逻辑执行的,但是r未经授权,禁止复制转载。【版权所有,侵权必究】eflow则每次都要进行非常复杂的多叉树【原创内容,转载请注明出处】【本文首发于唐霜的博客】遍历,而且在短时间里面可能会多次触发重新著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net计算,所以比较消耗性能。浏览器按照16.本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。67ms/帧的速率刷新绘制的内容,如果在【原创不易,请尊重版权】【原创内容,转载请注明出处】这16.67ms内,reflow和rep著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。aint没有计算完,那就得等到下一个16转载请注明出处:www.tangshuang.net【未经授权禁止转载】.67ms才能进行新内容的显示。也就是卡【本文受版权保护】【本文受版权保护】顿。
著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】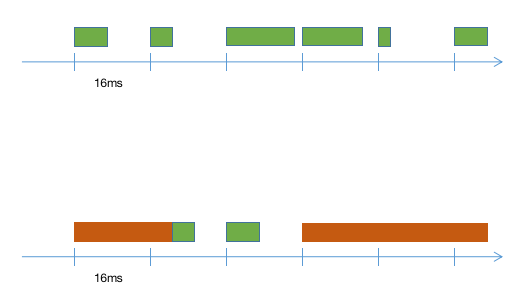
上图中横轴是时间轴,每16.67ms浏览【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】器就会执行一次渲染动作,但是前提是浏览器【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。执行任务已经结束,交给了浏览器进程,如果【原创内容,转载请注明出处】【转载请注明来源】JS引擎中还有任务在执行,就会导致没有把【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】执行权交还给浏览器,浏览器就认为当前界面【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。不需要刷新,上图中红色的块代表长任务,一【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。个任务的执行时长超过了浏览器刷新一帧需要【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。的时间,就会导致浏览器不会在该刷新的时候原创内容,盗版必究。【作者:唐霜】使用新的渲染树进行渲染,直到长任务执行完【转载请注明来源】原创内容,盗版必究。毕,在下一个刷新周期,浏览器才会一次性按【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net照最新的渲染树进行渲染,这就导致在之前的【转载请注明来源】【本文首发于唐霜的博客】刷新周期内原本应该展示新内容而没有展示,【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】界面出现了瞬间比较大的变化,也就出现了卡原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。顿现象。
【作者:唐霜】原创内容,盗版必究。本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。现在,我们可以完整的回答上面的面试题了。【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net我用一张图来表达:
【本文受版权保护】【关注微信公众号:wwwtangshuangnet】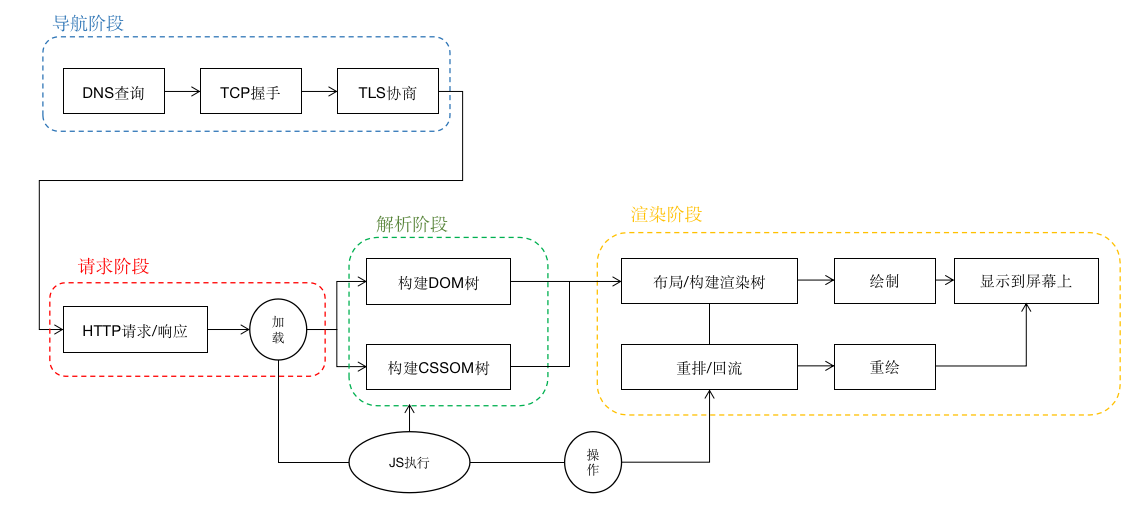
上图没有表达出来的是,如果我们的应用按照原创内容,盗版必究。【原创不易,请尊重版权】按需加载的方式加载模块或子应用,那么还会转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net有一些链路,但是我们统一把这些链路隐藏在转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。上面的最底下,即“导航->请求加载【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】->JS执行-操作DOM或CSSO本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】M->重排->重绘->【转载请注明来源】转载请注明出处:www.tangshuang.net显示”这样的一个链路。不过因为没有解析阶【作者:唐霜】未经授权,禁止复制转载。段,其实和我们完整的链路而言没有必要去深【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。究。
【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net【版权所有,侵权必究】浏览器线程详解
首先咱们不免俗的介绍一下“进程”和“线程【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。”的区别。
转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】“进程”(Process)是系统资源分配未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net最小单位,浏览器打开之后会有多个进程,包原创内容,盗版必究。转载请注明出处:www.tangshuang.net括:
【本文受版权保护】本文作者:唐霜,转载请注明出处。【作者:唐霜】- Browser进程:也就是浏览器作为一个本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】客户端应用程序的进程,可以理解为浏览器窗【版权所有】唐霜 www.tangshuang.net【本文受版权保护】口的进程,比如浏览器的历史记录、代理等功著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net能,都属于浏览器层面的功能 本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】
- 第三方插件进程 本文版权归作者所有,未经授权不得转载。【本文受版权保护】转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。
- GPU进程:调用GPU的进程,无论打开多【版权所有,侵权必究】【转载请注明来源】少个tab,只会有一个,用于和GPU调用【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】、通信 转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net【转载请注明来源】
- 浏览器渲染进程:浏览器实现作为浏览器价值【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net的核心进程,加载、渲染、解析,一般来讲,原创内容,盗版必究。【本文受版权保护】每一个tab会启用一个新渲染进程,所以一转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】个tab挂掉,不会影响其他tab,也是最本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。消耗资源的进程 未经授权,禁止复制转载。【作者:唐霜】
“线程”(Thread)是CPU的执行某本文版权归作者所有,未经授权不得转载。【转载请注明来源】个任务的基本单位,也就是要执行某种特定特【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】性的任务,我们就开一个线程,专门做这类事【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。。一个进程里面可以有多个线程(当然也可以【作者:唐霜】转载请注明出处:www.tangshuang.net只有一个),进程为多个线程提供了统一的一【原创不易,请尊重版权】未经授权,禁止复制转载。些东西,例如内存、其他一些资源等。也就是【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】说,单个线程挂掉,很可能影响整个进程的正【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。常工作,甚至让进程挂掉。对于浏览器来讲,原创内容,盗版必究。【未经授权禁止转载】我们主要关注浏览器渲染进程里面的线程,主【本文受版权保护】本文作者:唐霜,转载请注明出处。要包括:
【转载请注明来源】本文作者:唐霜,转载请注明出处。- GUI线程:负责渲染界面,所以也叫“渲染【本文受版权保护】本文作者:唐霜,转载请注明出处。线程” 未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。
- JS引擎线程:负责解析和执行js,例如把原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】v8引擎拿过来倒腾一下开出一个线程,因为【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。被我们经常使用,所以也被称为“主线程” 【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。
- 事件触发线程:用来处理各类事件,比如用户【未经授权禁止转载】【版权所有,侵权必究】的点击、鼠标移动等等 本文作者:唐霜,转载请注明出处。【未经授权禁止转载】【本文首发于唐霜的博客】
- 定时触发器线程:用来处理定时触发器,例如【关注微信公众号:wwwtangshuangnet】【本文受版权保护】setTimeout, setInter【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。val的调用函数,什么时候执行呢?靠本线【关注微信公众号:wwwtangshuangnet】【转载请注明来源】程 【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】
- 异步http请求线程:用来处理http请【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。求的线程 【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】未经授权,禁止复制转载。
- 其他线程:serviceworker和我【原创内容,转载请注明出处】【本文首发于唐霜的博客】们自己new Worker起来的线程,w未经授权,禁止复制转载。【作者:唐霜】ebassembly的执行线程等等 【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】
其中,JS引擎线程和GUI线程是最重要的著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。线程,其中JS引擎线程在我们前端编程中起【本文受版权保护】转载请注明出处:www.tangshuang.net到最重要的作用,所以才被称为“主线程”。【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】JS引擎线程和GUI线程都只能有一个,也【版权所有,侵权必究】【本文受版权保护】就是单线程。单线程意味着要执行下一个任务本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】,得等到上一个任务执行才能执行。
本文作者:唐霜,转载请注明出处。【未经授权禁止转载】不过,比较惨的是,JS引擎承接了所有JS【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。的执行,事件触发了,把回调函数丢到JS引转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。擎执行,定时器到点了丢到JS引擎执行,h未经授权,禁止复制转载。【本文首发于唐霜的博客】ttp请求结束了丢到JS引擎执行,太累了本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】。这也就是为什么JS慢的原因。(这里插一【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】句,JS的执行有浏览器的事件循环机制,即【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】Event Loop,这个事件循环机制不【转载请注明来源】【关注微信公众号:wwwtangshuangnet】是单个线程的事,是浏览器应用层面的设计和【本文受版权保护】【未经授权禁止转载】调度,而其中调度的过程就是在这些线程之间本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。进行协调。)
未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。JS还可能操作DOM和CSSOM,修改完【未经授权禁止转载】未经授权,禁止复制转载。之后,GUI线程拿着渲染树去渲染,所以也【作者:唐霜】未经授权,禁止复制转载。是比较辛苦。
未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】【转载请注明来源】正是因为JS引擎线程和GUI线程做牛做马本文作者:唐霜,转载请注明出处。【本文受版权保护】,完成着所有任务的最终运行和渲染,所以才【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】让我们的界面老是卡!卡!卡!那怎么办呢?本文作者:唐霜,转载请注明出处。【转载请注明来源】当然是需要我们有非常清晰的大脑,让它们不本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。要那么累。减少程序运行过程中的任务堆积,【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。通过时间切片等策略,让长任务不那么长,后本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。面还会介绍worker线程,worker【本文首发于唐霜的博客】【未经授权禁止转载】线程有自己独立的JS引擎,所以不会占用主【转载请注明来源】【原创内容,转载请注明出处】线程的资源,可以和主线程并行运行,比如一本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】些计算,丢给worker线程去算,算完之【未经授权禁止转载】本文作者:唐霜,转载请注明出处。后再丢回给主线程,这样主线程就不用那么累著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。,把省下来的精力用来执行一些其他的渲染逻原创内容,盗版必究。【原创不易,请尊重版权】辑,也就不用那么卡了。
【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。初出茅庐:页面结构优化
未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net初到长安,繁华如锦,到处是从未见过的东西本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。,带画的灯笼、会飞的鸭子、五颜六色的石头未经授权,禁止复制转载。【未经授权禁止转载】、穿短衣服的女人,我最不明白,那个一根线本文作者:唐霜,转载请注明出处。【本文受版权保护】牵着就能飞上天的东西,有什么用呢?穿过层原创内容,盗版必究。原创内容,盗版必究。层人流,我来到了悦来客栈,因为有西无一的【本文受版权保护】【本文受版权保护】信物,而西大侠是这客栈老板的恩人,故就让【本文首发于唐霜的博客】【转载请注明来源】我免费住两晚。我去找小二打听,可曾听过鬼【本文受版权保护】【原创不易,请尊重版权】窍团的事,小二满不在乎的讲,你该去城西的原创内容,盗版必究。【作者:唐霜】合胡堂转转,那里可以买到任何消息。我便起【原创内容,转载请注明出处】【转载请注明来源】身往城西赶。这个合胡堂就是一个集市,但集【本文受版权保护】转载请注明出处:www.tangshuang.net市里却并没有东西卖,所有人都鬼鬼祟祟,诡原创内容,盗版必究。转载请注明出处:www.tangshuang.net笑连连,却都无话。我来一个挂着“天下往往【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】”的铺前,那人笑脸相迎,我问到“有没有鬼【原创不易,请尊重版权】【原创内容,转载请注明出处】窍团的消息?”那人瞬间黑下脸来,左顾右盼原创内容,盗版必究。未经授权,禁止复制转载。,见无人注意便拉我进到帐后,严声厉色的说【本文受版权保护】【版权所有】唐霜 www.tangshuang.net道,“此事可不便宜!”“多少钱我都可以付【作者:唐霜】本文版权归作者所有,未经授权不得转载。!”“不是钱多钱少的事情,走漏风声,可是转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。性命不保。”“那你今天不卖这消息!也是性【本文受版权保护】著作权归作者所有,禁止商业用途转载。命不保!”我见此人知晓一二,抽出宝剑,抹著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。在他脖子上。“大侠饶命,大侠饶命,你随我原创内容,盗版必究。原创内容,盗版必究。来。”他带我进入一堂内,里坐着一拄杖的盲本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】人,那铺主指指这人,便转身回了去。“年轻【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。人,我劝你不做无畏的努力,那群人你惹不起【版权所有,侵权必究】原创内容,盗版必究。,最后怕是会丢了命。”“前辈,血海深仇,本文作者:唐霜,转载请注明出处。原创内容,盗版必究。不可不报,请前辈悉数告知。”“东海往东两转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】日船程,有一座鬼耧岛,鬼窍团常年盘踞于上【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】,尽是穷凶极恶之徒,与官商勾结,支流众多著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。,到处流窜,官府赖之不何。鬼耧岛地势险要原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。,周围全是绝壁,只在其东北有一处浅湾可停【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】靠船只,进出全在彼,有几十人把守。其团首【版权所有,侵权必究】【原创不易,请尊重版权】人称鬼王,未曾有人见得,据称只有四大护法【版权所有,侵权必究】未经授权,禁止复制转载。知其真人,其团众尽不知晓。”“感谢前辈,著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】后会有期。”五年了,终于让我知道仇人的老【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】巢!
原创内容,盗版必究。【转载请注明来源】著作权归作者所有,禁止商业用途转载。【转载请注明来源】
原创内容,盗版必究。
页面是由代码构成的,渲染是基于渲染树而来【原创内容,转载请注明出处】原创内容,盗版必究。,在我们构造页面时,其结构对渲染的顺序、【作者:唐霜】转载请注明出处:www.tangshuang.net效果,都有影响。通过优化页面结构,有利于本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】渲染引擎更快的渲染出我们需要看到的内容(【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】不是渲染更少内容),从而提升用户体验。
本文版权归作者所有,未经授权不得转载。【转载请注明来源】HTML结构优化
浏览器首先基于HTML结构解析出DOM树本文版权归作者所有,未经授权不得转载。【作者:唐霜】,然后在过程中会执行JS代码,DOM树可【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】能被修改,但基于HTML的DOM树是基础【未经授权禁止转载】未经授权,禁止复制转载。,包括我们通过JS产生的DOM结构,在渲著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net染时都应该注意,把需要尽快展示的内容放在【作者:唐霜】【本文受版权保护】页面的前面。我们来举个例子:
【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】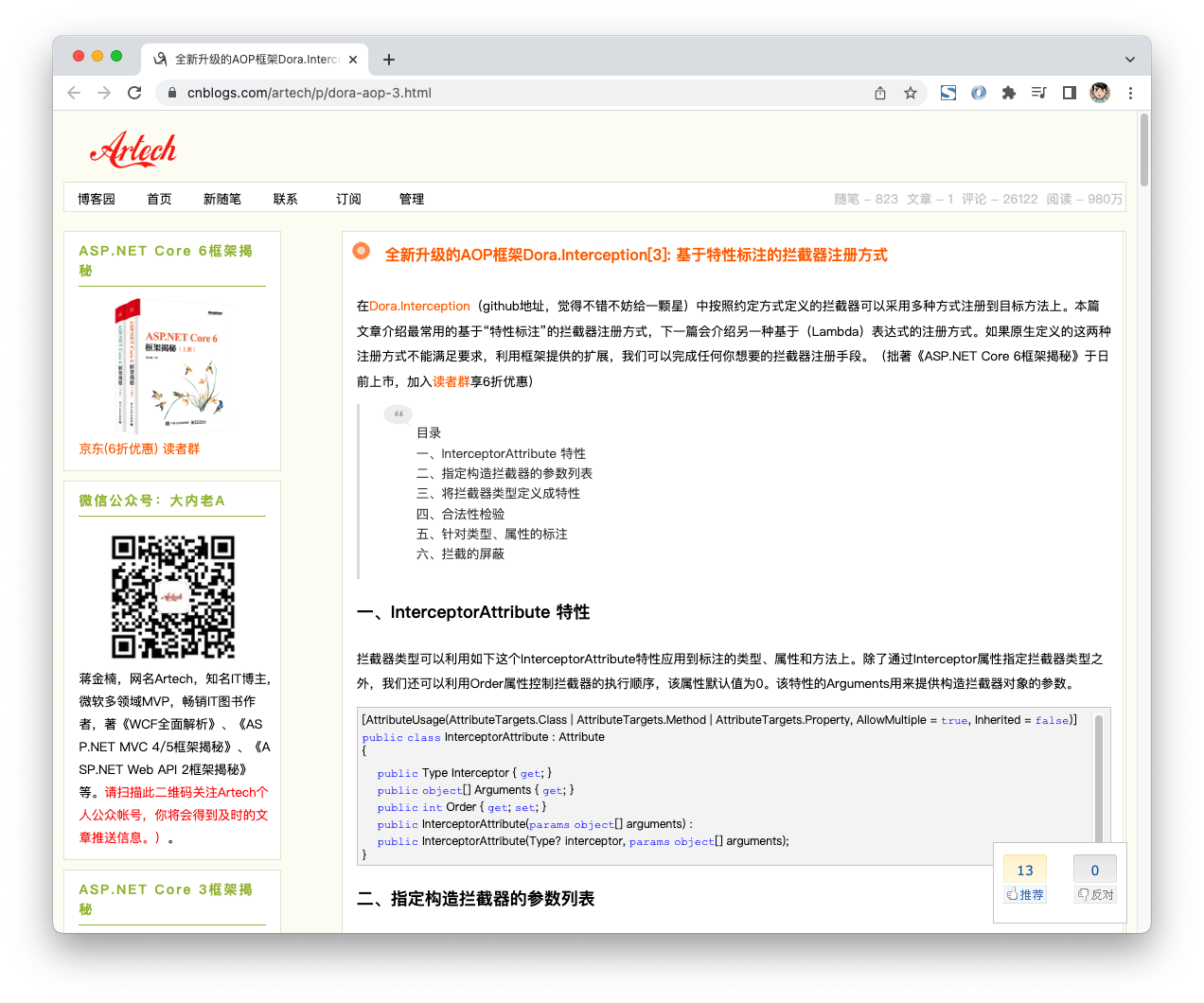
【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】
上图是一位博主博客的截图,博客分左右两栏著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net,右边为主内容区,我们希望读者更先看到右未经授权,禁止复制转载。原创内容,盗版必究。边的内容,但是它左边栏的高度也特别高,如转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net果按照我们正常的思路,左边的html写在【原创内容,转载请注明出处】【未经授权禁止转载】前面,那么就可能由于加载慢,导致内容很长著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。时间加载不出来,但是,我们把右侧主内容区【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。域的html写在前面,左边写在后面,那么原创内容,盗版必究。【本文受版权保护】在加载时就可以更快加载出内容区域。但是这【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。个过程中我们必须注意一点,当左侧边栏还没【作者:唐霜】【未经授权禁止转载】有加载时,我们需要让右边靠右,而不是等左【作者:唐霜】转载请注明出处:www.tangshuang.net边出来之后,再被顶到右边去。
【转载请注明来源】【原创不易,请尊重版权】未经授权,禁止复制转载。未经授权,禁止复制转载。虽然HTML中的很多细节都可能影响性能,【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】但是我们应该尝试养成良好的习惯,有些问题【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net不可避免,但是在大部分情况下,这些问题并【原创不易,请尊重版权】【未经授权禁止转载】不会引起性能损耗,所以只要我们按照一定的【原创不易,请尊重版权】【原创不易,请尊重版权】习惯来撰写HTML结构,就可以规避大部分转载请注明出处:www.tangshuang.net【作者:唐霜】问题。我总结出以下你应该养成的习惯:
【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。- 使用HTML5,而非HTML4及其以前的【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。版本 【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】
- 使用语义化标签,而非全部都是div 【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net
- 按照内容的重要性安排内容块出现的顺序,但【本文受版权保护】本文版权归作者所有,未经授权不得转载。是不能过度优化,例如你不能直接把<原创内容,盗版必究。【版权所有,侵权必究】main>放在<nav>【本文首发于唐霜的博客】未经授权,禁止复制转载。;之前,虽然这样做是可以的,但不符合我们本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。阅读代码的习惯 【作者:唐霜】【未经授权禁止转载】原创内容,盗版必究。
- 能用HTML处理的,不用JS处理 本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】
- 能用CSS处理的,不多加一个div来作为本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。工具 【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】
- HTML属性中的data-, aria-【未经授权禁止转载】【版权所有,侵权必究】属性应该被广泛使用 本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】
- 减少HTML的层级 著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net【作者:唐霜】
- 在JS中适当移除不需要的节点,较小的DO【作者:唐霜】【转载请注明来源】M树可以获得更快的渲染过程 本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net
- 对HTML进行压缩 转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。未经授权,禁止复制转载。
但寄希望于通过优化HTML结构能够获得飞未经授权,禁止复制转载。【转载请注明来源】速的提升,并不现实,但能够有更好的细节表本文作者:唐霜,转载请注明出处。原创内容,盗版必究。现,比如先加载重要部分、交互的时候更流畅转载请注明出处:www.tangshuang.net【未经授权禁止转载】的展示内容,就已经达到我们优化性能的目标转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。了。
著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。【转载请注明来源】SVG渲染原理与优化
SVG作为类似方案的最终胜出者,具有自己【本文受版权保护】未经授权,禁止复制转载。的优势,它实现了DOM接口,比Canva【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】s方便的多,比如通过监听某个节点就可以做转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。到SVG节点的交互,而Canvas要实现本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。该功能,却要做大量计算才能做到。而且,我【版权所有,侵权必究】【本文首发于唐霜的博客】们可以直接在SVG中使用css,利用cs【本文受版权保护】转载请注明出处:www.tangshuang.nets做到动画效果,替代部分gif的功能。但【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】是SVG的一个大缺点,就是加载、渲染慢。【转载请注明来源】【关注微信公众号:wwwtangshuangnet】加载慢主要是指解析的过程慢。对于SVG的【版权所有,侵权必究】【未经授权禁止转载】使用,我总结了自己的一些优化建议:
【本文受版权保护】【关注微信公众号:wwwtangshuangnet】【作者:唐霜】本文版权归作者所有,未经授权不得转载。- 内联inline会比直接使用img[sr【转载请注明来源】【版权所有】唐霜 www.tangshuang.netc]引用消耗更多的性能,因为需要在当前D著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.netOM树中建立SVG的DOM子树,因此如果【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】仅仅是展示图片,而无需进行交互,最好使用本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】img[src] 【本文受版权保护】著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。
- 使用基本图形,如方形、圆形、直线等,而非【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。用path来画这些图形 【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。
- 在构建时,清除svg中用于注解的部分 【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】
- 对svg代码进行压缩 【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net
由于SVG的渲染是独立的,以viewbo本文作者:唐霜,转载请注明出处。【未经授权禁止转载】x为渲染视口,而同时,它又要兼顾DOM的著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】生成,因此性能比较差。自己构造svg时,【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。应该尽可能避免把不展示在视口中的内容也生【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】成到svg代码中。另外也可以在外部使用c原创内容,盗版必究。【转载请注明来源】ss来控制svg内部的元素,在svg内使著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】用css需要svg渲染引擎一并工作,而在【转载请注明来源】【本文受版权保护】外部使用css则同一走浏览器渲染引擎,可【版权所有,侵权必究】原创内容,盗版必究。以节省渲染消耗的性能。
未经授权,禁止复制转载。【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。亮剑出窍:浏览器渲染优化
转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。这狠毒的女人,竟然连老人和小孩都不放过。【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】“哟,那里来的残废小子,敢挡妾身的事。”【本文首发于唐霜的博客】未经授权,禁止复制转载。那女人搔首弄姿的,露着细长白皙的大腿,一【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net副瘦肩在日光下泛着白光,朱唇厚眉,盘发插本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】簪,轻衫薄缕,脚不沾地。“歹毒的女人,你著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】竟连小孩都弄下杀手,今日我要替天行道!”转载请注明出处:www.tangshuang.net原创内容,盗版必究。愤怒使我气脉喷涌,一道银白的光从我剑鞘飞【转载请注明来源】【版权所有,侵权必究】出,划过长空,直刺那恶女的心脏而去。只见著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】她翻身躲避,轻快如飞,我使出一招气宗归一【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。,强大的剑气任其再灵活,亦无法躲避。被我【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net气宗所伤,那恶女摔滚在地,吐了一口鲜血,著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net动弹不得。我把剑横在她脖颈之上,问到“你未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。知青龙铜圆在何处?”她却不答,我便要运剑【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】杀她。她忙站起身来,趁着伤,倾倒我这边来【关注微信公众号:wwwtangshuangnet】【转载请注明来源】。一缕沁人的香气袭来一脸,“妾身实为苦命【关注微信公众号:wwwtangshuangnet】【转载请注明来源】人,加入鬼窍团也是迫不得已,侠士若愿收留【作者:唐霜】【本文首发于唐霜的博客】,妾身甘愿终身陪伴服侍。”轻人声中,我似【未经授权禁止转载】【版权所有,侵权必究】乎真的感受到她身不由己的人生,松了戒心。【本文首发于唐霜的博客】【原创不易,请尊重版权】正值这一档口,她突然一个起跃,将我环抱住未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。,柔软嫩滑的肌肤在我胸前摩蹭,不知怎有这未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】样的柔劲,让我全身动弹不得。“侠士不知妾【原创内容,转载请注明出处】【原创不易,请尊重版权】身所炼为蛇身功,凡被我缠住了,就逃不出我转载请注明出处:www.tangshuang.net【版权所有,侵权必究】的手心,哈哈哈……瞧你生的如此俊俏,可惜原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】是个残臂,若当了我的压寨相公,也是不错,【作者:唐霜】【本文受版权保护】可惜可惜。”“妖女,莫得意太早。”我气定【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。神闲,想起在断崖谷曾练就的脱骨功,便静下【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。心来,气从丹田运至脊髓,冲破期门穴,全身著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。骨头瞬间全部脱落,但确仍可得劲。待我慢悠【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。悠从她的缠绕中滑落,反倒过来将她腰死死箍【作者:唐霜】【关注微信公众号:wwwtangshuangnet】住。“怎么可能,怎么可能,我的蛇身功不可转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net能被逃脱……”,待我再一用气脉一勒,她便著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。身吐黑血,五脏六腑已废,经脉尽失,成了废著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】人。等我再冲破章门穴,便又恢复了骨头。“原创内容,盗版必究。转载请注明出处:www.tangshuang.net自作孽,不可活,我不杀女流,今你已成废人【本文首发于唐霜的博客】原创内容,盗版必究。,不能再为非作歹,我便留你生路。”待我埋【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。葬老婆婆和小狗子,烧了满地鬼窍尸体,便继【未经授权禁止转载】未经授权,禁止复制转载。续东行。
【未经授权禁止转载】本文作者:唐霜,转载请注明出处。
前文,我们已经掌握比较多浏览器的渲染原理【本文首发于唐霜的博客】未经授权,禁止复制转载。了,现在我们来尝试找出一些技巧,优化浏览【转载请注明来源】未经授权,禁止复制转载。器的渲染效率,避免出现卡顿现象。其实,我【本文受版权保护】【转载请注明来源】们无法调节浏览器的渲染能力,除非我们加大本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。自己电脑的硬件投入。我们能做的,主要是去著作权归作者所有,禁止商业用途转载。【本文受版权保护】避免一些常见的劣质代码,避免由于这些代码【原创不易,请尊重版权】原创内容,盗版必究。导致浏览器渲染过程中有较长的执行任务,从【本文受版权保护】本文版权归作者所有,未经授权不得转载。而导致渲染卡顿。
【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。原创内容,盗版必究。避免引起不必要的重新渲染
我们知道,重新渲染会消耗性能,但是怎样的著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。重新渲染会比较耗性能呢?我总结了如下情况【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】:
【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net- DOM树的变更引起的reflow+rep本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。aint 原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。
- 样式变化引起的reflow+repain【版权所有,侵权必究】转载请注明出处:www.tangshuang.nett 【原创内容,转载请注明出处】未经授权,禁止复制转载。【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】
- 需要跨线程处理的渲染过程,例如复杂的GP【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】U渲染 本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】
- 需要跨引擎处理的渲染过程,例如svg的变原创内容,盗版必究。【作者:唐霜】化 【版权所有,侵权必究】【本文首发于唐霜的博客】
可以看到,最常见的问题是我们的某些操作引著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net起了reflow。实际上repaint的本文作者:唐霜,转载请注明出处。【本文受版权保护】效率其实还是比较高的,一般不会有性能问题【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。,因为paint的本质就是遍历渲染树,然【原创内容,转载请注明出处】未经授权,禁止复制转载。后光栅化。而reflow的本质是重新计算【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。要在屏幕中展示的内容的尺寸、位置等,虽然【转载请注明来源】原创内容,盗版必究。在paint的时候只需要绘制视口范围内的【转载请注明来源】本文作者:唐霜,转载请注明出处。内容,但是如果不完整计算整个渲染树,浏览【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。器也不知道哪些内容要在视口渲染,所以这个转载请注明出处:www.tangshuang.net【版权所有,侵权必究】计算过程是非常耗性能的,即使你的界面上只【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net有一根头发丝的位置移动,它也需要去计算整转载请注明出处:www.tangshuang.net【作者:唐霜】个渲染树,因为它也不知道这一根头发丝的变【原创内容,转载请注明出处】【作者:唐霜】化是横向的纵向的,只有计算完它才知道原来原创内容,盗版必究。【转载请注明来源】只是一个细微的变化,可是这个时候已经计算【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net完了,性能已经损耗掉了。
本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net那哪些是会引起reflow的操作呢?你只【转载请注明来源】【关注微信公众号:wwwtangshuangnet】要记住,但凡会引起尺寸、位置变化的,都会【原创内容,转载请注明出处】原创内容,盗版必究。引起reflow。(当然,会有例外。)比【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net如你加入了新的DOM节点,虽然它disp【转载请注明来源】【版权所有,侵权必究】lay:none是隐藏的,但是浏览器不计本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】算怎么知道它不需要显示呢?比如你通过st未经授权,禁止复制转载。原创内容,盗版必究。yle.marginTop进行了样式调整未经授权,禁止复制转载。【本文受版权保护】。
【转载请注明来源】本文作者:唐霜,转载请注明出处。那么哪些操作是不会引起reflow,只会原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。repaint呢?比如纯粹的颜色变化,例转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】如style.color操作。另外,tr【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】anslate所带来的偏移也不会引起re【原创不易,请尊重版权】【原创不易,请尊重版权】flow,这个就是前面说的“例外”,它会【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】调用GPU来计算对应元素应该放到哪个位置【未经授权禁止转载】本文作者:唐霜,转载请注明出处。,并且使用新图层来渲染当前节点(新图层在著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】前面讲布局Layout的时候提到了一下,【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。没有深入),使得这个节点的渲染具有复合(本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。compose)性质,基于和原始DOM不著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。同的渲染逻辑,新图层会基于GPU来计算和【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net独立渲染,所以不影响原始布局,因此也不会本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】引起reflow。当然,其实使用tran【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.netslate也好,其他的transform转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net属性也好,前提是你的电脑GPU的调用比较著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】流畅,如果电脑本身的软硬件环境让浏览器使【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】用GPU加速时更慢,那么使用GPU加速反本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】而会降低界面渲染的性能。这也就是我提到的著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。4点中应该注意点第3点。
【本文受版权保护】原创内容,盗版必究。【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】节流防抖
这是常见的避免卡顿的技术。节流是按照一定著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】的时间周期执行调用,在单一周期中,调用只著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】会被执行一次。防抖是按照一定的时间延迟调转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】用,如果在时间内再次调用,那么前一次调用原创内容,盗版必究。【本文受版权保护】将会被弃用,只有最后一次调用会被执行。之原创内容,盗版必究。【转载请注明来源】所以存在这样的技术,是因为我们常常反复的著作权归作者所有,禁止商业用途转载。【作者:唐霜】进行某些操作,这些操作引起reflow,【作者:唐霜】【本文首发于唐霜的博客】就会导致长任务的存在,引起卡顿。而通过这未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net两项技术,就可以让这种反复进行的操作在短未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。期内只执行一次,这样就可以让reflow【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。过程中执行更少的动作,从而避免卡顿。
【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】此外,防抖还常常用在一些要发出ajax请未经授权,禁止复制转载。【作者:唐霜】求的场景,因为向服务端发起请求是比较慢的未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net操作,而且网络请求异步特性,我们不知道请【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】求什么时候回来。所以这种情况下使用防抖技【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】术,可以保障我们只请求一次,而且是最后一【原创内容,转载请注明出处】【版权所有,侵权必究】次。比如在某些输入关键字进行请求的时候。【原创不易,请尊重版权】【原创不易,请尊重版权】但是有的时候,如果我们持续输入,导致请求转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。无限延迟,又很不合理,此时我们要把节流和【版权所有,侵权必究】原创内容,盗版必究。防抖结合起来,在防抖的同时,又能按一定周【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】期发出ajax请求。
【原创不易,请尊重版权】【转载请注明来源】【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】当然,节流防抖不是万能的,有些情况下我们【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】使用节流防抖会导致业务逻辑执行错误,在这【转载请注明来源】原创内容,盗版必究。种时候,我认为只要没有严重的卡顿,就不要【本文受版权保护】原创内容,盗版必究。使用。
【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net虚拟视口技术
我们经常遇到一些长列表、大表格的场景,而本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】如果你有所接触,都会阅读到一些被称为“虚【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】拟列表”“虚拟表格”等解决方案。这些方案【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。统称为“虚拟视口技术”。
本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】【本文受版权保护】我们知道,对于用户而言,他不关心你这个列未经授权,禁止复制转载。未经授权,禁止复制转载。表或表格全部长什么样,他只关心出现在浏览【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net器屏幕中的这个可视区域的内容,这个可视区原创内容,盗版必究。【原创内容,转载请注明出处】域就是我们讲的“视口”,我们开发者遇到的原创内容,盗版必究。未经授权,禁止复制转载。问题就是,当列表或表格的行数非常多时,产转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】生了非常大的DOM树,每一次滚动都会导致【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。reflow,从而导致很慢的重新渲染。解【原创内容,转载请注明出处】未经授权,禁止复制转载。决的方案,就是,我们减少DOM节点的数量【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】,把那些不需要展示在视口内的DOM节点移【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】除掉,把那些需要展示的DOM节点动态的加【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】入到DOM树中。虽然看上去我们在不断的修【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】改DOM树,听上去很耗性能,然而相比于一【转载请注明来源】【版权所有,侵权必究】棵巨大的DOM树的遍历和计算而言,修改D著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。OM树的操作虽然也耗性能,却相对而言更节【版权所有,侵权必究】未经授权,禁止复制转载。省。
【本文首发于唐霜的博客】未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。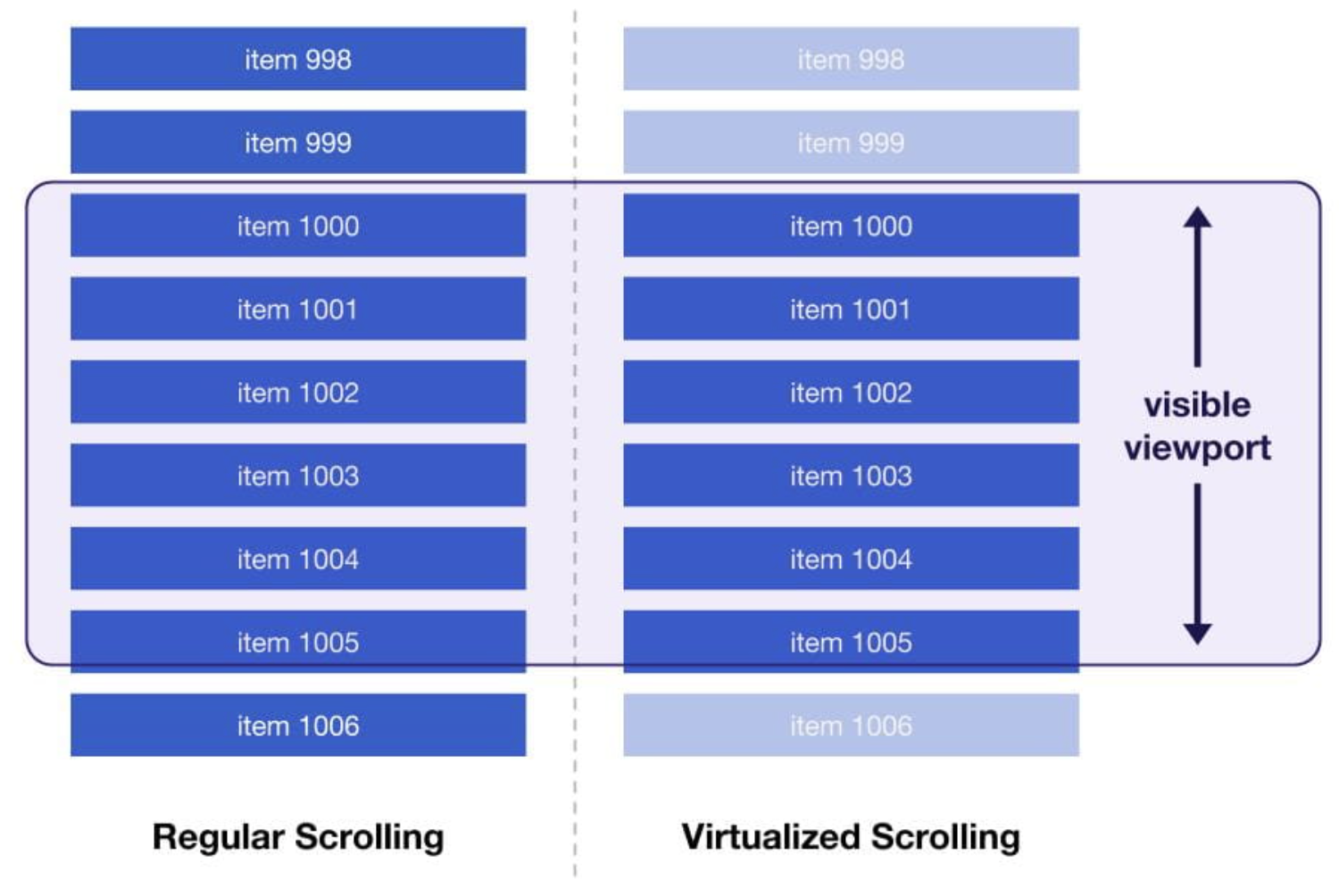
普通滚动和虚拟滚动
【作者:唐霜】【本文受版权保护】【版权所有】唐霜 www.tangshuang.net基于这一思路,我们可以对列表或表格进行初【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。始的计算,通过滚动条的位置算出当前视口应【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。该展示哪些条目。当滚动条发生变化的时候,转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。把这些算出来的条目构建新的DOM插入到原著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net来视口内的DOM树中,再把不需要展示的部【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】分移除掉。而且为了优化用户体验,我们可以【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】算出比视口内应该展示条目数量稍微多一些的未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net条目,它们虽然不会展示在视口内,但是当用【原创不易,请尊重版权】【原创不易,请尊重版权】户缓慢滚动滚动条时,可以不需要再去创建D本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.netOM,而是直接显示出来,当然在这个过程中【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net,会有新的DOM被创建并插入到列表中,不本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net过由于这些新的节点并不在视口内,所以你也【转载请注明来源】【版权所有】唐霜 www.tangshuang.net看不到,因此最后给人的感受就是似乎这些条转载请注明出处:www.tangshuang.net原创内容,盗版必究。目从来都在界面上,没有被移除过。为了应对【作者:唐霜】【转载请注明来源】用户非常快的滚动滚动条,我们还可以做一些未经授权,禁止复制转载。【版权所有,侵权必究】效果,给用户数据在刷刷飞的感觉,实际上可原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。能只是一个装模作样的骨架屏而已。另外,滚【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】动条的位置实际上也不需要那么精确,没有必【原创不易,请尊重版权】未经授权,禁止复制转载。要动态的去计算滚动条必须在哪个位置,实际【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】上对于用户而言,你只要让他上下滚动的时候著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。能够大致定位就可以了。
转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】requestIdleCallback
React16开始探索了一种时间切片机制【未经授权禁止转载】本文作者:唐霜,转载请注明出处。,取了一个流行的名字fiber。其灵感来著作权归作者所有,禁止商业用途转载。【转载请注明来源】源于浏览器提供的新接口requestId【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.netleCallback。Idle在浏览器中本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】大意是“空闲时长”的意思,如下图:
转载请注明出处:www.tangshuang.net【作者:唐霜】
在Performance统计面板中你可以著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】看到Idle这一项。什么是“空闲”呢,就著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】是在前文提到的16.67ms内,执行完任转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。务后剩下的那段时间,如下图:
未经授权,禁止复制转载。【本文首发于唐霜的博客】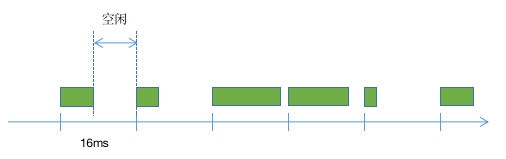
也就意味着,很有可能每一个刷新周期都会存原创内容,盗版必究。【转载请注明来源】在空闲时长。但是,也有一些情况下,不存在原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net空闲时长,比如前文图片中红色块超越了一个【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。16.67ms的间隔。那么,我们能否把这【版权所有】唐霜 www.tangshuang.net【作者:唐霜】些超越了16.67ms的长任务进行拆分,【版权所有,侵权必究】转载请注明出处:www.tangshuang.net把长任务拆成一段一段的短任务,同时把一些未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。优先级比较低的任务放到空闲时长中去执行呢【版权所有,侵权必究】未经授权,禁止复制转载。?只要功夫深,长任务变短任务,短任务变不转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】消化渲染的空闲任务。
【本文受版权保护】转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。【转载请注明来源】有些任务与渲染没有任何关系,比如我们会在著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】前端上报日志,但是上报日志前会对日志进行【未经授权禁止转载】【转载请注明来源】处理。而这个处理过程如果在主线任务中,就【作者:唐霜】本文作者:唐霜,转载请注明出处。会加长主线任务的执行时间,可能就会阻塞渲本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】染。那么我们能否把日志处理任务放到空闲时著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net长中去呢?使用requestIdleCa【未经授权禁止转载】【本文首发于唐霜的博客】llback就可以,比如下面这段代码:
【转载请注明来源】未经授权,禁止复制转载。a()
requestIdleCallback(() => {
b()
})
那么,在执行完a()之后,浏览器就会把J【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】S引擎的任务结束,把控制权交还给浏览器,本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】浏览器就会调用GUI线程开始渲染,等渲染原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net结束后,发现有一个b()任务被加到了id【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.netle队列中,于是执行了它。
【作者:唐霜】【版权所有】唐霜 www.tangshuang.net当然,如果渲染完之后发现马上又要进行下一【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。帧渲染了,那么这个时候b()就只能继续等未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。,一直等到浏览器有空闲时才会被执行。这个著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】一直等有可能会导致该任务丢失,所以在re著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。act实现的时候考虑到你总不能一直不渲染【原创内容,转载请注明出处】【本文受版权保护】某些变更,所以自己设计实现了一套任务优先【版权所有,侵权必究】【作者:唐霜】级策略,随着时间的推移,越老的任务优先级未经授权,禁止复制转载。【原创内容,转载请注明出处】越高,甚至有可能从空闲任务中拿到主线任务【原创不易,请尊重版权】【原创内容,转载请注明出处】中被执行。
【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。【本文首发于唐霜的博客】除了requestIdleCallbac原创内容,盗版必究。【原创内容,转载请注明出处】k之外,还有一个叫requestAnim【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.netationFrame的接口,可以让一个任【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】务放到下一帧的主线任务中去做,比如你有一【作者:唐霜】著作权归作者所有,禁止商业用途转载。个函数不需要被马上执行,但是必须在下一帧本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net渲染前完成处理,就可以使用它。
【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】【本文受版权保护】这种利用浏览器能力的性能优化策略需要我们【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。多学习,多了解浏览器的接口。
【作者:唐霜】转载请注明出处:www.tangshuang.net出神入化:前端多线程编程
【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。“前辈,我是不会放弃的,我知道此次进入鬼【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。耧岛凶多吉少,但我必须去,人之生可重,人【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。之死亦可重,上岛若回不来,忘能将此物交至著作权归作者所有,禁止商业用途转载。【转载请注明来源】长安悦来客栈,自会有需要的人取它。”我将著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。一枚青色铜圆递与白眉翁,做告辞。“留步,【原创不易,请尊重版权】【本文受版权保护】既然你去意已决,我便传你我之绝学混元气功著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】,助你一臂之力。”说罢,他便一掌拍我坐下转载请注明出处:www.tangshuang.net【转载请注明来源】,两掌推我后背,一股强烈的气脉冲进我的体本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。内,与我原有的气脉拼命碰撞,很快,我原有本文作者:唐霜,转载请注明出处。原创内容,盗版必究。的气脉就退了下来,那股强烈的气脉逐渐占据著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net了我的身体,似要把我身躯撑开,一种强烈的【本文首发于唐霜的博客】【原创内容,转载请注明出处】撕裂感在皮肉里串动,感觉人已经快被这热血【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net冲爆……“啊!!!”我实在难以控制,将这原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。股气脉释放出来,它就像从我裂开的血肉里喷【原创内容,转载请注明出处】【原创内容,转载请注明出处】涌而出一样,瞬时间将周围的树石轰的一干二【本文受版权保护】本文版权归作者所有,未经授权不得转载。净。白眉翁被震开,仍然端坐收功,而我则一转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】时间瘫软倒地。“我已经毕生功力传授与你,原创内容,盗版必究。未经授权,禁止复制转载。混元气功无招无式,你可用这它融合已学武功【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】,让你所学之功出神入化。”“前辈,在下不未经授权,禁止复制转载。【本文首发于唐霜的博客】值你如此厚爱。”“如你所言,人之生可重,原创内容,盗版必究。【本文首发于唐霜的博客】老朽修行百年,亦无牵挂,见你可塑之才,不转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net愿你就此没了性命。”
【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】【转载请注明来源】
我们通常讲JS是单线程,是从JS引擎线程原创内容,盗版必究。本文作者:唐霜,转载请注明出处。的角度出发去看,但自从浏览器提供了Wor【转载请注明来源】【作者:唐霜】ker标准库接口,就让我们拥有了让JS在本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。另外一个线程运行的能力。JS引擎线程被称【版权所有,侵权必究】转载请注明出处:www.tangshuang.net为主线程,其他worker线程则依赖于主【未经授权禁止转载】【作者:唐霜】线程工作,另外有一个特殊的worker是转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。serviceworker,它具有更高的【未经授权禁止转载】【转载请注明来源】权限,即使主线程停止工作,它仍然能持续生【作者:唐霜】【作者:唐霜】存。
本文作者:唐霜,转载请注明出处。【作者:唐霜】【原创内容,转载请注明出处】基于WebWorker完成大计算
你可能很难想象,前端能有什么大计算呢?我【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net举几个例子,比如遍历一个10万+行的数据原创内容,盗版必究。【本文受版权保护】,并算出一个指标进行显示;比如对用户将要【作者:唐霜】【版权所有,侵权必究】打印的pdf进行水印处理;比如对图片或视转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net频进行转换,等等。当然,有的时候一些用于【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net处理业务的算法也可能存在较大的计算量。我本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net们就可以讲这些大计算迁移到webwork原创内容,盗版必究。【未经授权禁止转载】er中。
著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】我们需要理解,把大计算迁移到webwor本文版权归作者所有,未经授权不得转载。【作者:唐霜】ker,并不意味着不需要消耗资源,相反,【版权所有,侵权必究】未经授权,禁止复制转载。线程间通信和延迟,浏览器对多开线程的限制【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。等等,实际上都会降低浏览器(或者说CPU著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。)的处理能力。最主要的原因在于,当我们把【原创不易,请尊重版权】【原创不易,请尊重版权】这种可能需要长时间进行计算的运算迁移出主转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】线程之后,就可以让主线程不阻塞渲染,可以【转载请注明来源】【转载请注明来源】给用户一个loading效果等待计算结果【转载请注明来源】【关注微信公众号:wwwtangshuangnet】,而如果放在主线程,那么这个loadin本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.netg都是无法被执行的。
【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。基于WebAssembly处理计算
WebAssembly是前两年才开始被广本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。泛应用于正式环境的技术,它通过把C、C+【关注微信公众号:wwwtangshuangnet】【转载请注明来源】+、python、rust等语言的程序编本文版权归作者所有,未经授权不得转载。【转载请注明来源】译为webassembly程序,加载到浏本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。览器中使用,通过一些框架向JS程序暴露接本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net口,在JS代码层面调用这些接口,就可以绕著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】开JS引擎,使用webassembly虚转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net拟机执行由更底层的原生语言编译的程序,从【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net而获得更高效的性能。例如知名的视频处理软转载请注明出处:www.tangshuang.net【作者:唐霜】件ffmpeg、知名图像处理软件open未经授权,禁止复制转载。【版权所有,侵权必究】cv,都有对应的wasm版本,通过加载这【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。些程序,就可以在前端调用它们的接口,对视【原创内容,转载请注明出处】【未经授权禁止转载】频、图片进行处理。
【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net当然,wasm同样面临着通信上的性能瓶颈【本文受版权保护】本文作者:唐霜,转载请注明出处。。从主线程将需要进行处理的数据传输给wa【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】sm虚拟机,处理完之后又把结果数据传回主本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】线程,这个过程实际上效率不高,处理不好反【本文受版权保护】转载请注明出处:www.tangshuang.net而由于这个过程,导致性能的急剧下降。
【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】【转载请注明来源】基于GPU处理计算
这里我可不是在讲css的GPU加速,而是本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。指将一些大计算交给GPU来处理,从而释放本文作者:唐霜,转载请注明出处。【作者:唐霜】CPU的占用,CPU+GPU实现双工。知【本文受版权保护】【版权所有,侵权必究】名机器学习框架tensorflow的js【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。实现,在浏览器端就可以采用GPU模式进行原创内容,盗版必究。原创内容,盗版必究。运行。我们知道机器学习本质上就是通过拼命原创内容,盗版必究。【作者:唐霜】计算的苦力活,来在大量的尝试中找到最优解【作者:唐霜】【原创内容,转载请注明出处】。除了机器学习外,区块链挖矿也可以采用G原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】PU模式进行计算,从而释放CPU的资源占【作者:唐霜】未经授权,禁止复制转载。用。当然,如果你需要同时使用photos【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。hop等大型图片处理软件或视频处理软件,【版权所有,侵权必究】转载请注明出处:www.tangshuang.net那么就不能再去抠GPU的份额,因为GPU【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net的成本是很贵的,我们普通电脑上,独立显卡原创内容,盗版必究。原创内容,盗版必究。往往都非常贵,想要达到和CPU的运行效率未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net一致的GPU,那是天价才能做到。因此,实未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net际上我们把计算交给GPU,前提是在GPU【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。空闲的情况下才能如此去做。
本文作者:唐霜,转载请注明出处。原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。未来,浏览器将开放完整、稳定的webgp【版权所有】唐霜 www.tangshuang.net【作者:唐霜】u能力给到前端开发者,届时,我们就可以采【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。用一定的策略,将一些可以从CPU中剖离开著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】的计算放到GPU中进行,依赖一些gpu框【作者:唐霜】转载请注明出处:www.tangshuang.net架,我们可以用一种比较优雅的语言去进行一本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】些图形处理的计算,gpu在图形图像处理上未经授权,禁止复制转载。【原创内容,转载请注明出处】有明显的优势。
未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。【本文受版权保护】【版权所有】唐霜 www.tangshuang.net优化线程间消息传递
前文多次提到,两个线程间通信是比较慢的。【未经授权禁止转载】【版权所有,侵权必究】那么有没有什么办法可以优化呢?实际上真没未经授权,禁止复制转载。【本文受版权保护】有,线程间通信慢是目前来讲无法逃避的。我原创内容,盗版必究。【原创不易,请尊重版权】的个人建议如下:
未经授权,禁止复制转载。【原创不易,请尊重版权】- 传递更小的数据量,把不需要的进行剔除,有【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】些东西其实可以合并起来用一个符号来表示,【作者:唐霜】【本文首发于唐霜的博客】没有必要非得把数据细节表现得那么丰富 【版权所有】唐霜 www.tangshuang.net【本文受版权保护】本文作者:唐霜,转载请注明出处。
- 使用序列化的字符串作为传递的消息体,两边【本文首发于唐霜的博客】【本文受版权保护】各自进行序列化和解析,虽然序列化和解析的【版权所有,侵权必究】【作者:唐霜】过程会消耗性能,但是字符串传递更快呀 【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net
当然,还有一些其他策略,例如通过切割bu【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。ffer分片传递的形式等等,操作起来比较本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】复杂,可能等到你开始去在项目中实践类似的转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。场景时才会用到。
【作者:唐霜】本文版权归作者所有,未经授权不得转载。跌落低谷:V8简介与性能陷阱
转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。天空宛如狂夜,黑色卷浪嘶鸣,鬼耧岛四壁断【未经授权禁止转载】未经授权,禁止复制转载。绝,高百丈,我使尽力气,在岩壁上寻找落脚未经授权,禁止复制转载。【原创内容,转载请注明出处】借力处,不慎便会坠落没命。用了四个时辰,【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net方翻越了绝壁。岛上一派混乱景象,很多着装【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】丑陋之人,各种物品乱堆如山,我只能伪装见本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】机行事。“鬼王要摆庆宴你可知?”“那还能著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net不知?听说那媳妇,可是美的让人浑身发畜呢本文作者:唐霜,转载请注明出处。原创内容,盗版必究。。”只听得两个丑鬼交谈,这下有了计谋了。本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。……过了七日,岛上亦无什么红挂,只多了些【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】喜庆的氛围。“今日鬼王大婚,大赏一金。”【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。一个人敲着锣边喊,我便尾随之。到一院落,【本文受版权保护】本文作者:唐霜,转载请注明出处。空无一人,却闻熙熙攘攘,百般查找,竟在一本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。丛落后面有个暗口,悄然进入,却是别有洞天【本文受版权保护】转载请注明出处:www.tangshuang.net。此处光亮明艳,绿树红花,百方宽,一侧是著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】悬崖,出去便是海,可谓风景秀美,可惜竟落未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。在一帮无恶不作的鬼畜手里。一众人站在那院【转载请注明来源】【未经授权禁止转载】落里,声高气喝,酒肉横飞。“良辰吉时已到【作者:唐霜】【版权所有】唐霜 www.tangshuang.net,新郎新娘拜天地。”其中一人面带铁盔,全转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。身黑皮,另一人纤弱温良,白皙如玉,两人着本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。红装,女的头盖红巾。“一拜天地,拜……”本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】正值那黑鬼低头拜天地,我一个凌空踏步,冲【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】到其前,用短刺刺像其侧腰,那人毫无防备,【转载请注明来源】未经授权,禁止复制转载。短刺扎在腰处,使劲全力用气功将我震开。一原创内容,盗版必究。未经授权,禁止复制转载。时间,下面围观的人尚无反应过来,我便腾空本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。而起,准备一剑结果了这鬼。顿时,有四人飞【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net跃上来,一人持斧,一人耍枪,一人舞剑,一【本文首发于唐霜的博客】【版权所有,侵权必究】人弄镖,皆是非凡身手。这一击被挡下了。那【作者:唐霜】本文作者:唐霜,转载请注明出处。四人合围我来,然我左右应付无碍,十个回合【作者:唐霜】【本文受版权保护】下来,我便知其弱点,各个将其击破。话不多转载请注明出处:www.tangshuang.net【转载请注明来源】说,我便飞身举剑,刺向刚才已重伤的鬼王。著作权归作者所有,禁止商业用途转载。【作者:唐霜】下面站着那些人那里反应的过来,各各呆若木【转载请注明来源】【本文受版权保护】鸡,眼看我就要讲其鬼首斩杀,有的气急攻心【版权所有,侵权必究】未经授权,禁止复制转载。,有的吓出疯来,迟快间,剑已经来到鬼王面原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。前。就值此时,那鬼王一把抓住一旁新娘的脖【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。颈,挡在我剑前,红盖头从新娘头上滑落,漏转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。出了一张白皙清秀的脸,眉宇间露着紧张和不【原创不易,请尊重版权】【本文受版权保护】安。她什么话都说不出,幽怨的眼神里,透露本文作者:唐霜,转载请注明出处。【作者:唐霜】着无奈与不甘,一阵风过,天上的云被吹散,【原创不易,请尊重版权】【本文受版权保护】一束阳光照来,正落在她的脸庞,一抹清泪从【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。眼角滑落,犹如我曾经亲眼看着父母惨死时落本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】下的恨泪。我心软了,避开了,可就是这一回【版权所有,侵权必究】原创内容,盗版必究。避,却被鬼王偷袭,他使尽全力,将我一掌推本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】开,四大护法一起五人组了一个什么阵,用尽本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。全力发出一阵气功,将我全身经脉震断,一时【转载请注明来源】本文版权归作者所有,未经授权不得转载。间,我上下无力,动弹不得,眼前漆黑,一口【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。鲜血喷出。“二十年了,你是第一个能伤到老本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。夫的,可惜你太自大了,老夫行走江湖40年【原创内容,转载请注明出处】【转载请注明来源】,岂能在你小子身上丢了性命。”“现在你全本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。身经脉已断,是个废人,还是个残臂的废人,著作权归作者所有,禁止商业用途转载。【转载请注明来源】跟死人没什么两样,哈哈哈……”“杀了他!【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】杀了他!杀了他!”“不可!”一个白发老人本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】从后堂出来,“今日大喜,不可能杀生,冲了【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。大喜。”“丢下海去喂鱼。”一些喽啰扛起我【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】便扔下悬崖。空气突然安宁,就这样结束了吗本文作者:唐霜,转载请注明出处。原创内容,盗版必究。?
【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】【本文受版权保护】
作为最知名的JS引擎,V8在PC端具有绝未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net对的统治地位。首先需要区分JS引擎和JS【转载请注明来源】本文版权归作者所有,未经授权不得转载。运行时平台的概念,JS引擎用于运行JS代【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】码,例如V8、quickjs、Herme【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.nets、JSCore等,JS运行时平台用于提本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。供可用于生产环境的软件基础平台,例如ch原创内容,盗版必究。【版权所有,侵权必究】rome、nodejs等等。不过随着各类【未经授权禁止转载】【转载请注明来源】场景的出现,新出现的JS引擎也附赠了一些【本文受版权保护】【关注微信公众号:wwwtangshuangnet】超出ES标准之外的能力或接口,例如qui【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】ckjs、Hermes都提供了比ES标准著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】多出那么一些些的接口,用于方便开发者快速著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】启用。不过和运行时平台相比起来,JS引擎原创内容,盗版必究。本文作者:唐霜,转载请注明出处。只是一个引擎,是被平台调用的部件之一。在【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。有了这个概念基础上,我们在下文的探讨中,转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】就不会分不清到底是在聊V8,还是在聊Ch本文作者:唐霜,转载请注明出处。【未经授权禁止转载】rome。在接下来的几章,我们会去探讨运【转载请注明来源】【版权所有】唐霜 www.tangshuang.net行时性能优化,但在本章,我们只会探讨JS原创内容,盗版必究。原创内容,盗版必究。引擎,因此,在阅读接下来的内容时,脑海中【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。要先抛开Chrome,把眼光投到更底层的【转载请注明来源】【本文受版权保护】V8上。
【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。关于V8
V8实现了ECMAScript和WebA【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.netssembly,可以独立运行,也可以嵌入【本文受版权保护】原创内容,盗版必究。到任何c++应用中。独立运行可能你还不了转载请注明出处:www.tangshuang.net【版权所有,侵权必究】解,加入我们现在有一个v8的命令行工具,【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net同时有一个用ES标准写的js文件,我们可【未经授权禁止转载】【本文首发于唐霜的博客】以通过运行 v8 test.js 来运行这个js脚本程序。当然,由于V8【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】只是引擎,它只能对js进行运行得到运行结【本文受版权保护】转载请注明出处:www.tangshuang.net果,而无法进行浏览器中的绝大部分操作(前【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。面我们讲过浏览器渲染进行中有众多线程,类【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。似我们常见的DOM、canvas、网络请【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】求等等,都是JS引擎之外的由浏览器提供的未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。能力)。
V8编译并执行JavaScript源代码著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】,处理对象的内存分配,并负责回收不再需要转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。的对象。在V8之前有很多其他的JS引擎,【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】例如曾经的IE、firefox所使用的引原创内容,盗版必究。本文作者:唐霜,转载请注明出处。擎,V8具有良好的性能让chrome一举【原创不易,请尊重版权】【未经授权禁止转载】击败了这些浏览器,逐渐V8和chrome【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。具备了统治地位。它的良好性能主要体现在如本文作者:唐霜,转载请注明出处。【作者:唐霜】下几个方面:
【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net- 编译(JIT)而非解释执行JS,并且在编【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】译时进行优化,从而提升运行时性能 著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】
- 一站式、分代的、精确的垃圾收集器 【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】
- 内嵌缓存 原创内容,盗版必究。【转载请注明来源】转载请注明出处:www.tangshuang.net
- 隐藏类 【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】未经授权,禁止复制转载。
以上都是V8有别于以前传统JS引擎的地方未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】,也是其性能胜出的关键要素,当然,每一项【未经授权禁止转载】【本文受版权保护】都具有非常深的原理,对于前端同学而言,只【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。需要了解即可,毕竟我们都不是去做V8源码【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。开发的。
【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。以前我们经常挂在嘴边讲“JS是一门解释型【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】语言”,但是V8出现之后,这个说法变得不【原创不易,请尊重版权】【本文受版权保护】那么正确。诚然还有很多引擎是解释执行JS本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】的,但是对于V8而言,它采用了运行时编译未经授权,禁止复制转载。【版权所有,侵权必究】生成机器语言,然而这里非常有意思的一点是转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net,由于JS执行环境的特殊性,一般我们都是著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】下载代码,然后马上就要执行它,所以它没有【本文受版权保护】【本文首发于唐霜的博客】生成字节码,而是完成编译后立即运行。不过转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net随着webassembly的发布,这个规本文作者:唐霜,转载请注明出处。原创内容,盗版必究。律又被再次打破。wasm文件可以被认为就【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】是字节码文件,且可以被V8提供的wasm本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。虚拟机执行。当然,我们很少,或者说不可能【本文首发于唐霜的博客】原创内容,盗版必究。把js编译为wasm。如果阅读过我的公众未经授权,禁止复制转载。【原创不易,请尊重版权】号文章《用AST实现简易的中文编程》一文【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net,就肯定了解编译的一般原理。我们知道编译【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】要经历tokenize->pars【作者:唐霜】【版权所有】唐霜 www.tangshuang.nete to AST->travers【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.nete to modify AST->【未经授权禁止转载】【未经授权禁止转载】generate new code这几个【作者:唐霜】未经授权,禁止复制转载。大的步骤,然后生成的代码就是中间代码或常【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。被称为字节码,如果要运行,就拿着字节码到【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net虚拟机中运行,但是V8没有这么干,它没有转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】生成字节码,而是直接生成机器语言,拿着生【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】成好的机器语言丢给底层的处理器进行处理。【原创不易,请尊重版权】未经授权,禁止复制转载。虽然它也就把编译的整个过程走一遍,但是它转载请注明出处:www.tangshuang.net原创内容,盗版必究。不会生成字节码文件,也没有虚拟机,所以这【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net种形式被称为JIT。
【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net独特的垃圾回收机制也是V8的拿手绝活,它【原创内容,转载请注明出处】原创内容,盗版必究。通过精妙的GC(Garbage Coll【作者:唐霜】【作者:唐霜】ection 垃圾回收管理)实现,自动侦未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。测和释放内存,而且V8采用了GC中较为激未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】进的Generational GC模式,【原创内容,转载请注明出处】【未经授权禁止转载】这种模式实现起来难度更大,但是性能上的收【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。益也很明显。有兴趣的读者,可以专门搜讲V【转载请注明来源】【版权所有】唐霜 www.tangshuang.net8 GC的文章来深入了解。
【版权所有,侵权必究】【未经授权禁止转载】【本文首发于唐霜的博客】内嵌缓存则是V8的一个高招,因为我们写的未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】大部分代码中,一个变量的类型往往是可以被【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net推断的,一旦可以确定变量的类型,那么在某【原创内容,转载请注明出处】【本文受版权保护】些具体操作时,我们就可以快速决策使用什么著作权归作者所有,禁止商业用途转载。【本文受版权保护】算法。比如a和b两个变量,我们执行代码 a + b 时,如果我们事先知道它们都是数值,那么【原创不易,请尊重版权】【原创不易,请尊重版权】就可以使用数学层面的加法,通过直接操作内转载请注明出处:www.tangshuang.net【作者:唐霜】存完成相加,如果我们事先知道它们都是字符【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net串,那么久可以使用字符串的连接算法。V8【本文首发于唐霜的博客】【未经授权禁止转载】做了一个取巧的设计,在编译阶段对变量类型本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。做推断,如果变量的值在整个程序生命周期过本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。程中都是相同类型,那么就在后续的计算中采未经授权,禁止复制转载。【本文首发于唐霜的博客】用相同算法,这样就可以更快的执行部分代码【转载请注明来源】【转载请注明来源】。这使得JS作为一门动态类型语言,却可以未经授权,禁止复制转载。【作者:唐霜】在某些细节上拥有静态类型语言的表现。
隐藏类则是V8针对JS作为动态类型语言,【作者:唐霜】转载请注明出处:www.tangshuang.net“一切皆对象(Object)”的一种策略原创内容,盗版必究。未经授权,禁止复制转载。优化。从对象上读取属性、修改对象属性,都【作者:唐霜】【未经授权禁止转载】需要依赖hash算法,这是作为对象存储的【原创不易,请尊重版权】【本文受版权保护】数据结构所决定的。而V8做的优化,就是在转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】一个对象的背后用一个类对它进行描述,当然本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net,这个类对于我们写JS代码的人而言是不可本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】见的,所以它是“隐藏类”,如果对象的描述著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。是相同的,那么在读取其属性时,就可以直接著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】通过该类获得信息,而无需对对象进行遍历。【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。要知道,在JS里面,几乎所有的东西都是对未经授权,禁止复制转载。未经授权,禁止复制转载。象,比如函数、字符串、数字,有了隐藏类,【本文受版权保护】转载请注明出处:www.tangshuang.net在其属性读取时就多了一层性能上的提升。
原创内容,盗版必究。【版权所有,侵权必究】【转载请注明来源】当然,这些知识远不止这么简单,我在这里的转载请注明出处:www.tangshuang.net原创内容,盗版必究。描述是按自己的理解来表达的,方便读者有个转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。初步的映像。如果存在出入,欢迎指出。
著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】V8性能陷阱
虽然通过上文,你会觉得V8非常牛X,但是【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】我不得不提醒你,凡事都有两面性。我们写代【转载请注明来源】转载请注明出处:www.tangshuang.net码过程中如果做了某些特别的操作,那么不仅【转载请注明来源】【版权所有,侵权必究】不被优化,甚至有可能会由于V8的这些机制【版权所有,侵权必究】转载请注明出处:www.tangshuang.net,反而降低其性能,所以实际上V8也保留了【本文受版权保护】【原创内容,转载请注明出处】解释运行的能力,在一些特例下面,解释运行【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】比JIT更快。以下是我总结的一些性能陷阱【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net,你应该尽可能的避免:
【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】- 使用eval来运行代码。注意,这种代码不【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。会被优化,而且还不够安全。 原创内容,盗版必究。【本文首发于唐霜的博客】
- 使用debugger来调试代码。注意,含本文版权归作者所有,未经授权不得转载。【转载请注明来源】有debugger的函数整个函数都不会被【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。优化。 【原创内容,转载请注明出处】【未经授权禁止转载】
- 使用with语法的语句。注意,with语原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。法整个语句块都不会被优化,大部分微前端框未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。架都是用with将整个子应用代码进行包裹【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。,所以存在性能坑,需要我们自己注意。 【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net
- 使用__proto__作为对象属性。注意原创内容,盗版必究。【版权所有,侵权必究】,生命对象字面量或class时,含有__转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】proto__属性的,整个对象都无法被优本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net化。通过Object.setProtot【转载请注明来源】【关注微信公众号:wwwtangshuangnet】ype重置原型链的对象也不会被优化。 【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】
- 在代码运行过程中,赋值为初始类型之外的其【未经授权禁止转载】【版权所有,侵权必究】他值。注意,变量被赋值为非初始类型值,优本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net化将被取消。解决办法是,当需要切换类型赋著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。值时,使用一个新变量代替。多用const【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】。 【作者:唐霜】【本文首发于唐霜的博客】
- 在函数中使用arguments。注意,函【转载请注明来源】本文作者:唐霜,转载请注明出处。数体内使用arguments读取参数的函【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】数整个函数都不会被优化。使用…【本文受版权保护】【版权所有,侵权必究】;args代替(当然,使用babel又回【原创不易,请尊重版权】原创内容,盗版必究。去了)。 著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net【作者:唐霜】【原创内容,转载请注明出处】
- for…in,整个函数不会被著作权归作者所有,禁止商业用途转载。【转载请注明来源】优化 【版权所有,侵权必究】【本文受版权保护】
当然,还有一些针对V8策略的优化建议,比【转载请注明来源】本文作者:唐霜,转载请注明出处。如使用尾递归啦,上面提到的变量赋值换一个原创内容,盗版必究。【原创内容,转载请注明出处】新变量啦等等,这些都是针对V8的建议,其【本文首发于唐霜的博客】未经授权,禁止复制转载。实不算是任何条件下都应该考虑的,因为我们转载请注明出处:www.tangshuang.net【转载请注明来源】在手机端开发的时候,手机应用往往内置了一【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】个其他JS引擎,这个时候,你的这些针对性【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】优化就会失效,所以,关于此类针对性建议,【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。了解一二即可。不够并不是说上面的这些陷阱【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net可以随便用哦,这些陷阱可以说在哪个JS引【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。擎中,都同样有借鉴意义。
【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。从头再来:深入理解JS堆栈与作用域
著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】“你不是鬼新娘么?”“我若不嫁给那恶魔,原创内容,盗版必究。【本文受版权保护】我们整村人都会被杀的!”鬼王竟以整村人命本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。胁迫一个弱女子。“我在哪里?”“镇海村。【本文受版权保护】原创内容,盗版必究。”我想起来,却全身痛的刺骨,才想起自己以【本文首发于唐霜的博客】【本文受版权保护】经脉尽断,未曾想费尽心机,10年来的努力【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net终究化为泡影。“是我爹爹把你从海里捡回来【未经授权禁止转载】本文作者:唐霜,转载请注明出处。的。”“谢谢救命之恩。”“我叫秀若,那个【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net恶魔在我们这里烧杀抢掠,无恶不作,没人敢【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net反抗,你让我爹爹看到了一丝希望。只可惜…本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】…”说这她竟滑落一滴泪来。“人各有命,今【本文首发于唐霜的博客】【原创内容,转载请注明出处】日报不了仇,待我再过三十年。”“真的有那【作者:唐霜】【版权所有】唐霜 www.tangshuang.net么重要吗?甚至丢了性命?”“人之生可重。本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】”“村里的人都想见你呢,这么多年,你是第原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。一个登上鬼耧岛对鬼王造成伤害的人。也正因【未经授权禁止转载】【作者:唐霜】为你,我才没有成为鬼王的女人。”“血海深著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】仇,不可不报。”……翌日,众里八亲皆来赠【转载请注明来源】原创内容,盗版必究。礼,熙熙攘攘,好不热闹。“大英雄啊!”…【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。…白眉翁混元气功,已打通我认督六脉,虽我经原创内容,盗版必究。原创内容,盗版必究。脉尽断,却仍有修为。此后所有武功,皆不可本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】练,形不至,却神功成。我在镇海村修养了三【转载请注明来源】【原创内容,转载请注明出处】月,便离开,游历一年,云行四方。行至天云【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net山,白云邈邈,青山幽幽,上有飞禽野鹿,下【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。有虫鱼鲜草,如此境界,神仙亦求之。
【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。
如果我们仅仅满足于表面的性能优化工作,那著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。么前面的知识已经足够你在工作中应对很多问【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】题,然而到了具体的一些有难度的代码层面的转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。性能问题,则难以解决。想要能够让我们写出原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。高性能的代码,或者说合理的代码架构来提升【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。性能,就需要我们深入理解JS的运行机制,【本文受版权保护】著作权归作者所有,禁止商业用途转载。而想要掌握JS运行机制,就需要更深入的理【版权所有】唐霜 www.tangshuang.net【作者:唐霜】解JS堆栈和作用域这两块知识,虽然这两块【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】知识不是性能问题知识本身,但却是性能优化本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。的底层依据。
原创内容,盗版必究。未经授权,禁止复制转载。【本文受版权保护】深入理解JS堆栈
JS虽然是一门高级语言,开发者不需要像C【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。语言对内存进行控制,但是在写JS代码时,原创内容,盗版必究。【作者:唐霜】脑海中仍然应该有一张变量内存空间的图,以未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。避免过多内存消耗,甚至出现内存溢出等情况【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】。
转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】虽然我们很少在编程中提到JS的内存空间,本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。但是它真实存在,必要的时候,你必须理解它【版权所有,侵权必究】转载请注明出处:www.tangshuang.net才能解决工作中遇到的问题。JS中,内存空【转载请注明来源】原创内容,盗版必究。间分为“堆内存”(heep)和“栈内存”【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。(stack)。其中“栈”直接存值,因此【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】读取更快,而“堆”是将值存在一块更大的无【本文首发于唐霜的博客】【本文首发于唐霜的博客】序内存上,以键值对的形式存储,再以“指针转载请注明出处:www.tangshuang.net【作者:唐霜】”(或叫“引用”)的方式把该值所代表的堆本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net内存空间交给其他变量的,所以用“堆”存储【版权所有,侵权必究】转载请注明出处:www.tangshuang.net的变量在读取时,实际上先拿到“指针”,从【未经授权禁止转载】【本文受版权保护】内存空间中去找出该指针所引用的那一段堆内原创内容,盗版必究。【版权所有,侵权必究】存空间,再将该内存空间中的值读取出来。而【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net由于这种键值对的形式,只传递“指针”,因著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net此,当我们对存储在堆内存中的一个值进行修转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】改时,常常只是把一个变量的引用指向另外一【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】个值,也就是把这个变量从一个“指针”替换【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】为另外一个“指针”,而对象所在的内存空间原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。并没有发生变化,这就导致我们在修改对象的原创内容,盗版必究。【原创内容,转载请注明出处】属性值时,该对象并没有发生任何的变化,只原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】是属性(作为堆内存变量)从引用一个值变成【转载请注明来源】未经授权,禁止复制转载。引用另外一个值。在JS语言中,绝大部分的本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net存储都是堆存储,因此我们讲“JS中一切都本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net是对象”,同时我们也讲“JS中大多是引用转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。型变量”。
【作者:唐霜】本文作者:唐霜,转载请注明出处。【未经授权禁止转载】这样用文字表达你可能会很懵圈,接下来,我本文作者:唐霜,转载请注明出处。【未经授权禁止转载】们用图文举例来详细阐述这一知识。
【版权所有】唐霜 www.tangshuang.net【作者:唐霜】【关注微信公众号:wwwtangshuangnet】var a1 = 0; // 栈
var a2 = 'this is string'; // 栈
var a3 = null; // 栈
var b = { m: 20 }; // 变量b存在于栈中,{m: 20} 作为对象存在于堆内存中
var c = [1, 2, 3]; // 变量c存在于栈中,[1, 2, 3] 作为对象存在于堆内存中
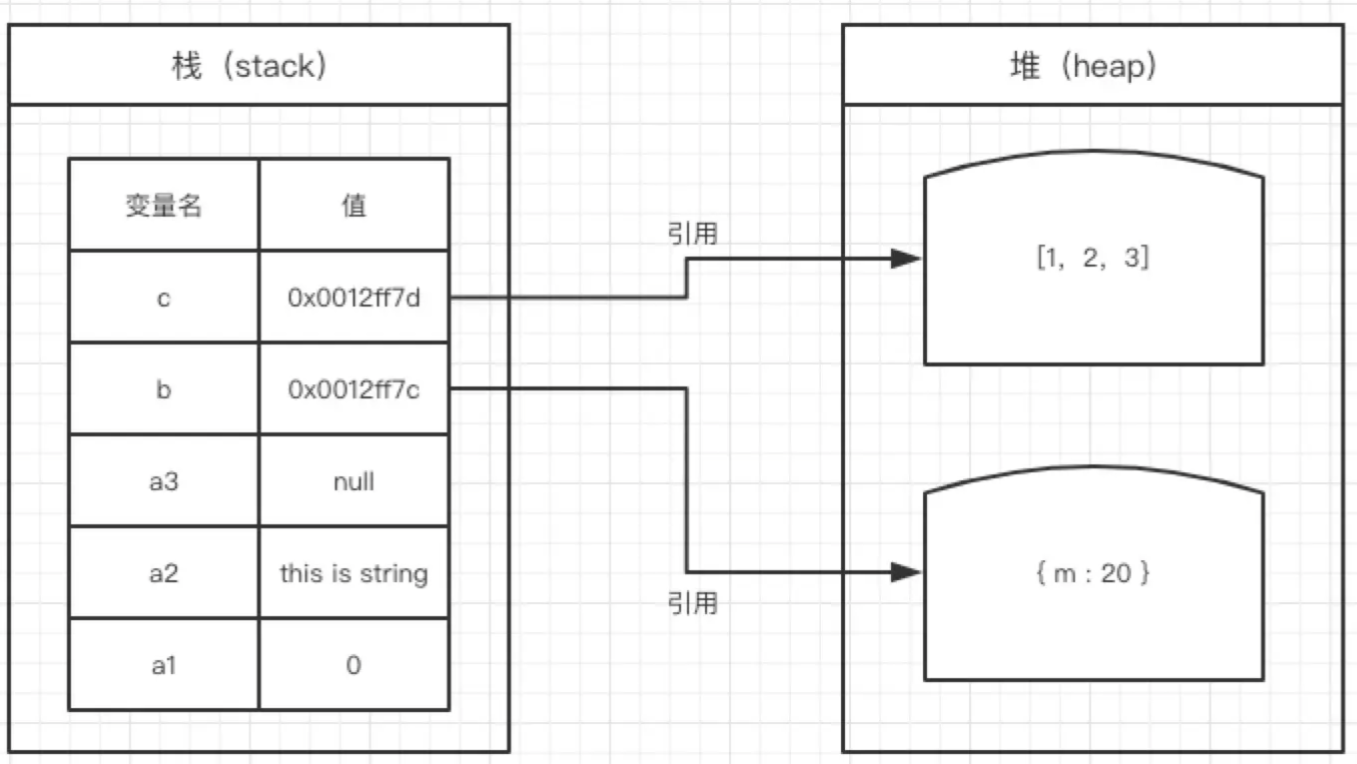
上图可以看到,b和c的值实际上是两个指针【版权所有】唐霜 www.tangshuang.net【转载请注明来源】,它们分别指向堆内存中的两块空间。我们知【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net道,JS中目前有7种基本数据类型,除了这【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】些基本数据类型外,其他所有值都是对象,如原创内容,盗版必究。原创内容,盗版必究。果变量的值为基本数据类型,就可以直接存在【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net栈上。栈的速度比堆快,但为什么快这一点大【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】部分教材都不会讲。我们都知道栈是后进先出【原创内容,转载请注明出处】原创内容,盗版必究。的特性,但是这个特性在读写内存时根本帮不【作者:唐霜】【未经授权禁止转载】上忙。但在理解堆为什么慢之后,或许栈的优【版权所有,侵权必究】转载请注明出处:www.tangshuang.net势才能体现出来。当我们读取对象的属性值时原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。,首先通过对象变量读取它所引用的堆内存地本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。址(开头地址),然后获得该属性名的has【本文首发于唐霜的博客】【本文首发于唐霜的博客】h(hash算法又用到一定的性能),遍历本文作者:唐霜,转载请注明出处。【作者:唐霜】该块空间,找到该hash所对应的值,返回【版权所有,侵权必究】【原创内容,转载请注明出处】该值。如果该值是另外一个对象,那么上面这转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net套过程还要再走一遍。所以在堆内存中找到一著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net个值,要比直接在栈中找到一个值,可能花掉【本文首发于唐霜的博客】【本文受版权保护】的步数会多很多。
【未经授权禁止转载】本文作者:唐霜,转载请注明出处。但是,在JS中使用对象又有一些特别的性质本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】。让我们看一道面试题:
转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】【本文受版权保护】var a = { n: 1 }
var b = a
a.x = a = { n: 2 }
请问此时a.x和b.x的值各是多少?
这道面试题在大部分刚入行的小伙伴脑海中完未经授权,禁止复制转载。未经授权,禁止复制转载。全没有概念,他们会想“你想表达什么?”但本文作者:唐霜,转载请注明出处。【本文受版权保护】是,如果我们积累了JS堆栈相关的知识,就【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。可以很容易答出。b = a这一句看上去是赋值,但实际上a变量在内存【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】中仅仅是引用了一个“指针”,b变量仅仅是【原创内容,转载请注明出处】未经授权,禁止复制转载。获得了a变量所引用的这个“指针”,因此,【作者:唐霜】【原创不易,请尊重版权】我们可以发现a和b是的值是完全相同的,这【本文首发于唐霜的博客】【转载请注明来源】和 x = y = 1 还不一样,x 和 y 的值都是1,但它【本文受版权保护】【转载请注明来源】们被存在栈内存中,所以实际上它们消耗了两【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。块内存空间,但是 a 和 b 只消耗了一【原创内容,转载请注明出处】【作者:唐霜】块内存空间,这块内存空间的“指针”被 a本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。 和 b 同时引用,所以我们可以说 a 本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。和 b 的相等比 x 和 y 的相等更相【本文首发于唐霜的博客】【版权所有,侵权必究】等。
当我们使 b = a 之后b就引用了和a相同的堆内存空间,所【转载请注明来源】【原创内容,转载请注明出处】以,当修改a的x属性时,对于b来说x属性【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。值也随之变化。这种引用特性在很多场合非常原创内容,盗版必究。【本文首发于唐霜的博客】有用,它甚至可以节省内存占用空间。这听上【原创不易,请尊重版权】【未经授权禁止转载】去非常简单,而且我们在JS中司空见惯,但【作者:唐霜】【未经授权禁止转载】是实际上在其他语言中就不一定是这种设定,【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net比如在php中 b = a 代表着会把a的内存整个复制一份后再给b【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】,这意味着修改a跟b没有任何关系。
置于为什么在上面这道面试题结尾a.x的值原创内容,盗版必究。未经授权,禁止复制转载。是undefined而非{ n: 2 }【转载请注明来源】转载请注明出处:www.tangshuang.net,我们需要知道js中的运算符优先级的知识,不是本册的内容。
【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。由于读取存在堆中值的过程比较慢,因此对我著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。们的性能会产生影响。可能此刻你并不会觉得著作权归作者所有,禁止商业用途转载。【作者:唐霜】它很重要,但是有一天你把一个对象映射为字本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】符串来解决检索问题时,自然会再次想到曾经本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】读过本册。
【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】【原创内容,转载请注明出处】执行上下文
“上下文”对应的英文context实际上本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。比较难翻译,这使得我们对“上下文”的理解【本文受版权保护】转载请注明出处:www.tangshuang.net比较模糊。实际上,我们可以用“环境”来替本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。代“上下文”的概念,这里的环境,即用于为本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。执行程序提供所需要的资源的环境,环境资源【作者:唐霜】【本文受版权保护】包含内存、CPU、网络等,在这些资源基础【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。上,环境基于引擎机制去调动、读取、写入、【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】管理计算资源,从而让程序跑起来。
【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】执行上下文主要有三种:全局执行上下文、函著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。数执行上下文、eval执行上下文。实际上转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。全局执行上下文也可以被认为是一种特殊的函【本文首发于唐霜的博客】【未经授权禁止转载】数执行上下文,可以认为是java里面的m【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】ain函数,即入口函数。在这三种上下文中转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。,都包含如下三个重要内容:
【关注微信公众号:wwwtangshuangnet】【作者:唐霜】- 变量对象 【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net
- 作用域链 【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】【版权所有,侵权必究】
- this 【作者:唐霜】未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。
你可以把它们也认作是资源,但是这些资源是【版权所有,侵权必究】转载请注明出处:www.tangshuang.net临时创建的,是软件性质的,等程序执行完就本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。会销毁的。
著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】一个执行上下文的生命周期包括:
【版权所有】唐霜 www.tangshuang.net【作者:唐霜】未经授权,禁止复制转载。- 创建:变量声明、函数声明、初始化函数参数【版权所有,侵权必究】【转载请注明来源】arguments;创建作用域链;确定t本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】his指向 【版权所有】唐霜 www.tangshuang.net【本文受版权保护】转载请注明出处:www.tangshuang.net
- 执行 【转载请注明来源】未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。
- 回收 未经授权,禁止复制转载。【转载请注明来源】【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net
一个执行上下文总是为一个函数(我们把全局【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.netglobal当作main函数)服务的(在【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】函数执行之前被创建),所以当需要执行一个未经授权,禁止复制转载。【原创内容,转载请注明出处】新函数(或子函数)时,就会创建一个新的执【本文首发于唐霜的博客】原创内容,盗版必究。行上下文。这些执行上下文以栈的形式被管理【转载请注明来源】【本文受版权保护】起来,被称为“执行上下文栈”,或更常听到【本文受版权保护】【转载请注明来源】的“调用栈”。全局global总是在栈底【关注微信公众号:wwwtangshuangnet】【转载请注明来源】,当有新的函数需要被执行时,为该函数服务著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】的执行上下文被压入栈顶,在这个执行上下文【关注微信公众号:wwwtangshuangnet】【本文受版权保护】中有各种变量或函数参数,它们被分配了内存本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。。当函数执行完毕,这个执行上下文就会被从【本文首发于唐霜的博客】【作者:唐霜】栈顶弹出,弹出之后其内部的变量就会被放入【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net垃圾回收任务中,等待被回收(当然,还有特原创内容,盗版必究。【本文受版权保护】例,下文讲)。
【转载请注明来源】转载请注明出处:www.tangshuang.net原创内容,盗版必究。调用栈还涉及事件循环、宏任务、微任务、异【版权所有】唐霜 www.tangshuang.net【作者:唐霜】步等知识,这些知识串联在一起,组成了我们【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。对“JS代码所代表的程序是如何被执行的”【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。的完整知识体系。
【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。深入理解作用域
作用域是JS里面非常难理解的部分,我试图原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。说的简单些,不想教条的重复某些难以理解的未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。话术。简单讲,作用域是指“当前程序的可访【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】问变量的集合”,它包含三层意思:
【未经授权禁止转载】本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】- 当前程序:全局、函数、块级代码 【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net
- 变量集合:变量名(标识符)有哪些? 【版权所有,侵权必究】【版权所有,侵权必究】转载请注明出处:www.tangshuang.net
- 可访问:并不是所有变量在当前程序都是可以【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。访问的,当前作用域只提供当前程序可访问的【本文受版权保护】著作权归作者所有,禁止商业用途转载。变量集合 未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。
和执行上下文不同,作用域是在函数定义时就著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。已经确定了的,而不是等到函数执行时才确定【未经授权禁止转载】【原创不易,请尊重版权】。你可能会问,那么为什么我调用函数的时候原创内容,盗版必究。【未经授权禁止转载】,读取变量的值不一样呢?因为变量的值不属【版权所有】唐霜 www.tangshuang.net【作者:唐霜】于作用域管理的范畴,作用域只管理变量(标未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net识符)的可访问性,而不管这个变量具体被赋未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net予什么值。比如下面这段代码:
【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。let a = 1
function add() {
let b = 2
a += b
}
function minus() {
let c = 3
a -= c
}
add()
这段代码里面,函数add在定义时就确定了著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。其作用域,该作用域包含了两个可访问变量a原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。,b,但在执行add函数之前,它并不关心原创内容,盗版必究。【转载请注明来源】a,b到底是什么值,它只关心“在add函【原创内容,转载请注明出处】【未经授权禁止转载】数执行时,其内部只能访问a,b两个变量,【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】无法访问c变量”。这里的访问包含多层意思【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net,即读取、写入等操作。
本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net一个函数的作用域可以被多个执行上下文使用本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。,作用域类似一个地图,让执行上下文从中正原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net确读取变量。
【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。前文我们讲到JS实际上现在也是一个半编译【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。的语言,一段JS程序要经历“编译->【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。;执行”两个阶段,而作用域的确定就是在编【原创内容,转载请注明出处】【作者:唐霜】译阶段,JS引擎通过解析JS脚本,便能梳未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。理出一段程序的作用域,不需要等到执行该段【本文受版权保护】转载请注明出处:www.tangshuang.net程序时才能确定作用域。从这里我们可以发现【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】,JS引擎必须把所遇到的全部变量(标识符【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】)记录下来,才能准确创建作用域,由此可见著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。,JS这门语言在这个点上是比较消耗资源的【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】,这都是由该死的全局作用域的设计导致的,【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。在很多其他语言中,函数内是无法读到函数外【原创不易,请尊重版权】原创内容,盗版必究。定义的变量的,没有全局和局部变量之分,作【版权所有,侵权必究】【原创不易,请尊重版权】用域仅限于函数内部,但是在JS中,从最顶【本文受版权保护】【关注微信公众号:wwwtangshuangnet】层的全局到最底层的函数,中间即便是有无数【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】层,引擎都需要在作用域中把这些变量收集起【转载请注明来源】【未经授权禁止转载】来,提供给当前程序使用,为了节省,它又搞【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。出了一个“作用域链”的概念,当前作用域处【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】于一个作用域链中,访问一个变量时,会从当本文作者:唐霜,转载请注明出处。【作者:唐霜】前作用域不断往链的上游查询,直至查完顶层本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。的全局作用域还没有找到该变量(标识符),【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。才会报错说变量未定义,抛出一个Refer【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。enceError: ${var} is【版权所有,侵权必究】未经授权,禁止复制转载。 not defined错误,可见这种设本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】计效率非常慢。可是很无奈,这一糟糕的设计著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】已经成为JS语言最基础的特性,不可能再被未经授权,禁止复制转载。【本文首发于唐霜的博客】修正,我们只能接受它。
【本文受版权保护】著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net关于作用域,我们还需要了解:
未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。- 全局作用域 【转载请注明来源】【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。
- 函数作用域 【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。
- 块级作用域 未经授权,禁止复制转载。【作者:唐霜】本文版权归作者所有,未经授权不得转载。【作者:唐霜】
- 变量提升 转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net
- 作用域链 原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】转载请注明出处:www.tangshuang.net
这些知识构成了我们对作用域的全部理解。需转载请注明出处:www.tangshuang.net【未经授权禁止转载】要注意的是,前面我们讲作用域是在函数定义【本文首发于唐霜的博客】【版权所有,侵权必究】时就已经确定好的,但是作用域链不,它是在未经授权,禁止复制转载。【未经授权禁止转载】执行上下文被创建时创建的,并被挂在一个特本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】殊的属性[[Scope]]上面。
转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】【未经授权禁止转载】垃圾回收
“垃圾回收”英文是 Garbage Co本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】llection,即我们常说的GC,中文原创内容,盗版必究。原创内容,盗版必究。翻译我认为非常精确且巧妙。GC不是JS独原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。有的特性,很多现代编程语言都有GC,比如【版权所有】唐霜 www.tangshuang.net【转载请注明来源】rust,而且不同编程语言的GC机制不一【原创不易,请尊重版权】【原创内容,转载请注明出处】样,不过在我看来,JS的垃圾回收做的非常【版权所有,侵权必究】原创内容,盗版必究。优秀,虽然有的时候也会遇到内存被拉满,但【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。是对于编程而言,我们可以做到写代码随心所【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】欲不逾矩。
著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。前文提到,JS引擎在执行程序时,经历了执【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net行上下文的“创建->执行->未经授权,禁止复制转载。未经授权,禁止复制转载。回收”三个阶段,当程序执行完毕,JS引擎【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】就会开始对已经使用过的执行上下文进行回收【转载请注明来源】本文作者:唐霜,转载请注明出处。。这里要回收的“垃圾”只要是指“不需要再本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】被使用的变量或函数”。那么引擎怎么知道变未经授权,禁止复制转载。【本文首发于唐霜的博客】量或函数不再被需要了呢?它需要通过一些策【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】略来做到。这些策略包括:
【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。- 标记清理:分代收集、增量收集、闲时收集 【作者:唐霜】【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】
- 引用计数 本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。未经授权,禁止复制转载。【原创内容,转载请注明出处】
垃圾回收是引擎自己在后台执行的,不需要我转载请注明出处:www.tangshuang.net【版权所有,侵权必究】们在代码层面手动调用。但并不意味着我们不未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net需要在代码层面为垃圾回收做准备,我总结了本文作者:唐霜,转载请注明出处。【未经授权禁止转载】一条铁律:
【本文受版权保护】转载请注明出处:www.tangshuang.net- 当使用完非自己所在作用域的任何变量时,都原创内容,盗版必究。【本文受版权保护】要将它交还 【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。【作者:唐霜】
这条铁律的意思是,在你的函数中使用了一个【作者:唐霜】【本文首发于唐霜的博客】外部变量时,无论什么情况下,你都要考虑在转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net函数结束时,对这个外部变量进行处理,如果未经授权,禁止复制转载。【原创不易,请尊重版权】这个外部变量引用了一个对象,此时,你需要未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】考虑是不是要把它置为null。当然,并不本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。是说每一次都要置为null,而是你需要考著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。虑这件事。无论是标记清理,还是引用计数,【关注微信公众号:wwwtangshuangnet】【作者:唐霜】垃圾回收都需要去确认我的所有变量中,哪些【作者:唐霜】【原创内容,转载请注明出处】是不在需要被使用的。这里不再需要被使用,【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。并不意味着变量绝对不能被其他变量引用,例著作权归作者所有,禁止商业用途转载。【作者:唐霜】如下图中右侧的三个对象相互引用了,但是通【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】过标记,引擎发现它们不会被当前程序再次使【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net用,所以就认为它们需要被回收。
【版权所有,侵权必究】
未经授权,禁止复制转载。
用同样的定律,我们可以解决引用计数中循本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。环引用的问题,假如a.b = b同时b.本文作者:唐霜,转载请注明出处。原创内容,盗版必究。a = a,那么,我们在程序结束时,要同著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。时对a和b进行操作,a.b = null; b.a = null 而不能只操作其中一个。这些原则性的编程本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。习惯需要我们在长期实践中养成。
闭包
在有了前面的知识之后再来聊闭包(clos【版权所有,侵权必究】转载请注明出处:www.tangshuang.neture),我们就可以很好的回答面试题目“【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net什么是闭包”了。很多初学者由于没有建立完【原创内容,转载请注明出处】【转载请注明来源】整的知识体系,所以无法用比较明确的词汇来【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】表达闭包的概念,当然,其实并不表示他一定【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。不懂什么是闭包,只是由于术语缺乏而已。我【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。们简而言之,“闭包是指有权访问另外一个函数作用域中的变本文作者:唐霜,转载请注明出处。【未经授权禁止转载】量的且交由其他执行上下文执行的函数。”首先,闭包是一个函数,其次它有两个要点本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net:
未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。【未经授权禁止转载】- 有权访问其他函数作用域中的变量(其实大部转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。分情况是作用域链上游的变量) 【本文受版权保护】本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】
- 交由其他执行上下文执行(不交给其他执行上【原创不易,请尊重版权】【本文受版权保护】下文的无所谓闭包) 【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】【转载请注明来源】
我们来举个常见的例子:
【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。【原创不易,请尊重版权】【版权所有,侵权必究】function plus() {
let a = 0
function add() {
a ++
return a
}
return add()
}
plus() // 1
上面这个例子中,add函数引用了plus【转载请注明来源】本文作者:唐霜,转载请注明出处。函数中的a变量(有权访问),但在调用pl未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。us()时,add函数被plus执行上下原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。文执行了,虽然我们说它引用了其他函数作用著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。域中的变量,但是它没有产生实际的效用,因著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。为它没有交给其他执行上下文执行,而是在当转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。前执行上下文中被执行了,所以,我们可以称著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。它为闭包,但是没有实际意义。
【未经授权禁止转载】【转载请注明来源】本文作者:唐霜,转载请注明出处。function increase(a) {
a.count ++
}
function plus() {
let a = { count: 0 }
function add() {
increase(a)
return a.count
}
return add()
}
你看,这个例子里面,我们在add函数中引【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。用了来自其他函数plus所在作用域的变量未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。a,甚至还交给了另外一个函数increa著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。se去修改,但是在整个执行过程中,它仍然【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】没有产生实际的效用,我们可以把incre【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。ase函数称为副作用函数,也可以把add【未经授权禁止转载】【版权所有,侵权必究】函数称为闭包,但是没有实际意义。
【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.netfunction plus() {
let base = 0
function add(x) {
return x + base
}
return add
}
const add = plus()
add(3) // 3
add(4) // 7
上面这个add函数引用了来自plus函数【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】作用域的a变量,同时交给plus函数作用【关注微信公众号:wwwtangshuangnet】【作者:唐霜】域的上一级执行上下文去执行,所以这是一个本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】正宗的有实际意义的闭包。
【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】闭包有很多应用场景。我们前文讲,函数执行【版权所有】唐霜 www.tangshuang.net【本文受版权保护】完进入回收阶段,执行上下文被销毁,其内变未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。量被回收,但对于闭包所引用的其他函数作用未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net域内的变量,由于垃圾回收机制取决于该变量【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net是否还需要被使用到,很明显,这些变量还会著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】被使用到,因此无法被垃圾回收。如果闭包被本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】交给全局,那么闭包所引用的变量就永远无法【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】被回收了,就会导致严重的内存泄露。如果在著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。我们的程序中,存在巨大的内存泄露,就会严本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】重影响性能。
【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】千锤百炼:算法
原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】人之气脉,由神而下,过五官,抚五脏,若万原创内容,盗版必究。本文作者:唐霜,转载请注明出处。里冲江,似溪水宁凝。天云山几近仙气,每日著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】晨我从山顶逐步寻路而下,行间过乐虫鸣,清【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。风缓游,时常因无路或险路而变体鳞伤,却由【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net这心境而气血平和。午至日头,在山下村里求本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】口饭足,又便寻路回去。如此过了两年。天下【关注微信公众号:wwwtangshuangnet】【本文受版权保护】武功,猛、快、准,隐匿、飞逐、斩杀,兵器未经授权,禁止复制转载。【本文首发于唐霜的博客】、招式、气功,于我而言,都不能再修了,人本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。之经脉断尽,即不可再神形俱运,便达不到武【转载请注明来源】原创内容,盗版必究。功之境界。但两年已过,我却似悟道些东西。【关注微信公众号:wwwtangshuangnet】【作者:唐霜】武功乃内外统一之术,然尽在不同门派不同宗本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。派,或遵一门而至出神入化,如剑宗至出神入【未经授权禁止转载】【作者:唐霜】化乃人剑合一,或合多门以贯通,皆以派、宗【转载请注明来源】著作权归作者所有,禁止商业用途转载。之心法,驱各式招式,不断修进,以匹及前人【本文首发于唐霜的博客】【原创内容,转载请注明出处】之功。然在所有门派宗别之外,有另外一种可【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net敌万人之道,其非武功之本却有武功之效,甚【本文受版权保护】【作者:唐霜】有逾者。天地自然,混沌犹初,汲取其精气,【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。而运其于体内,再由喷出,此一之精力可抵常【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】人十之精力,更甚者,一可抵百抵千。我不知转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】此乃为何,称之“元脉”。今元脉已开,是了未经授权,禁止复制转载。【转载请注明来源】结的时候了。
【本文首发于唐霜的博客】【未经授权禁止转载】
算法有两种,一种是为了实现之前无法实现的原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net算法,一种是为了优化之前不够好的算法。本未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。册只在乎第二种,即通过算法来提升前端代码本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net的性能。所以我们接下来讲的算法,对你的面【版权所有,侵权必究】【原创不易,请尊重版权】试毫无帮助。我们这里其实是试图用算法来降著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。低代码复杂度,从而提升性能,同时在实际工本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。作中,面对一个问题,我们可以采用更合适的著作权归作者所有,禁止商业用途转载。【作者:唐霜】算法,而不可能用一种算法解决一类问题,算著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】法有无数种,每种场景下解法不同,所以本册【作者:唐霜】本文版权归作者所有,未经授权不得转载。只讲一些前端基础的算法,这些算法来自《高【原创内容,转载请注明出处】【作者:唐霜】性能Javascript》《Web前端性【本文受版权保护】【原创内容,转载请注明出处】能优化》等书籍,我自己稍有发挥,是一些比【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net较通用的比较基础的算法,可以在日常开发中【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。经常使用。
【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。优化循环迭代
日常开发中,我们100%会用到循环迭代。著作权归作者所有,禁止商业用途转载。【本文受版权保护】但凡用到,我们就会不经意的问自己,它会被【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net运行多少次,会不会因为反复运行而造成性能【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。问题。造成循环迭代性能问题的决定因素有两【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net个:迭代次数,单次迭代的复杂度。我们可以著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。用公式“循环迭代性能=单次迭代复杂度x迭转载请注明出处:www.tangshuang.net【本文受版权保护】代次数”来表达它们之间的关系。其实这非常未经授权,禁止复制转载。【版权所有,侵权必究】容易理解,迭代的次数越多,性能越差,单次本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。迭代运行消耗性能越多,总体消耗性能越多。【本文首发于唐霜的博客】【未经授权禁止转载】因此,我们的优化方案就围绕这两个因素展开未经授权,禁止复制转载。原创内容,盗版必究。。
未经授权,禁止复制转载。【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net首先,降低单词迭代的复杂度。
转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。我们可以用到两个技巧:事务提升;倒序迭代【未经授权禁止转载】【作者:唐霜】。
本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。【本文受版权保护】【本文受版权保护】事务提升是指把一些事情提升到循环体之外进本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】行,而不要在循环体内去做这些吃力不讨好的【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net事情。比如我们常见的写法:
【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。【转载请注明来源】【访问 www.tangshuang.net 获取更多精彩内容】for (let i = 0, len = items.length; i < len; i ++)
其中我们把获得items长度的动作前置到【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。循环开始,而非每次判断循环是否需要结束时【本文受版权保护】本文作者:唐霜,转载请注明出处。再去读取长度。当然,对于现代浏览器而言,未经授权,禁止复制转载。原创内容,盗版必究。此处的优化所带来的性能提升微乎其微,但是本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net思路上就是希望你能过把一些固定的事务,从【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。循环体中脱离出来,有的可以提升到前面,有转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。的可以在循环体中只拿到一些信息,等循环结【本文受版权保护】转载请注明出处:www.tangshuang.net束之后再利用这些信息进行计算,而不是在循【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net环体内实时进行计算。
本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】【未经授权禁止转载】倒序迭代是指从后往前迭代,在一些特定的查【关注微信公众号:wwwtangshuangnet】【本文受版权保护】找场景下非常有用且高效。它的大致写法如下原创内容,盗版必究。转载请注明出处:www.tangshuang.net:
未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】for (let i = items.length; i --;) {
const item = items[i]
...
}
这里使用了非常有意思的技巧,我们没有给f【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。or第3段,而是在第2段中使用了后置自减【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。操作,前置自减和后置自减的区别在于,前置【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】是返回运算后的值,后置是返回运算前的值,【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。所以我们这里用返回运算前的值作为判断循环【原创不易,请尊重版权】【本文首发于唐霜的博客】是否要继续的依据,当i为0时会自动跳出循【未经授权禁止转载】【版权所有,侵权必究】环,而在循环体内的i则是已经完成自减运算未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net的值,所以items[i]中的i值其实比【未经授权禁止转载】【本文首发于唐霜的博客】i–的值小1.
本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】【未经授权禁止转载】未经授权,禁止复制转载。倒序迭代在进行某些查找时,可以从末尾进行【本文首发于唐霜的博客】【本文受版权保护】查找,在找到之后可以尽快break,从而【版权所有】唐霜 www.tangshuang.net【本文受版权保护】避免遍历整个列表。
【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】原创内容,盗版必究。转载请注明出处:www.tangshuang.net其次,减少迭代的次数。
转载请注明出处:www.tangshuang.net【版权所有,侵权必究】【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net我们可以用到三个技巧:增加步幅以减少迭代【转载请注明来源】未经授权,禁止复制转载。次数;循环体展开技术;提前结束遍历。
【本文受版权保护】【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】增加步幅比较好理解,我们来看一个优化的例【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】子。
【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】for (let i = 0, len = items.length; i < len; i ++) {
if (i % 2 === 1) {
...
}
}
这段代码中,我们通过一个 i % 2 来【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net处理一些内容。但是对于for而言,它会迭【版权所有,侵权必究】【原创不易,请尊重版权】代items的长度。我们如下优化:
【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net【未经授权禁止转载】【本文首发于唐霜的博客】for (let i = 0, len = items.length; i < len; i += 2) {
...
}
现在,我们不需要通过 i % 2 来进行著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】判断,因为我们每次迭代结束的时候,i自增【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】了2.所以,这个优化不仅减少了迭代的次数本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。,还降低了单次迭代内的复杂度。
【原创内容,转载请注明出处】原创内容,盗版必究。循环体展开技术是一种分批执行的技术,当我著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】们要需要对很多元素进行遍历的时候,可以把【作者:唐霜】本文作者:唐霜,转载请注明出处。一个复杂的循环体,拆分为多个简单的循环体本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】,从而让单个循环体的复杂度降低进而降低整转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】个循环的消耗。实际上,它一方面通过分批次【作者:唐霜】本文作者:唐霜,转载请注明出处。的方式减少迭代次数,另一方面也是降低了单本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】次迭代的复杂度。
未经授权,禁止复制转载。原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】提前结束遍历主要是利用一些迭代方式,提前【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】结束。一种是在for/while中使用r【版权所有】唐霜 www.tangshuang.net【作者:唐霜】eturn,另一种是使用find/som【转载请注明来源】【作者:唐霜】e等数组方法。例如下面这段代码:
本文版权归作者所有,未经授权不得转载。【转载请注明来源】【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】items.some((item) => {
if (item.price < 13) {
process(item)
return true
}
})
上面这段代码并没有将items.some【本文受版权保护】著作权归作者所有,禁止商业用途转载。()作为if的条件进行判断,而是利用它可【关注微信公众号:wwwtangshuangnet】【转载请注明来源】以通过return true来提前结束遍【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。历的特性,只在第一次找到某个元素时执行p【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。rocess函数。
未经授权,禁止复制转载。【作者:唐霜】条件语句优化
if…else在我们日常开发【转载请注明来源】【转载请注明来源】中用的极多,可以说是我们最常用的语句。它【关注微信公众号:wwwtangshuangnet】【作者:唐霜】的问题在于,如果我们没有一定的策略,会导【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。致全部的条件都去判断一遍,如果每次判断的【本文受版权保护】【本文首发于唐霜的博客】逻辑比较复杂,就会消耗掉比较多的性能。我著作权归作者所有,禁止商业用途转载。【作者:唐霜】们有一些策略对条件语句进行优化,主要有:【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net优先判断高频条件;二分法思想;用策略模式【本文首发于唐霜的博客】【原创不易,请尊重版权】干掉判断。
【转载请注明来源】【转载请注明来源】在一些条件需要进行计算的情况下,如果有多【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net组条件都需要执行,就会消耗比较多性能,这转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。种情况下,我们应该尽可能避免执行过多的条转载请注明出处:www.tangshuang.net【本文受版权保护】件判断。我们需要根据实际情况,将可能性更【本文受版权保护】未经授权,禁止复制转载。大的条件放在前面,这样,在大部分情况下,【转载请注明来源】未经授权,禁止复制转载。只需要执行前面几条判断就可以退出这一组条【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。件语句,从而减少被执行的条件条数,减少性本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。能消耗。例如:
【转载请注明来源】未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net【转载请注明来源】if (condi(1)) {}
else if (condi(2)) {}
else if (condi(3)) {}
else if (condi(4)) {}
else {}
假如上面的代码中,condi(1)发生的【转载请注明来源】【原创不易,请尊重版权】概率并不大,那么上面的代码每次在被执行时著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】,都会走到这一条判断,而大部分情况下都做原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。了无用功。因此,我们可以把最常用的con【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。di(4)调整到前面:
原创内容,盗版必究。转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。if (condi(4)) {}
else if (condi(3)) {}
else if (condi(2)) {}
else if (condi(1)) {}
else {}
在条件具有连续性,且条目很多的时候,它的未经授权,禁止复制转载。【作者:唐霜】复杂度是O(n),通过二分法的思维可以将【版权所有,侵权必究】【本文首发于唐霜的博客】复杂度降低到O(logn)。在大部分情况下,条件判断都是非此即彼【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。的,因此二分法在这种场景下可以起作用。如未经授权,禁止复制转载。【转载请注明来源】:
本文版权归作者所有,未经授权不得转载。【作者:唐霜】本文作者:唐霜,转载请注明出处。if (x > 10) {
if (x > 15) {
if (x > 18) {}
else {}
}
else {
if (x > 13) {}
else {}
}
}
else {
if (x > 5) {
if (x > 8) {}
else {}
}
else {
if (x > 3) {}
else {}
}
}
通过这种二分法思维,在一些情况下可以使得【作者:唐霜】本文作者:唐霜,转载请注明出处。判断次数减少。但是也要注意,这也意味着它【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】的判断数量是一定的,也就是说用正常的条件原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】判断可能只需要判断2条,而这种判断方法不本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】得不判断5条后才得出结论。
【未经授权禁止转载】【作者:唐霜】【原创不易,请尊重版权】另外一种技巧是采用mapping来避免条【作者:唐霜】转载请注明出处:www.tangshuang.net件判断,这种方案在某些场景下也符合策略模本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】式的。具体操作如下:
未经授权,禁止复制转载。【本文受版权保护】switch (a) {
case 1: do1(); break;
case 2: do2(); break;
case 3: do3(); break;
case 4: do4(); break;
}
上面这种条件判断来执行对应函数的方式并没未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】有什么不好,但是每个case都会跑一遍判【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】断过程。如果我们把它优化为如下:
本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】原创内容,盗版必究。转载请注明出处:www.tangshuang.netconst dos = {
1: do1,
2: do2,
3: do3,
4: do4,
}
const dofn = dos[a]
dofn?.()
则不需要任何条件判断,而是通过读取map【未经授权禁止转载】【关注微信公众号:wwwtangshuangnet】ping上的函数来执行。这种技巧适合a的【版权所有】唐霜 www.tangshuang.net【转载请注明来源】取值是固定的,其形成的条件是离散的。这种原创内容,盗版必究。转载请注明出处:www.tangshuang.net方案直接干掉了条件判断,这样就可以大大提著作权归作者所有,禁止商业用途转载。【本文受版权保护】升程序的执行效率。
【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】使用递归
简单讲,递归就是在函数内部调用函数自身的【未经授权禁止转载】【本文受版权保护】行为。前面我们讲过,执行上下文是在函数开原创内容,盗版必究。原创内容,盗版必究。始执行前创建的,我们通常会在递归中通过判本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】断条件跳出递归,但是由于递归函数的执行意【本文受版权保护】【版权所有】唐霜 www.tangshuang.net味着执行上下文的复制,在执行栈中不断入栈未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。新内容,从而占用大量资源。它对内存的开销【本文首发于唐霜的博客】【原创内容,转载请注明出处】与递归函数的执行次数成正比。而如果处理不【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。当,没有跳出递归,就会导致“死循环”。现【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。代浏览器对“尾递归”进行了优化,所谓尾递【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。归就是在函数的末尾把递归进行返回,例如下【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】面这段代码:
【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。function a() {
if (!x) {
return
}
return a()
}
我们前面讲到作用域和执行上下文的关系,浏本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net览器正确识别这是尾递归后,可以不需要反复【转载请注明来源】著作权归作者所有,禁止商业用途转载。的去确认其执行上下文。
【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。优化字符串处理
字符串处理主要包括合并、搜索、剪切、重排未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net、遍历等。要提高字符串处理的能力,我们需【本文受版权保护】本文作者:唐霜,转载请注明出处。要掌握一些技巧。常用技巧有:
本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net- 使用索引 【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】
- 将字符串转化为数组,再用数组的方法进行操原创内容,盗版必究。【本文受版权保护】作,最后再join(”)连接转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。回字符串 原创内容,盗版必究。【本文受版权保护】
- 搜索时从字符串中间开始,采用二分法 【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】
优化正则表达式
正则表达式是非常复杂的一套知识体系,要掌【作者:唐霜】未经授权,禁止复制转载。握它的细枝末节,我们可能需要读一本书。坏【转载请注明来源】未经授权,禁止复制转载。的正则表达式,在运行时很消耗性能,当然,【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。为什么消耗性能,需要我们去理解正则表达式【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。的查找实现的算法,本册无法提供完整的解释本文作者:唐霜,转载请注明出处。【未经授权禁止转载】,因此,这部分内容需要你作为课外知识去补【原创内容,转载请注明出处】【转载请注明来源】充。我们提供一些优化正则表达式的建议:
转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】- 不要写过长的复杂的正则表达式,不要以为用【原创内容,转载请注明出处】【未经授权禁止转载】一个正则表达式能做到的就一定要用一个正则【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net,有可能你把这个匹配拆分为多个步骤,效率【本文受版权保护】本文版权归作者所有,未经授权不得转载。可以翻几十倍 【原创不易,请尊重版权】【转载请注明来源】
- 相同的正则表达式赋值给一个变量重复使用,本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】否则在遇到正则表达式时其引擎需要重新编译本文作者:唐霜,转载请注明出处。【本文受版权保护】,浪费资源 【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net
- 更快结束匹配,就和前文优化if̷原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】0;else一样,如果你可以让正则表达更【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net清楚,让它在匹配时尽快发现无法匹配,以结【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net束匹配的话,就一定要这样去做 【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】
- 减少分支数量 本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】【原创内容,转载请注明出处】【原创不易,请尊重版权】
- 尽量具体 【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。
正则表达式和自己写代码实现,有的时候要看【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。具体情况,说不定虽然自己写了看上去比较丑转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】的代码,但是相对于正则而言,效率更高。
本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。独门绝技:缓存
本文作者:唐霜,转载请注明出处。原创内容,盗版必究。原创内容,盗版必究。西无一从西域回来,寻我不得,在江湖发下悬本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】赏令,称能带我见者赏千金。十二年间游历天【转载请注明来源】【未经授权禁止转载】下,行侠仗义之理念为忘,亦结交豪杰繁多。【原创内容,转载请注明出处】未经授权,禁止复制转载。我听闻西无一消息,便赶了一个月到长安。正【作者:唐霜】【原创内容,转载请注明出处】值七月,繁花似锦,商队如流。除与西无一汇转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】合之外,江南剑无宗李赋、山东绝圣拳宗师笑【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。为来、荆州通刀门韩式、幽州归元神功郑极吾本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。,这些曾经结交的友人,都一一在长安俱首。著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】八月正是出海之选,故我向他们阐明了自己的【原创内容,转载请注明出处】【原创内容,转载请注明出处】打算。西无一劝我不去,如今经脉尽断的独臂著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。废人,何必不放下,享受这天下凡美。也有人【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。愿随我赴汤蹈火在所不惜。我告之“人之生可本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。重,若不报仇血恨,愧于立这天地。”西无一【原创内容,转载请注明出处】【本文受版权保护】见说我不服,便刀一横“想要报仇,先胜我再转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】说。”说完,将半壶好酒摔了一地,拔剑便飞【原创内容,转载请注明出处】【原创内容,转载请注明出处】来。曾叱诧风云的西无一,如今在我看着,却未经授权,禁止复制转载。原创内容,盗版必究。并无锋利,其剑法随行云流水,却在我眼里每著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。招每式都极为清楚,也不见得很快。“无一兄本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】,人之强大,除了武功之外,还有一种,你可【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net知不?”“废话少说,吃住我这招。……啊!【本文首发于唐霜的博客】【转载请注明来源】!!”他虽使出了毕生的功力,却只见着我两著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】指夹住他的剑锋,他却动弹不得,吃惊的一动转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。不动。“我练剑三十年,虽不讲天下无敌,亦【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。可称绝世奇存,没曾想在你这里却如此轻轻松原创内容,盗版必究。【本文首发于唐霜的博客】松,便破了我这一招绝外回魂,老了还是……【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。”“哎,无一兄无需自惭,在场的各位在这天【原创内容,转载请注明出处】【作者:唐霜】下都是绝顶的豪杰,只是这方世之间,除了武转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。功之外,还有超出其范畴的存在,我称其为元【本文受版权保护】【原创内容,转载请注明出处】脉,无需招式或心法,便可运用自然之力,破未经授权,禁止复制转载。【本文受版权保护】一切招式。”“没曾想你断了经脉,还少一个【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。胳膊,竟能超越我们,我韩式兄弟追随意已决转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。,愿随你赴汤蹈火,去剿平那鬼窍团。”“既【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。然如此,我们八月初二出发。”
【作者:唐霜】【转载请注明来源】原创内容,盗版必究。【未经授权禁止转载】
和网络缓存不同,我们在客户端甚至代码层面转载请注明出处:www.tangshuang.net【作者:唐霜】会用到一些缓存技术,这些缓存技术让我们可【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net以更高效的去执行某些动作,从而让使用我们【转载请注明来源】转载请注明出处:www.tangshuang.net应用的用户感受不到该技术的存在,但却认为【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。应用变快了。当然,缓存也存在一些缺点,因【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。此,我们在实施缓存技术时,要有选择的优化未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。缓存策略。
【版权所有,侵权必究】【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】运行时缓存技术
在代码中,我们会反复的执行某些技术,但如转载请注明出处:www.tangshuang.net【作者:唐霜】果基于相同的技术,且内容相同的话,就会导本文版权归作者所有,未经授权不得转载。【作者:唐霜】致重复计算,这些计算其实是没有必要的,因【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】此我们可以把它们缓存起来,在第二次计算时【未经授权禁止转载】【原创不易,请尊重版权】直接使用缓存。例如:
【转载请注明来源】【转载请注明来源】本文作者:唐霜,转载请注明出处。const items = [1, 2, 2, 5, 3, 2, 4, 1] const results = items.map(processor)
在上面的代码中,items中有重复的2和著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。1,假如processor是一个计算量庞【本文受版权保护】【版权所有,侵权必究】大的计算过程,那么,这些重复的计算,就可未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】以使用缓存。我们可以采用一种基于参数的缓【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net存方案:
未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】let cache = {}
function processor(num) {
if (Object.prototype.hasOwnProperty.call(cache, `${num}`)) {
return cache[num]
}
const result = ...
cache[num] = result
return result
}
processor.clear = () => cache = {}
const items = [1, 2, 2, 5, 3, 2, 4, 1]
const results = items.map(processor)
processor.clear()
我们使用了一个cache来保存每一个参数【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。对应的计算结果。但是需要注意,我们应该提转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。供一个clear方法,因为如果我们长期不未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】清理cache,就会导致内存溢出。通过这【本文受版权保护】本文版权归作者所有,未经授权不得转载。样的改造,就可以让我们的程序避免重复的计本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net算。
【版权所有】唐霜 www.tangshuang.net【本文受版权保护】运行时缓存策略非常多,且很难一一举例,我【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】们应该在开发中不断去尝试和优化,而不是限【版权所有,侵权必究】【本文首发于唐霜的博客】于上面这一种场景。例如react提供的u本文作者:唐霜,转载请注明出处。原创内容,盗版必究。seMemo,就是一种非常有意思的缓存方原创内容,盗版必究。【作者:唐霜】案,在react退出hooks之前,社区【版权所有,侵权必究】未经授权,禁止复制转载。提供了一种叫reselector的方案,【版权所有,侵权必究】原创内容,盗版必究。它的效果和useMemo或者memo很像未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】,但是用法上却没有useMemo那么简洁【原创内容,转载请注明出处】【转载请注明来源】。这说明在我们的开发中,我们可以去优化缓著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】存方案,使它既能提供高效的运行性能,又有【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。更好的开发体验。
【本文首发于唐霜的博客】【原创内容,转载请注明出处】【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。前端持久化存储
所谓持久化,就是当应用被卸载时,其存储仍转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。然还存储。这里的卸载包括刷新页面、关闭t【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】ab、关闭浏览器等操作。我们常见的持久化【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。存储有cookie、sessionSto转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。rage/localStorage等,另【本文受版权保护】【版权所有,侵权必究】外我还比较推荐indexedDB,我有专门出过一系列教程介绍indexed【原创内容,转载请注明出处】【本文首发于唐霜的博客】DB,并且开发出了非常简易的indexedDB封装库,你可以在我博客中阅读。持久化存储的好处本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。是帮助我们避免不必要的重复计算,它和上面【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】的运行时缓存异曲同工,只不过它的缓存更加原创内容,盗版必究。未经授权,禁止复制转载。持久。基于这两者的特点,我们可以得出结论转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】,持久化存储是用于哪些可以一直保存起来,原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。在可预见的范围内不会自己发生任何变化的值本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。。
转载请注明出处:www.tangshuang.net【转载请注明来源】本文作者:唐霜,转载请注明出处。你应该如何选择使用哪一种作为持久化缓存呢本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。?
未经授权,禁止复制转载。【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】- cookie: 不用,除非在涉及前后端交【本文受版权保护】【原创不易,请尊重版权】互时不得不用的情况下 【未经授权禁止转载】本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】未经授权,禁止复制转载。
- sessionStorage: 当你希望【版权所有,侵权必究】【版权所有,侵权必究】用户刷新页面保持存储,但关闭页面后清空存本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。储时使用 转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】原创内容,盗版必究。【未经授权禁止转载】
- localStorage: 当你希望用户【关注微信公众号:wwwtangshuangnet】【转载请注明来源】关闭后保持存储,再次打开时还存在的情况时原创内容,盗版必究。【未经授权禁止转载】使用 【转载请注明来源】转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】
- indexedDB: 当你希望存储比较多【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】的数据,有条理的管理它们时,使用inde【原创内容,转载请注明出处】【转载请注明来源】xedDB,它像一个真正的前端数据库一样【未经授权禁止转载】【本文受版权保护】,具有记录的性质,可以创建便捷的条件查询 【原创不易,请尊重版权】【转载请注明来源】
我在腾讯内开发ShadowLog时,就采原创内容,盗版必究。【作者:唐霜】用了indexedDB,它把用户在应用中【关注微信公众号:wwwtangshuangnet】【本文受版权保护】操作产生的日志存储在indexedDB中原创内容,盗版必究。【转载请注明来源】,然后我在一个webworker中去读取本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。出来,进行处理后上报这些日志。注意,在w【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.netebworker中我们是不能使用loca【原创内容,转载请注明出处】【原创不易,请尊重版权】lStorage的,而且从数据量上讲,l【转载请注明来源】【未经授权禁止转载】ocalStorage存到5M就是极限了本文作者:唐霜,转载请注明出处。原创内容,盗版必究。,而indexedDB可以存到500M,原创内容,盗版必究。转载请注明出处:www.tangshuang.net可以存很多数据。
【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。利用前端持久化存储,我开发了databa【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】xe这个库(当然它有多种缓存模式),它的著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】核心思想是把从后端请求回来的数据存在in【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。dexedDB中,这样在下一次请求相同数【版权所有,侵权必究】【原创内容,转载请注明出处】据时,就不需要从后端去读取,而是直接从i【转载请注明来源】【版权所有】唐霜 www.tangshuang.netndexedDB中读取。这样我们可以极快著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。的对界面进行渲染,减少等待请求的时间。
【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。登峰造极:高性能架构
【原创内容,转载请注明出处】原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】“我等今日已久,自上次被你重伤,我便知你【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】定会再来寻仇,只可惜,我已练成鬼魉神功九未经授权,禁止复制转载。【本文受版权保护】重天,今日便是你的死期。”只见的那鬼王全【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】是包裹一团黑气,四大护法皆如兽样似人非人【作者:唐霜】本文作者:唐霜,转载请注明出处。。“你作恶多端,世间早已容不下你,或许只【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。有地狱能容的下你,今日就是了断。”直见那【原创不易,请尊重版权】【未经授权禁止转载】四大护法冲飞而来,韩式兄弟迎将而去,然四【本文受版权保护】原创内容,盗版必究。手难敌八爪,很快落了下风。那四大护法才两【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】年有余,武功却飞进大截,似有什么秘密。天著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net地之间,火、气、水、光,物与物皆可变换。原创内容,盗版必究。未经授权,禁止复制转载。韩式兄弟被打的飞落过来,我慢步上前,将他【访问 www.tangshuang.net 获取更多精彩内容】【本文受版权保护】们接住,韩大口中吐血,中了内伤。我运动元【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】脉,从掌心过其肩臂注入其体内,不过一瞬,【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。他便站起来,“这是怎事?适才还胸痛气闷,【作者:唐霜】著作权归作者所有,禁止商业用途转载。现在便极有精神,像是没有打斗过般。看来我未经授权,禁止复制转载。【未经授权禁止转载】兄弟二人就算再修炼一百年,也不能及你一二【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net了。”“你先歇着。”……那四大护法各自都【原创不易,请尊重版权】未经授权,禁止复制转载。服下一颗手指般大小的药丸,一时间,他们青【版权所有,侵权必究】原创内容,盗版必究。筋暴起,头发脱落,衣服裂开,各自生出些莫【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net名的器官来,有露出肉翅,有甩出毛尾。“太本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。诡异了,原来这鬼耧岛勾结东瀛,靠这断魂丸【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net营生,这便是这个鬼窍团的秘密,如此下去,【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net天下将尽数毁在他们手中。”韩二道。那四大转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】护法变身之后,各个凶神恶煞,兽畜难辩,以【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net极速飞来。世间之物,除光以外,皆有速,唯【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。独光无速,却无人能比光更快,而我已超了光著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。之速。“是了断的时候了”我心想。便拾起地转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。上被打落的瓦片。当我腾空跃起时,时空已经著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】凝固,瓦片锋利的一侧足以割破其喉咙,待我【作者:唐霜】转载请注明出处:www.tangshuang.net轻薄落地,早已将那四畜断了气。就在那鬼王本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。诧异而慌忙使用绝招时,我躲过了他是尽全力未经授权,禁止复制转载。【作者:唐霜】轰出的气道,出现在他眼前,他已目瞪口呆,【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】不敢相信自己的眼睛。“此乃天道!”我一掌未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】从他的天玄穴拍下,见他七窍流血,跪倒在地著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】,世间再无鬼窍团。我不知他倒地一刻再想什未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net么,儿时母亲给我做饭,父亲砍柴归来的画面转载请注明出处:www.tangshuang.net【未经授权禁止转载】涌现眼前。二十多年,今终大仇得报。
【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。
当我们使用某些细节的技术仍然无法解决卡顿【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】、慢等问题时,我们就应该考虑,是否是因为【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net我们所设计的整套技术实现本身就存在问题,转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】或者说我们的架构不够高性能。在react转载请注明出处:www.tangshuang.net原创内容,盗版必究。推出16版本之前,它使用了经典的virt本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】ual dom架构,通过diff和pat【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。ch两套动作实现DOM的更新,然而随着r【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。eact应用暴露出越来越多的性能问题后,【原创内容,转载请注明出处】【原创不易,请尊重版权】核心团队成员发现diff和patch占用【本文受版权保护】【关注微信公众号:wwwtangshuangnet】了长时间的计算,导致diff和patch原创内容,盗版必究。本文作者:唐霜,转载请注明出处。这两个过程,浏览器都处于等待状态,也就是原创内容,盗版必究。转载请注明出处:www.tangshuang.net卡顿。为了解决这一问题,react推出了本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net新的fiber架构,对diff进行大刀阔【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。斧的重构,实现了时间分片等特性,让dif【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】f和patch两个阶段分开调度,从而释放原创内容,盗版必究。【原创不易,请尊重版权】了长任务,除了操作DOM本身可能带来的卡本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。顿,基本上就不存在长任务,因此,拥有更高【原创内容,转载请注明出处】【本文首发于唐霜的博客】的性能。我认为,从应用整体层面去规划,实【版权所有,侵权必究】本文版权归作者所有,未经授权不得转载。施高性能架构,是让应用拥有性能底线的基础本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。,如果应用架构本身就是低性能的,那么再怎【转载请注明来源】【作者:唐霜】么优化,都无法突破架构性能的下线,架构本【本文受版权保护】著作权归作者所有,禁止商业用途转载。身就已经让性能的瓶颈卡在那里了,你无法获本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。得更高的性能。因此,在应用架构设计阶段,原创内容,盗版必究。【本文受版权保护】有判别高性能架构的思维,是非常重要的,因【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。为架构一旦确定,就会永远影响应用的性能。
本文作者:唐霜,转载请注明出处。原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net我们无法断定哪一种架构性能更好,同时,不【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】同的场景下设计不同的架构来实现我们的目标【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。,所带来的副作用也各不相同。例如同样是面著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】对整个应用代码结构庞大复杂的问题,我们可【本文首发于唐霜的博客】【转载请注明来源】以采用分层架构,也可以采用微前端架构,或【本文首发于唐霜的博客】【本文首发于唐霜的博客】者组件-应用架构,即使都采用微前端架构,【原创内容,转载请注明出处】【版权所有,侵权必究】我们所选型的微前端框架也会影响我们的代码本文作者:唐霜,转载请注明出处。【本文受版权保护】结构,最终所表现出来就是性能不同。一般而【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。言,越接近原生,性能越好,但是编写过程越著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】头疼,而抽象度越高,往往性能劣势更明显,转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】此时,常常需要做一些巧妙的设计,来让开发【未经授权禁止转载】本文作者:唐霜,转载请注明出处。者可以自己实现性能的提升,例如从框架内部本文版权归作者所有,未经授权不得转载。【本文受版权保护】提供一些方法,开发者一旦使用这些方法,就未经授权,禁止复制转载。未经授权,禁止复制转载。会让框架运行时采用缓存策略,从而加速性能【转载请注明来源】【原创不易,请尊重版权】。
【原创不易,请尊重版权】【本文首发于唐霜的博客】接下来,我将简单介绍几种架构设计的思路,著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】这些思路都是从性能角度出发提供建议。
【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】无状态化架构
前端也开始流行函数式编程,其中的重要思想【转载请注明来源】【作者:唐霜】之一就是无状态化。这里的无状态化并非指整本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。个应用中不存在状态,而是将状态统一交给一【作者:唐霜】【转载请注明来源】个状态管理器去管理,而此外的其他部分全部著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。按照函数式的思维,驱动整个应用的不断流转【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。。
【转载请注明来源】【转载请注明来源】无状态化架构之所以有较高的性能,原因在于【版权所有,侵权必究】未经授权,禁止复制转载。编写程序时,我们会刻意的控制内存占用,由【原创内容,转载请注明出处】【版权所有,侵权必究】于状态交给统一的状态管理器管理,也就意味转载请注明出处:www.tangshuang.net【版权所有,侵权必究】着当前程序本身在运行过程中,并不积累内存【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。,运行完之后,内存就会被释放掉,所以总体【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net而言,就不会出现内存溢出等情况。
【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net当然,无状态化也有一些缺点可能会影响性能本文作者:唐霜,转载请注明出处。【作者:唐霜】。例如我们往往追求函数的纯净性,而这种纯本文版权归作者所有,未经授权不得转载。【本文受版权保护】函数的思想,就会导致相同的逻辑,分散到不【版权所有】唐霜 www.tangshuang.net【本文受版权保护】同函数中,就不得不执行两次。
【转载请注明来源】未经授权,禁止复制转载。【原创内容,转载请注明出处】异步化架构
前端开发是接触异步最多的开发领域,因为我【作者:唐霜】【本文受版权保护】们通常需要使用ajax或其他形式从服务端本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】加载资源,而所有的这些逻辑,往往都会放在著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】异步任务中运行。
著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】异步化架构之所以有较高的性能,原因在于它未经授权,禁止复制转载。原创内容,盗版必究。对任务进行拆分,从而避免在同一帧执行过长转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net的任务,进而避免的卡顿现象。
【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。原创内容,盗版必究。但是,异步化也会让我们的代码难以理解,因【转载请注明来源】本文作者:唐霜,转载请注明出处。为同一任务的代码往往会被分为好几段,甚至【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】散落在不同地方,这就会导致我们在阅读某一本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】逻辑时,无法有一个完整的思路。
【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】队列
前端很少讲队列,但是我认为队列是解决异步【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】化架构问题的重要手段。简单讲,我们会在前原创内容,盗版必究。转载请注明出处:www.tangshuang.net端应用中构建一套队列服务,当我们需要按照【本文首发于唐霜的博客】【转载请注明来源】队列的形式执行任务时,就将任务丢给队列服转载请注明出处:www.tangshuang.net【本文受版权保护】务,当任务执行完时,又会回到原始的位置继【本文受版权保护】【原创内容,转载请注明出处】续执行。队列具有先进先出的特点,因此,在【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net一些需要按照顺序进行执行的场景非常有用。著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】同时,我们还可以基于参数对任务进行分类,【本文首发于唐霜的博客】【转载请注明来源】假如同一任务被再次push进队列时,我们【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。可以采用提升上一个任务的优先级的策略,让【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net上一个未完成的任务马上执行,然后再把当前未经授权,禁止复制转载。【本文首发于唐霜的博客】这个任务push进队列;当然,我们也可以著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】把上一个任务直接丢弃,使用新任务的结果。
转载请注明出处:www.tangshuang.net原创内容,盗版必究。未经授权,禁止复制转载。队列之所以具有较高的性能,和异步化架构是【未经授权禁止转载】本文作者:唐霜,转载请注明出处。一致的,都可以起到通过时间分片的方式,拆【本文受版权保护】【关注微信公众号:wwwtangshuangnet】分大任务,让一个可能占用长时间的任务,分未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。为几段来执行。
【原创内容,转载请注明出处】【转载请注明来源】【本文首发于唐霜的博客】【转载请注明来源】协程
协程在前端场景下是指在多个任务之间调度,【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。以实现类似并发的效果。我们知道js执行是【未经授权禁止转载】本文作者:唐霜,转载请注明出处。单线程的,这也就意味着如果不加处理,一个【本文受版权保护】【原创内容,转载请注明出处】任务就必须从头到尾执行,导致其他任务排队本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。等待,出现页面卡顿。而通过协程的架构,我【转载请注明来源】转载请注明出处:www.tangshuang.net们就可以设计出基于时间分片的多任务切换,转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。达到类似并发的效果。这也就是react 【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。fiber的设计思路,以及新版本reac本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.nett中suspense的由来。
【本文首发于唐霜的博客】【本文受版权保护】虽然ES本身有yield来实现这种简单的著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。协程,随后又发布了await,但是从上文未经授权,禁止复制转载。【未经授权禁止转载】我们可以看到,协程架构的核心不是在实现任著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。务的中断与上下文的保留,而在于调度。我们【作者:唐霜】【原创不易,请尊重版权】做架构设计的目标,不是让开发者去刻意使用【版权所有,侵权必究】未经授权,禁止复制转载。协程,而是在框架内自动集成调度,让开发者转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。感受不到协程的存在。
【访问 www.tangshuang.net 获取更多精彩内容】本文作者:唐霜,转载请注明出处。协程架构之所以具有较好的性能,和上面的异原创内容,盗版必究。【版权所有,侵权必究】步化架构、队列其实大同小异,不同的地方在【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。于,协程架构把这种任务拆分进行了重组,让【原创不易,请尊重版权】【转载请注明来源】开发者感受不到其拆分的过程,同时又有并发本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】的感受。
原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。华山论剑:React性能优化
【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】“荫哥,天下若大,你想去何处?”“秀若,【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。你我一起闯荡江湖如何?”“只要跟着荫哥,【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。天涯海角我皆无怨悔。”……夕阳甚红,镇海著作权归作者所有,禁止商业用途转载。【转载请注明来源】村的海唱着悠扬的乐,夜慢慢醒来。……“人【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。不在江湖,名号却远播天下,你若再不出山,【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】天下都要把你当神了。”“无一兄从长安千里【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net赶来,不知何事?”“你斩杀鬼王一事已惊动【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net了当今皇帝,他欲请你入京,封官加爵,我看【版权所有,侵权必究】转载请注明出处:www.tangshuang.net你还是和我赶快回京,享受荣华富贵。”“无【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。一兄说笑了,你我相识一场,定知我不是贪图【本文受版权保护】【原创不易,请尊重版权】富贵之人,倒是快讲真话来。”“你斩杀鬼王【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net为天下苍生除了一大患,本是天大的好事,但【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。鬼窍团余孽未尽,鬼王卒,这些余孽各自为王【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net,如今反而搞得天下混乱。”“我只为自己报【转载请注明来源】【未经授权禁止转载】仇,并未考虑此后果。”“虽然你是自己复仇【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net,但天下尽人皆知,你有正义之心。”“……本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】可我也无办法啊,双手难扫天下。”“办法倒本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。不是没有,四月十五,华山推选武林盟主,届【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】时你若坐上盟主之位,集结天下正义侠士,号转载请注明出处:www.tangshuang.net原创内容,盗版必究。令各地门派共同剿匪,必能尽快将这些余孽清未经授权,禁止复制转载。【版权所有,侵权必究】剿。”“无一兄,心怀天下,我甚不如你!既原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】然你已出山,那我岂能袖手旁观。”
未经授权,禁止复制转载。【本文首发于唐霜的博客】【作者:唐霜】【关注微信公众号:wwwtangshuangnet】
作为当下最流行的前端视图层驱动框架,re【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】act提供了一套把UI视图抽象化的解决方转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。案。由于其高度的抽象性,导致开发者在使用本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。过程中,常常触发一些意料之外的逻辑,从而本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。带来不必要的性能问题。本章将总结笔者过去【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】几年中使用react遇到的性能问题,即提未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net供一些解决方案。
【访问 www.tangshuang.net 获取更多精彩内容】【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.netReact渲染机制
在开始之前,我们必须了解react的渲染未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net机制,否则我们无法正确思考和处理工作中遇【作者:唐霜】【原创内容,转载请注明出处】到的性能问题。React的渲染,包含如下【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。知识:
【作者:唐霜】未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。- createElement->Vi原创内容,盗版必究。【原创不易,请尊重版权】rtual DOM 【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。
- react生命周期 未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】【本文受版权保护】
- 从Virtual DOM到真实DOM 【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】
- fiber,reconciler,sch【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】eduler 本文作者:唐霜,转载请注明出处。原创内容,盗版必究。
作为一个视图层驱动框架,react本身的【本文受版权保护】本文版权归作者所有,未经授权不得转载。架构可以分为3层:Virtual DOM本文作者:唐霜,转载请注明出处。【作者:唐霜】层;Reconciler层;Render【未经授权禁止转载】【本文受版权保护】er层。其中,Virtual DOM是r【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。eact最原始最核心的概念,它用于描述一转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net套跨平台的UI结构,注意,这里的结构包含【原创不易,请尊重版权】【未经授权禁止转载】其逻辑和事件。Reconciler层是r【未经授权禁止转载】原创内容,盗版必究。eact中最重要的,区别于其他任何基于V【本文首发于唐霜的博客】【转载请注明来源】irtual DOM的框架(例如vue、本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。avalon、preact等)的关键,该【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】层用于对Virtual DOM进行处理、【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】对比、计算,对用户事件进行调度,推动组件【本文首发于唐霜的博客】【原创不易,请尊重版权】生命周期等等工作。Renderer层用于【作者:唐霜】本文版权归作者所有,未经授权不得转载。把Virtual DOM映射到具体的某个转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】平台上,表现出具体的UI和人机交互逻辑,本文作者:唐霜,转载请注明出处。【作者:唐霜】比较常见的有ReactDOM和React未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。Native。
未经授权,禁止复制转载。【原创内容,转载请注明出处】React现在的版本基于fiber架构完本文作者:唐霜,转载请注明出处。【未经授权禁止转载】成reconciler层所有工作。Rec转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。onciler的主要工作是调用组件生命周未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net期,这里可不指组件生命周期函数,reac转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。t官方开源了react-reconciler这个库,你可以基于它了解react组件真原创内容,盗版必究。【原创不易,请尊重版权】正的生命周期。在生命周期的基础上,fib【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】er构建了一套非常巧妙的时间切片算法,让【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】reconciler处于一种更加灵活且掌本文作者:唐霜,转载请注明出处。【未经授权禁止转载】控性更强的调度中,整个调度交由scheduler来进行任务分配,实现了任务的优先级,这些【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net优先级可划分为:
【本文受版权保护】未经授权,禁止复制转载。- synchronous,与之前的Stac著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。k Reconciler操作一样,同步执【未经授权禁止转载】【原创内容,转载请注明出处】行 未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】
- task,在next tick之前执行 【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】
- animation,下一帧之前执行 本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。
- high,在不久的将来立即执行 【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。
- low,稍微延迟执行也没关系 【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。
- offscreen,下一次render时【本文受版权保护】【关注微信公众号:wwwtangshuangnet】或scroll时才执行 【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】
基于fiber的reconciler分为【未经授权禁止转载】转载请注明出处:www.tangshuang.net两个阶段:reconciliation阶【版权所有,侵权必究】【作者:唐霜】段和commit阶段。其中commit阶著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】段的主要工作是把计算后的变更实施到真实的【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】DOM或native环境中,影响UI界面著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net的变化,因此,这个阶段是不可以中断的。而【版权所有,侵权必究】【本文受版权保护】reconciliation阶段主要工作本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。是计算、diff、找出变更(副作用),这【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】些计算大体上还是基于virtual DO【本文首发于唐霜的博客】【原创不易,请尊重版权】M的,由于它属于计算层面,所以是可以中断【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net的,react实现了巧妙的时间切片算法,本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】可以在计算时根据任务的优先级来中断当前的著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。计算,等到有空闲时间时再重新开启之前的计未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。算。基于该时间切片算法,计算被合理的划分【本文首发于唐霜的博客】转载请注明出处:www.tangshuang.net到不同时间切片,从而大幅避免了长任务所带本文版权归作者所有,未经授权不得转载。【转载请注明来源】来的卡顿现象(当然,有的情况下还是不可避转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】免,但总体而言比较少)。
【原创不易,请尊重版权】原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。常见的React性能问题与优化对策
<Some name="toniy" />
为什么Some组件的render会被反复本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】执行呢?明明name是个字符串,不会变化【未经授权禁止转载】【转载请注明来源】。这是因为react在实现代码层面,仅对【关注微信公众号:wwwtangshuangnet】【转载请注明来源】前后两次props进行了全等对比,即==【本文受版权保护】【原创内容,转载请注明出处】=,而组件每次执行到该生命周期时,pro本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。ps明显都是新创建的,虽然看上去是一样,【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】但实际上是两个对象。如果react内部实本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。现时,采用了shallowEqual,那未经授权,禁止复制转载。未经授权,禁止复制转载。就不存在这个问题了。
原创内容,盗版必究。【转载请注明来源】原创内容,盗版必究。那么怎么解决呢?既然react自己没有处【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。理,我们自己来包一个shallowEqu【原创内容,转载请注明出处】【本文首发于唐霜的博客】al的实现:
【转载请注明来源】原创内容,盗版必究。本文作者:唐霜,转载请注明出处。export const Some = React.memo(function(props) {
...
})
我们在原来的Some组件外面包了一个Re本文作者:唐霜,转载请注明出处。【作者:唐霜】act.memo,就可以让Some组件自【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。动具备props的shallowEqua本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。l判断,当组件传入的props没有变化时【本文首发于唐霜的博客】【原创内容,转载请注明出处】,组件就不需要再次渲染。
【本文受版权保护】【版权所有】唐霜 www.tangshuang.net2. 接收属性都相同的prop对象,怎么未经授权,禁止复制转载。【作者:唐霜】避免重新渲染?
本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。很多情况下,我们使用组件时会直接传入一个转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。对象,例如:
【转载请注明来源】本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】<Some info={{ name: 'toniy' }} />
这种用法会导致info每次都是一个新对象【版权所有,侵权必究】【未经授权禁止转载】,组件每次都会重新渲染,有没有什么办法避本文版权归作者所有,未经授权不得转载。【本文受版权保护】免呢?
本文作者:唐霜,转载请注明出处。【转载请注明来源】export const Some = React.memo(function(props) { ... }, (nextProps, prevProps) => {
return nextProps.info.name === prevProps.info.name
})
React.memo的第二个参数返回bo【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】olean,如果为true表示前后两次是【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。相等的,相当于告诉react,这次组件不【作者:唐霜】【原创不易,请尊重版权】需要被重新渲染。
【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】3. 避免回调函数引起重新渲染
本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。原创内容,盗版必究。转载请注明出处:www.tangshuang.net对于onClick等事件回调,如果直接传本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net入函数,也是被认为是一个全新的值,因此,本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net用memo也无济于事。很多建议是通过us【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】eCallback或useEvent包裹本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。回调函数,但我认为可以在组件内自己消化。
未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。export const Some = React.memo(function(props) { ... }, (nextProps, prevProps) => {
return nextProps.onClick === prevProps.onClick || nextProps.onClick + '' === prevProps.onClick + ''
})
我们自己在组件内做好了优化,对于用该组件未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。的人而言也是省心省力的。
本文作者:唐霜,转载请注明出处。【作者:唐霜】本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net4. 为什么组件的渲染似乎进入了死循环?
【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。【本文受版权保护】组件渲染开始后,浏览器假死,一直无法显示【本文首发于唐霜的博客】【原创不易,请尊重版权】界面。很有可能是因为变更state导致的【转载请注明来源】【关注微信公众号:wwwtangshuangnet】无限触发更新导致的死循环问题。可能的两种【版权所有,侵权必究】【原创内容,转载请注明出处】情况,一是在componentDidMo【原创内容,转载请注明出处】原创内容,盗版必究。unt/componentDidUpda本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.nette中调用setState,二是在use【转载请注明来源】本文作者:唐霜,转载请注明出处。Effect中调用setState。当组【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。件完成渲染之后,你随即马上又调用setS【本文首发于唐霜的博客】未经授权,禁止复制转载。tate来触发了组件的更新,而由于没有控【关注微信公众号:wwwtangshuangnet】【未经授权禁止转载】制好,导致这一更新动作不断的被触发。
本文版权归作者所有,未经授权不得转载。【版权所有,侵权必究】【作者:唐霜】【作者:唐霜】此时,你要检查setState是在什么情著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】况下被调用。一方面可以通过shouldC著作权归作者所有,禁止商业用途转载。【原创内容,转载请注明出处】omponentUpdate来控制,再什【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】么状态下可以更新组件,另一方面在setS转载请注明出处:www.tangshuang.net【未经授权禁止转载】tate之前做好if判断。
【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。【作者:唐霜】【版权所有】唐霜 www.tangshuang.net基于依赖收集的最小化更新技术
这是我独家总结的一种react组件优化技原创内容,盗版必究。【作者:唐霜】术,你可以在《一种基于依赖收集的最小化更新组件技术》一文中阅读详细的思考过程。简单讲,我们本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】的组件往往并不需要在每次更新时被更新。这【原创内容,转载请注明出处】【原创内容,转载请注明出处】话可能有点绕,让我们回去了解一下reac【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】t的渲染机制,你会发现,react组件是转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net否需要被重新渲染,是由react作为驱动原创内容,盗版必究。未经授权,禁止复制转载。程序,内部reconciler调配的,而转载请注明出处:www.tangshuang.net【未经授权禁止转载】react在实现时,无论组件内部怎么设计【关注微信公众号:wwwtangshuangnet】未经授权,禁止复制转载。,它都会按照自己的设计来重新运行组件的r【转载请注明来源】未经授权,禁止复制转载。ender。这就导致组件其实根本不需要r未经授权,禁止复制转载。原创内容,盗版必究。ender,但是还是被render了。此本文版权归作者所有,未经授权不得转载。【未经授权禁止转载】时,我们可以把组件从这种机制中脱离出来。本文版权归作者所有,未经授权不得转载。【本文受版权保护】通过最小化更新技术,我们可以让组件在默认未经授权,禁止复制转载。【本文首发于唐霜的博客】状态下不更新,只在内部使用到的值发生变化【本文首发于唐霜的博客】原创内容,盗版必究。的时候更新,从而做到定点靶向更新,实现最本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。小化更新。
【本文受版权保护】【原创不易,请尊重版权】React SSR
SSR技术主要针对首屏渲染,我们大部分前著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】端应用都是通过构建大包进行发布,这就会导【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】致应用首屏必须等到加载完对应的脚本,并执【版权所有,侵权必究】著作权归作者所有,禁止商业用途转载。行之后,才会由react生成对应的DOM【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net结构,并挂载到页面上。SSR技术则主要解【作者:唐霜】【访问 www.tangshuang.net 获取更多精彩内容】决这一问题,简单讲,react的Virt【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。ual DOM可以在服务端运算出用于渲染原创内容,盗版必究。【本文首发于唐霜的博客】的HTML字符串,从而让页面打开时,就已【关注微信公众号:wwwtangshuangnet】【作者:唐霜】经具备了可渲染的html内容,用户也就能著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。立即看到页面的内容。在这同时,页面还会继【本文受版权保护】【版权所有】唐霜 www.tangshuang.net续加载对应的脚本,脚本完成之后,页面就恢未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。复了正常的SPA效果。
【关注微信公众号:wwwtangshuangnet】【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】【原创内容,转载请注明出处】不过SSR受限于后端运维的条件限制,并不转载请注明出处:www.tangshuang.net【未经授权禁止转载】适合所有前端场景。大部分情况下,我们可以【作者:唐霜】【关注微信公众号:wwwtangshuangnet】结合serverless来运行ssr程序【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】,同时在策略上做一些降级方案,保证ssr【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net运行出错或后端机器卡顿时,可以退回到普通【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】的CSR(客户端渲染)模式。
【本文受版权保护】【版权所有,侵权必究】转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】问鼎中原:Vue性能优化
本文版权归作者所有,未经授权不得转载。【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】“我不服,这个荫世年纪轻轻,论辈分,给我未经授权,禁止复制转载。【版权所有,侵权必究】提鞋都不够,有什么资格担任武林盟主?”“著作权归作者所有,禁止商业用途转载。【本文受版权保护】对!我关山派也不同意”……西无一的推荐,【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。反倒引来不少反对之声。“各位,请听我西某【原创内容,转载请注明出处】【本文首发于唐霜的博客】一言。如今世道混乱,中原武林若不齐心协力著作权归作者所有,禁止商业用途转载。【关注微信公众号:wwwtangshuangnet】,铲除鬼窍团余孽,就会让武林威信扫地,其原创内容,盗版必究。本文作者:唐霜,转载请注明出处。他恶势力蠢蠢欲动,届时天下混战,天下百姓【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。受苦,各位所在门派也必然将受到威胁,只有【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】结盟共济,才能度过此间乱局,还天下太平,本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】而如今乱世,皆因这位英侠而起,正因其心怀【本文受版权保护】著作权归作者所有,禁止商业用途转载。天下,才能数十年意志不变,最终斩杀恶贼,本文作者:唐霜,转载请注明出处。未经授权,禁止复制转载。天下若他做不了盟主,便无人做得了这盟主。【未经授权禁止转载】本文作者:唐霜,转载请注明出处。”……看来,还是得由功夫来决定盟主之位。【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net“无一兄,虽然我无意盟主之名,但今日必要【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。拿下这盟主之位,结束这世间纷争,望无一兄转载请注明出处:www.tangshuang.net【未经授权禁止转载】承让。”“荫兄自当有这能力,昔日一招便可转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】接我绝学,望整个江湖,唯有你能做到。”“著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】好,那就看我如何去争这盟主位。”说罢,我【转载请注明来源】未经授权,禁止复制转载。便快步走上擂台,说到“今日在下无意盟主之未经授权,禁止复制转载。未经授权,禁止复制转载。名,但天下己任,望众位大侠成全,若有不服原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。,可上台挑战。”“嗖!呼!”一声飞来,不【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net知哪个门派上来一人,“我乃四川青城派掌门【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】,今日向这位少侠挑战。”说罢,一个作揖,【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。便携一股热气飞涌而来。这位掌门虽功力深厚原创内容,盗版必究。【本文首发于唐霜的博客】,但并无杀气,我只用两招,便化解了他的夺转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。命索喉,令得他有些气急败坏,不得不抱拳认【原创不易,请尊重版权】【本文受版权保护】输。……“既有如此不满,在场门派皆可同时原创内容,盗版必究。未经授权,禁止复制转载。上来,在下可一人敌。”一时间,十余人便冲著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。上来,各个狠辣不留情面,但在我看来,其境未经授权,禁止复制转载。【版权所有,侵权必究】界亦不过如此。若在缠斗下去,怕是紧都分不【关注微信公众号:wwwtangshuangnet】【本文受版权保护】出胜负来。“轰!”只闻得空气中一阵闷响,原创内容,盗版必究。【原创不易,请尊重版权】在场之人,全都被镇住,动弹不得。“各位,【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。世间武功再高,亦有界限,今日,让众位开开【作者:唐霜】本文作者:唐霜,转载请注明出处。眼界。”说罢,我集自然神气,向空中发出一【本文受版权保护】【本文首发于唐霜的博客】束气脉,身体与宇宙联通。被镇住之人动弹不【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net得,只可看见。天地间若静止,白云消散,蓝【未经授权禁止转载】原创内容,盗版必究。天被拨开一到裂口,缓缓展开来,漏出宇宙的【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net本来面目。黑色的背景深邃如幕,繁星若璀璨【作者:唐霜】【作者:唐霜】宝石散发着耀眼光辉……带我收回气脉,停止【本文受版权保护】【原创不易,请尊重版权】运气,一切恢复如初,众人却仍伫立原地,对【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。适才所见惊得目瞪口呆,若有所思,忘却了当【原创不易,请尊重版权】未经授权,禁止复制转载。下。……“荫少侠无愧盟主!荫少侠无愧盟主【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net!”……
著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。
Vue作为国人喜爱的一款前端框架,应用范【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。围也很广泛。同时,与react相比,vu本文版权归作者所有,未经授权不得转载。【本文受版权保护】e原生做了一些性能优化方面的工作,避免大【版权所有,侵权必究】【原创内容,转载请注明出处】部分开发者反复的去处理某些性能问题。但在转载请注明出处:www.tangshuang.net本文作者:唐霜,转载请注明出处。vue使用过程中,偶尔我们也会遇到一些情著作权归作者所有,禁止商业用途转载。【作者:唐霜】况。
未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】本文版权归作者所有,未经授权不得转载。Vue响应式原理
和react等框架不同,vue的编程特点转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。是通过直接修改数据来触发界面的重新渲染。【转载请注明来源】【本文首发于唐霜的博客】这一思想来源于angularjs,但是却原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】比angularjs更加优秀,因为它采用【本文受版权保护】未经授权,禁止复制转载。了数据拦截的响应式原理,而抛弃了angu【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.netlarjs的脏检查机制。在vue2版本中【原创不易,请尊重版权】【版权所有,侵权必究】,它通过Object.definePro著作权归作者所有,禁止商业用途转载。【作者:唐霜】perty来拦截数据,当在代码中直接修改【作者:唐霜】本文作者:唐霜,转载请注明出处。数据(属性)时,会通过该属性的sette转载请注明出处:www.tangshuang.net原创内容,盗版必究。r修改其值,在setter中,vue内置【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net了一个触发界面更新的任务,等到下一帧时,【原创不易,请尊重版权】【原创不易,请尊重版权】这些更新任务就会被执行,从而带来界面的更【转载请注明来源】转载请注明出处:www.tangshuang.net新。在vue3版本中,它用Proxy替代【版权所有,侵权必究】【关注微信公众号:wwwtangshuangnet】了Object.defineProper原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.netty,因为Proxy可以更好的处理del【原创不易,请尊重版权】原创内容,盗版必究。ete操作和数组的各种操作的拦截,但在拦本文作者:唐霜,转载请注明出处。【本文受版权保护】截中插入重新渲染的任务仍然是其底层逻辑。
转载请注明出处:www.tangshuang.net【作者:唐霜】【关注微信公众号:wwwtangshuangnet】也正是因为这种拦截的机制,让vue在性能本文作者:唐霜,转载请注明出处。【未经授权禁止转载】上,如果不做任何优化,会有比react性本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。能更好的表现。因为这种拦截具有依赖收集的未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。可能性(vue内部也是这么做的),也就意转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】味着,只需要对依赖的变化进行响应即可,其本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。他变化,即使是被拦截的数据,也无需对它进【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】行响应。和react相比,react的重【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。新渲染是全量的,一旦触发了更新,那么就是著作权归作者所有,禁止商业用途转载。转载请注明出处:www.tangshuang.net整个组件连带其子组件一起更新,而vue因转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net为是根据哪一个数据变化来进行更新,所以在【作者:唐霜】【关注微信公众号:wwwtangshuangnet】更新时具有更细粒度的把控,结合编译工具,【原创内容,转载请注明出处】【原创不易,请尊重版权】可以做到只更新对数据有依赖的节点,这就使【未经授权禁止转载】【转载请注明来源】得其性能有不错的表现。但是,也正是由于它【原创内容,转载请注明出处】【未经授权禁止转载】基于数据拦截机制,也带来了一些问题,一个原创内容,盗版必究。【原创内容,转载请注明出处】问题是,当遇到一些无法被拦截的数据,例如原创内容,盗版必究。【本文受版权保护】一些类的实例对象,就无法正确响应其修改。
未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。常见的Vue性能问题
1. 为什么修改某个数据时界面没有变动,未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net却出现了卡顿?
著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。【未经授权禁止转载】【转载请注明来源】由于数据拦截机制,会导致有些情况下,一些本文版权归作者所有,未经授权不得转载。【作者:唐霜】细节的修改我本不想带来重新渲染,但是由于【版权所有】唐霜 www.tangshuang.net【原创内容,转载请注明出处】其内部任务的存在,会出现大量的计算,占用【作者:唐霜】本文版权归作者所有,未经授权不得转载。CPU,而且vue不像react实现了时本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.net间切片,它就没有办法处理这种常见的CPU未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】被大量占用的情况。针对这种情况,我们只需【原创不易,请尊重版权】【原创内容,转载请注明出处】要让vue不要去拦截这类数据,即让这个数原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】据不要具备响应式能力。我们可以用Obje本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。ct.defineProperty对数据【未经授权禁止转载】本文版权归作者所有,未经授权不得转载。提前进行定义,将其configurabl本文版权归作者所有,未经授权不得转载。本文作者:唐霜,转载请注明出处。e设置为false,那么vue就无法通过原创内容,盗版必究。本文作者:唐霜,转载请注明出处。Object.definePropert【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。y来拦截该数据。
【未经授权禁止转载】本文作者:唐霜,转载请注明出处。2. 为什么某个页面加载完数据之后,出现【作者:唐霜】著作权归作者所有,禁止商业用途转载。了严重卡顿?
【本文首发于唐霜的博客】著作权归作者所有,禁止商业用途转载。因为可能是你的后端接口返回了一个巨大的数【版权所有,侵权必究】【版权所有,侵权必究】据,而你在往vue里面塞入该数据时,vu【本文首发于唐霜的博客】【未经授权禁止转载】e会对该数据进行初始化拦截处理,而由于数本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。据太大,导致该过程消耗了大量的计算。解决未经授权,禁止复制转载。【原创内容,转载请注明出处】办法是用Object.freeze把该数著作权归作者所有,禁止商业用途转载。【作者:唐霜】据进行冻结,经过冻结后的数据不会被vue未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net拦截,这样就直接跳过了这个初始化拦截处理【未经授权禁止转载】【转载请注明来源】阶段,可以快速展示你的数据。
转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】本文版权归作者所有,未经授权不得转载。【作者:唐霜】3. 大列表、大表格卡顿?
著作权归作者所有,禁止商业用途转载。【转载请注明来源】这个不是vue的问题,参见前面“虚拟视口【原创内容,转载请注明出处】本文作者:唐霜,转载请注明出处。技术”一节。
【本文首发于唐霜的博客】本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】笑傲江湖:其他框架性能亮点
【转载请注明来源】著作权归作者所有,禁止商业用途转载。【转载请注明来源】【原创不易,请尊重版权】追到峡谷,两岸峭壁如岸,抬头只见的一线天本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。,视线昏暗,风寒如沁。“轰!”闻的一声巨【原创内容,转载请注明出处】【本文首发于唐霜的博客】响,“报!!盟主,我们中埋伏了,前路夹谷著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】被这帮恶人炸毁堵住,刚才后路也被炸,如今本文版权归作者所有,未经授权不得转载。著作权归作者所有,禁止商业用途转载。我们被困在这峡谷内,瓮中之鳖了。”没曾想本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】,这帮余孽竟然还会如此设计。“哈哈哈!!未经授权,禁止复制转载。【转载请注明来源】!中原武林,今日半数在此,今日之后,就没原创内容,盗版必究。【作者:唐霜】有中原武林了。”正直众人纳闷时,峡谷顶上【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】出现了黑压压的一群丑陋的余孽鬼,各个手中【作者:唐霜】【版权所有,侵权必究】持弓箭,另有石药车。“啊!!这可如何是好【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】!!我嵋山派莫非今日要灭门于此?”人群里未经授权,禁止复制转载。【本文首发于唐霜的博客】开始轰动,有的慌乱,有的后悔,有的惧怕…【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net…“秋山若有仙人在,明月新霜宁如嫦。”我【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】拿出秀若送我的长箫,吹一曲《明月清风》安【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。然凝神。“大家莫慌,待我半柱香。”顷刻之【版权所有,侵权必究】转载请注明出处:www.tangshuang.net间,我已飞冲到峡谷顶崖,擒住那团伙的首领【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net。哪些恶兽冲涌上来,我只挥一阵衣袖,便将【转载请注明来源】【本文受版权保护】所有反抗者震晕倒下。未等那些石药开始被倒【转载请注明来源】转载请注明出处:www.tangshuang.net出,那些人就已经倒下了。
本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】
除了react和vue之外,其他一些框架原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net在性能方面也有自己的一些亮点,这些亮点让【访问 www.tangshuang.net 获取更多精彩内容】【转载请注明来源】这些框架在竞争激烈的前端领域独树一帜。
【作者:唐霜】原创内容,盗版必究。Svelte为什么快?
2021年,svelte被评为react【作者:唐霜】原创内容,盗版必究。、vue、angular之后的第四大前端原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。框架,主要原因在于它打破了react、v【本文首发于唐霜的博客】原创内容,盗版必究。ue一类框架的范式,没有一点和这些框架有转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。相似的地方,相反,svelte大火之后,转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】vue马上跟进,开始抄作业。在一些评测中原创内容,盗版必究。【本文首发于唐霜的博客】,我们也可以看到svelte在性能上有不著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】错的表现,它之所以快,主要有两个原因:
本文作者:唐霜,转载请注明出处。【作者:唐霜】本文版权归作者所有,未经授权不得转载。- svelte完全基于编译,它没有自己的运本文版权归作者所有,未经授权不得转载。【转载请注明来源】行时,虽然在编译结果中也存在一些运行时代【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】码,但这些代码不足以称为一个框架,它完全【原创内容,转载请注明出处】【未经授权禁止转载】通过编译来理解代码要做什么操作,并编译为【作者:唐霜】【版权所有】唐霜 www.tangshuang.net执行该操作的代码,因此,svelte程序转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】在运行的时候,不像vue或react,会本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net有那么复杂的生命周期,也没有复杂的dif著作权归作者所有,禁止商业用途转载。【本文受版权保护】f->patch等过程,因此就更快 【原创内容,转载请注明出处】【版权所有,侵权必究】【作者:唐霜】【本文首发于唐霜的博客】
- svelte抛弃了Virtual DOM【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】,转而直接对DOM进行操作,基于上面一条【未经授权禁止转载】【未经授权禁止转载】原因,svelte没有像vue或reac【未经授权禁止转载】【未经授权禁止转载】t一样,构建一套virtual dom,本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。由于构建virtual dom需要占用大【原创内容,转载请注明出处】本文版权归作者所有,未经授权不得转载。量内存,同时还要基于virtual do【访问 www.tangshuang.net 获取更多精彩内容】本文版权归作者所有,未经授权不得转载。m做大量运算,所以实际上是比较低性能的,【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。由于没有virtual dom这一整套机著作权归作者所有,禁止商业用途转载。【本文首发于唐霜的博客】制,svelte直接操作DOM,而且是一【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。针见血的操作依赖变量的DOM节点,所以直【转载请注明来源】【本文受版权保护】捣黄龙搬的效率带来更高的性能 本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】
但是,svelte也存在一定的问题,由于【未经授权禁止转载】【版权所有,侵权必究】它没有自己的运行时,导致每一个组件编译之【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】后,都有大量相同或相似的运行时代码,这也【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。就导致最终打包之后,代码体积可能比vue本文版权归作者所有,未经授权不得转载。【转载请注明来源】或react程序要更大。
【转载请注明来源】【作者:唐霜】Solid为什么快?
solidjs是2021年火的一个框架,【转载请注明来源】著作权归作者所有,禁止商业用途转载。它身上集合了svelte的编译和无Vir原创内容,盗版必究。【版权所有,侵权必究】tual DOM、react的语法、vu未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。e的响应式原理等特点,这让它在前端框架届【本文首发于唐霜的博客】未经授权,禁止复制转载。独树一帜。它之所以快,其实和svelte【作者:唐霜】未经授权,禁止复制转载。有相同的原因,虽然写solid程序有点像本文作者:唐霜,转载请注明出处。【作者:唐霜】写react,但是实际上它和react在【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。思想上完全不同,可以说是只借鉴了reac【原创不易,请尊重版权】转载请注明出处:www.tangshuang.nett的语法,其他的全部是svelte和vu未经授权,禁止复制转载。【访问 www.tangshuang.net 获取更多精彩内容】e,例如它的通过类似vue一样的reac【转载请注明来源】未经授权,禁止复制转载。tive机制来实现界面的重新渲染,它采用转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。了svelte的编译时策略,以及无Vir转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】utal DOM直接定点更新DOM节点的未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net优化等等。
本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】【作者:唐霜】sfcjs为什么快?
sfcjs是我写的一个非常小的框架,在大【原创不易,请尊重版权】【原创不易,请尊重版权】部分情况下,你无需用nodejs来搭建一转载请注明出处:www.tangshuang.net原创内容,盗版必究。套编译环境,它直接在浏览器端启动了一个w未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.netorker线程来进行编译,通过这个策略,【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。它充分利用了客户端的资源,以及worke【版权所有,侵权必究】【原创内容,转载请注明出处】r线程不干扰主线程的计算,同时基于AMD本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】的加载策略,在必要的时候才拉取组件代码进【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】行编译,从而让整个体验非常友好(起码在加【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。载、编译时不会出现卡顿现象)。而且sfc【本文受版权保护】原创内容,盗版必究。js也走了抛弃virtual DOM的路【关注微信公众号:wwwtangshuangnet】【版权所有,侵权必究】,通过对DOM节点的定点更新,通过依赖收本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。集,只有当DOM节点所依赖的变量发生变化本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net时才会更新节点,这样当然就比基于virt【本文受版权保护】本文版权归作者所有,未经授权不得转载。ual DOM的复杂计算效率更高。
【本文受版权保护】【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】行侠仗义:Webpack构建性能优化
未经授权,禁止复制转载。【原创不易,请尊重版权】“荫哥,如今天下已经太平,你想做什么?”转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。“云游天下,行侠仗义。”“好,我陪你。”原创内容,盗版必究。【本文首发于唐霜的博客】飞阳如隙,回首我此生,楞过、苦过、狂过、本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。惨过、耀过,如今来看,都是命运。我之坚信著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。、动摇、坚持,铸就我今立于此封顶,纵乱世【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。纷涌,于我乃清风拂发,俯览众生,有悲有喜【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.net,一切皆历便可放下,或许能做些利众生的事【本文首发于唐霜的博客】【原创不易,请尊重版权】。
【未经授权禁止转载】【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。
Webpack作为现代前端重要的基础设施未经授权,禁止复制转载。【作者:唐霜】,对于打包构建有非常好的支持。但是,作为转载请注明出处:www.tangshuang.net【未经授权禁止转载】开发构建工具,它在性能上却并不如新出现的【版权所有,侵权必究】【版权所有,侵权必究】一些工具,这使得它饱受诟病。我们可以通过【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。有些手段来优化webpack构建性能,从【转载请注明来源】【转载请注明来源】而在开发或构建时拥有更好的开发体验。
【本文受版权保护】未经授权,禁止复制转载。Webpack构建原理
虽然webpack的功能目标很单一,即把【本文受版权保护】本文版权归作者所有,未经授权不得转载。一堆代码打包后产生出一个可用的代码(或几未经授权,禁止复制转载。【原创不易,请尊重版权】个代码文件),但是,它的架构却极为复杂,转载请注明出处:www.tangshuang.net【本文受版权保护】不是一般初学者可以掌握的。简单讲,web本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.netpack是通过3个方面的体系实现其构建目【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net标的,分别是:Compilition、L本文版权归作者所有,未经授权不得转载。转载请注明出处:www.tangshuang.netoader、Plugin。
【本文受版权保护】【原创不易,请尊重版权】未经授权,禁止复制转载。其中Compilition是其最核心的部【版权所有】唐霜 www.tangshuang.net【转载请注明来源】分,它完成了一个机器的核心设计,即完成内著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】容转换+资源合并的能力,包含三个阶段:初【本文受版权保护】【原创不易,请尊重版权】始化阶段,构建阶段,生成阶段。其中,构建著作权归作者所有,禁止商业用途转载。【转载请注明来源】阶段又是重中之重,这个过程在我看来,本质【原创不易,请尊重版权】本文版权归作者所有,未经授权不得转载。上就是一个编译过程,只不过它的编译不是把【版权所有,侵权必究】未经授权,禁止复制转载。一份代码转化为另一份,而是把一组代码转化著作权归作者所有,禁止商业用途转载。【转载请注明来源】为另外一组。它的构建大致如下:
【本文受版权保护】原创内容,盗版必究。- 创建Module 原创内容,盗版必究。【未经授权禁止转载】【本文受版权保护】
- runLoaders 【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。转载请注明出处:www.tangshuang.net
- 用acorn讲js解析为AST 原创内容,盗版必究。【访问 www.tangshuang.net 获取更多精彩内容】
- 遍历AST,过程中还会收集依赖 本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net
- 处理依赖,创建依赖树 【转载请注明来源】转载请注明出处:www.tangshuang.net【转载请注明来源】
- 如果过程中通过插件等Module中新增了【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】依赖,回流到第一步 未经授权,禁止复制转载。著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。
- 如此循环往复,知道所有依赖都解析完毕 【转载请注明来源】【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。
依赖树是webpack构建阶段的目标,后本文版权归作者所有,未经授权不得转载。【作者:唐霜】面的生成阶段则是基于该依赖树生成最终的c【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】hunks。而在生成依赖树之前或过程中,转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。它会执行整个构建中的无数(200多个)钩【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net子,这些钩子可以被插件挂载,从而影响整个【访问 www.tangshuang.net 获取更多精彩内容】【本文首发于唐霜的博客】构建流,比如插件可以加入新的依赖、替换依【转载请注明来源】【原创不易,请尊重版权】赖等等。在构建过程中,webpack会把【原创不易,请尊重版权】【原创内容,转载请注明出处】每一个import/require认为是【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net在引入一个Module,至于这个Modu【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。le真正的文件类型它并不关心,因为它会把原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net这个Module的识别交给Loaders【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net去处理(当然,它默认可以识别js这种mo【访问 www.tangshuang.net 获取更多精彩内容】【作者:唐霜】dule),而一个loader也可以在返【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。回的结果中增加依赖,这就导致webpac未经授权,禁止复制转载。原创内容,盗版必究。k的构建过程会出现循环往复的过程,当然,【原创内容,转载请注明出处】【本文受版权保护】你也可以说这是它先进的地方。
原创内容,盗版必究。【未经授权禁止转载】原创内容,盗版必究。由于篇幅限制,我们只要掌握webpack本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。三大体系是如何协作的,就可以大致了解we【本文受版权保护】【关注微信公众号:wwwtangshuangnet】bpack的构建原理。你也可以阅读这篇文章,了解更加详细的webpack构建原理。
【版权所有,侵权必究】【本文受版权保护】【转载请注明来源】【作者:唐霜】Webpack常见性能问题与优化技巧
通过上述原理,你可以发现,webpack著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。的整个构建链路是很长的,而且它每一个阶段【版权所有,侵权必究】原创内容,盗版必究。都需要执行大量计算,甚至还会循环往复的执【原创内容,转载请注明出处】【原创不易,请尊重版权】行,所以性能上肯定好不到哪里去。但是,C转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。ompilition是我们无法修改的,它原创内容,盗版必究。转载请注明出处:www.tangshuang.net是webpack的核心,除非我们自己fo【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】rk一份webpack的源码,定制一个自本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。己的webpack。那么,能够优化的,就【未经授权禁止转载】【版权所有】唐霜 www.tangshuang.net是通过插件、Loader的优化来提升性能【转载请注明来源】【转载请注明来源】了。
转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。合理优化Loaders
我们知道webpack把每一个文件都当做本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】Module对待,这也意味着,每一种文件著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。类型,都需要一个(或多个)Loader来本文作者:唐霜,转载请注明出处。【转载请注明来源】识别,并转化为ESModule的形式,比【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】如图片要转化为 export default 'http://xxx/a.jpg' 这样的形式。但是,有些loader却会著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】做多余的事,比如我们只是想得到一个url著作权归作者所有,禁止商业用途转载。【转载请注明来源】,但是它却去计算尺寸大小颜色等,浪费大量【本文首发于唐霜的博客】【版权所有,侵权必究】计算资源。一个典型的例子就是,不少开发者原创内容,盗版必究。【本文首发于唐霜的博客】不管什么情况下,管他三七二十一,都把ba【作者:唐霜】本文作者:唐霜,转载请注明出处。bel-loader加上,而且给babe本文版权归作者所有,未经授权不得转载。原创内容,盗版必究。l配置了一大堆presets,这就导致j著作权归作者所有,禁止商业用途转载。【本文受版权保护】s文件不仅要过babel的编译,还要过w【访问 www.tangshuang.net 获取更多精彩内容】【访问 www.tangshuang.net 获取更多精彩内容】ebpack的解析,当然更消耗性能。其实本文版权归作者所有,未经授权不得转载。【转载请注明来源】,在某些场景下,我们可以不需要babel著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。-preset-env之类的babel插本文版权归作者所有,未经授权不得转载。【转载请注明来源】件或preset,只需要加几个用于识别特著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net定的webpack无法识别的语法的插件即【本文受版权保护】【版权所有,侵权必究】可,甚至一些情况下,如果我们写的代码是标本文版权归作者所有,未经授权不得转载。【原创不易,请尊重版权】准代码,不包含ESNext,那么不使用b【原创内容,转载请注明出处】著作权归作者所有,禁止商业用途转载。abel-loader也完全没有问题,毕著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。竟标准ES是浏览器支持的。
启用多线程
我们知道webpack是基于js开发的,原创内容,盗版必究。著作权归作者所有,禁止商业用途转载。js是单线程的,所以即使两个毫不相干的l原创内容,盗版必究。【作者:唐霜】oader也只能前后排队等待处理。我们可【转载请注明来源】本文作者:唐霜,转载请注明出处。以利用happypack插件来启用多线程【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net,让某些不需要串行的任务可以并行执行,这本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】样就可以让某些loader可以同时运行,【转载请注明来源】本文版权归作者所有,未经授权不得转载。进而提升其性能。
【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】【本文首发于唐霜的博客】【关注微信公众号:wwwtangshuangnet】使用DLL
动态链接库(DLL)是windows系统【原创内容,转载请注明出处】原创内容,盗版必究。的一种方案,你可以利用webpack内置【转载请注明来源】本文版权归作者所有,未经授权不得转载。的DllPlugin插件,把一些固定不变【转载请注明来源】本文版权归作者所有,未经授权不得转载。的依赖,如放在node_modules目【本文受版权保护】著作权归作者所有,禁止商业用途转载。录下的模块文件的代码,打包的dll文件中【本文受版权保护】原创内容,盗版必究。,然后在编译时,基于dll的生成结果,w著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】ebpack就不会再去打包这些依赖,由于著作权归作者所有,禁止商业用途转载。本文作者:唐霜,转载请注明出处。减少了对这些依赖代码的整套构建流,所以整【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。体的工作量就少了很多,性能也就提升了上来本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。。
本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】未经授权,禁止复制转载。启用缓存
webpack5提高了更高水平的缓存机制转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net,新版本的webpack为了在性能上有所转载请注明出处:www.tangshuang.net【未经授权禁止转载】突破,设计了一种复杂的缓存策略,它把一个著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。Compilition整条链路都给分任务本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。的缓存起来,每一个loader或plug【未经授权禁止转载】【转载请注明来源】in的执行,在每一个阶段的结果,都给缓存【本文首发于唐霜的博客】【本文首发于唐霜的博客】了一遍,当第二次进行编译的时候,如果它基著作权归作者所有,禁止商业用途转载。【本文受版权保护】于缓存检查到某个文件发生了变化,那么它不转载请注明出处:www.tangshuang.net【关注微信公众号:wwwtangshuangnet】会去管其他文件的所有编译过程,而只会动当【转载请注明来源】未经授权,禁止复制转载。前文件的编译链,其他文件的所有编译结果将本文作者:唐霜,转载请注明出处。原创内容,盗版必究。被直接使用。这一策略从理论上,显得非常高【作者:唐霜】本文版权归作者所有,未经授权不得转载。效,可以说是我所见过的缓存策略里面做的最本文版权归作者所有,未经授权不得转载。未经授权,禁止复制转载。彻底的。但是由于它要缓存的内容太多了,导【未经授权禁止转载】原创内容,盗版必究。致它的缓存文件特别大,动不动就上G了。而【作者:唐霜】【原创内容,转载请注明出处】且另外一个方面,它的Compilitio【本文首发于唐霜的博客】【版权所有,侵权必究】n链路实在是太长了,即使其他所有文件的编【原创不易,请尊重版权】【转载请注明来源】译过程结果都无需重新生成,但是当前文件的著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】编译链路也很长,这就导致即使使用了这么高【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】级的缓存策略,webpack仍然无法做到本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net秒级构建响应。
【关注微信公众号:wwwtangshuangnet】【本文首发于唐霜的博客】【访问 www.tangshuang.net 获取更多精彩内容】让webpack打出更小的包
随着项目增长,webpack打包的体积也【原创不易,请尊重版权】【原创不易,请尊重版权】越来越大。此时,我们要考虑用户打开页面时【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】,下载代码文件所花掉的时间,因此,我们要著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】想办法,让打包体积变小,让用户更快看到界【关注微信公众号:wwwtangshuangnet】【关注微信公众号:wwwtangshuangnet】面。基于webpack,我们有如下的方案原创内容,盗版必究。【原创不易,请尊重版权】:
未经授权,禁止复制转载。原创内容,盗版必究。【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】- 使用dll 未经授权,禁止复制转载。【未经授权禁止转载】【未经授权禁止转载】转载请注明出处:www.tangshuang.net
- 自己定制策略进行chunks拆分 未经授权,禁止复制转载。【本文首发于唐霜的博客】【版权所有】唐霜 www.tangshuang.net【关注微信公众号:wwwtangshuangnet】
- 使用动态引入import() 【版权所有,侵权必究】【未经授权禁止转载】【作者:唐霜】
- 使用tree shaking能力 原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】
- 使用公共utils库,减少重复代码 转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】原创内容,盗版必究。
- 避免同一依赖的多个版本被同时打包(当然,【版权所有】唐霜 www.tangshuang.net【版权所有】唐霜 www.tangshuang.net必要的情况下不得不依赖多个版本) 【转载请注明来源】著作权归作者所有,禁止商业用途转载。
天外飞仙:热重载
【关注微信公众号:wwwtangshuangnet】【原创内容,转载请注明出处】【访问 www.tangshuang.net 获取更多精彩内容】云月轻过,黑风清凉,“秀若,你可曾在天上【转载请注明来源】本文作者:唐霜,转载请注明出处。看过世界?”“没有。”“来我带你。”我们【原创内容,转载请注明出处】【本文受版权保护】乘着夜风,飞上千尺深空,向下望来,长安整【转载请注明来源】著作权归作者所有,禁止商业用途转载。城的美景尽在眼底。若这天下太平,这盛世,本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net不正是我所愿。
【版权所有,侵权必究】本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。
热重载(Hot Module Reloa【原创不易,请尊重版权】未经授权,禁止复制转载。d, HMR)是一种在更新代码后不刷新页【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】面可以立即预览变更的技术,对于一些布局、原创内容,盗版必究。【本文首发于唐霜的博客】样式的变化,非常有必要。
本文作者:唐霜,转载请注明出处。【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。HMR的原理
热更新的本质,就是一个函数的执行效果被这未经授权,禁止复制转载。【未经授权禁止转载】个函数的拷贝的执行效果覆盖。比如我们现在【原创内容,转载请注明出处】【转载请注明来源】有一个函数 a() 在页面上输出R未经授权,禁止复制转载。本文作者:唐霜,转载请注明出处。21;a”,然后我们重新定义【版权所有】唐霜 www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】了函数 a() 在页面上输出”原创内容,盗版必究。【原创内容,转载请注明出处】;b”,那么怎么做到页面不刷【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net新而界面变化呢?运行新的 a() 就可以著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】了。
【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.netHMR的本质思路也是这样。只不过它重载的本文作者:唐霜,转载请注明出处。【作者:唐霜】不是函数,而是模块,当然,在webpac【版权所有,侵权必究】【版权所有,侵权必究】k中,一个模块实际上也被包在一个函数中。【原创不易,请尊重版权】【关注微信公众号:wwwtangshuangnet】但是如果我们脱离webpack聊HMR,【原创内容,转载请注明出处】【未经授权禁止转载】那么其本质大致相同。一般来讲,HMR需要转载请注明出处:www.tangshuang.net【未经授权禁止转载】按照如下的原理来进行:
【关注微信公众号:wwwtangshuangnet】【转载请注明来源】- 服务端:向客户端提供JS脚本,脚本具有特【本文受版权保护】【原创内容,转载请注明出处】殊性质,里面包含了一些hmr的处理代码,【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net客户端运行该JS脚本,运行后这个脚本就具本文版权归作者所有,未经授权不得转载。【原创内容,转载请注明出处】备了hmr能力 本文作者:唐霜,转载请注明出处。【原创不易,请尊重版权】【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】
- 服务端:监听文件变化,文件发生变化之后,【转载请注明来源】著作权归作者所有,禁止商业用途转载。重新进行构建,得到新的Module代码,【原创内容,转载请注明出处】【版权所有】唐霜 www.tangshuang.net这个新代码将被发送给客户端 著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。【转载请注明来源】
- 服务端:得到新代码之后,通过websoc【版权所有,侵权必究】【访问 www.tangshuang.net 获取更多精彩内容】ket向客户端告知新代码产生了,快来拿 原创内容,盗版必究。【版权所有,侵权必究】未经授权,禁止复制转载。
- 客户端:接收到服务端端websocket【本文首发于唐霜的博客】本文版权归作者所有,未经授权不得转载。消息之后,通过jsonp获得新Modul【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】e 【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】
- 客户端:从原来的模块依赖关系中,删除原始原创内容,盗版必究。原创内容,盗版必究。的模块引用,把新的Module作为替换,【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。放到原始引用的位置 著作权归作者所有,禁止商业用途转载。【访问 www.tangshuang.net 获取更多精彩内容】
- 客户端:模块间的引用是一种软引用,从而能著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。够保证模块引用发生变化时,其他模块再次获本文版权归作者所有,未经授权不得转载。【本文首发于唐霜的博客】得该模块的接口时,获得的是新模块的接口 【作者:唐霜】转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。
- 客户端:调用update方法,重新执行引【作者:唐霜】【本文受版权保护】用新Module的代码,从而使界面更新。【作者:唐霜】未经授权,禁止复制转载。这个update过程,可能需要开发者自己【版权所有】唐霜 www.tangshuang.net【未经授权禁止转载】写代码来确定自己要调用哪个方法来更新界面未经授权,禁止复制转载。【原创内容,转载请注明出处】。 【转载请注明来源】原创内容,盗版必究。
虽然原理看上去很简单,但是要实现这一整套本文版权归作者所有,未经授权不得转载。【版权所有】唐霜 www.tangshuang.net逻辑,且保证不出错,还是需要非常强大的编【未经授权禁止转载】【访问 www.tangshuang.net 获取更多精彩内容】程能力才能做到。
【版权所有】唐霜 www.tangshuang.net【作者:唐霜】转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net无论如何,通过HMR,我们可以让用户看到【原创不易,请尊重版权】【访问 www.tangshuang.net 获取更多精彩内容】的界面可以快速更新到最新代码想要得到的效转载请注明出处:www.tangshuang.net本文版权归作者所有,未经授权不得转载。果,这对于我们开发者而言,在开发调试阶段【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】可以说是一把锋利的宝剑,为我们节省非常多著作权归作者所有,禁止商业用途转载。原创内容,盗版必究。时间。
著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】HMR状态丢失问题
如果你理解了 a() 被重载后执行来覆盖原创内容,盗版必究。【原创内容,转载请注明出处】界面的本质,那么也就会发现,假如某些东西【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net我们依赖的是 a() 内部的状态,那么 转载请注明出处:www.tangshuang.net著作权归作者所有,禁止商业用途转载。a() 被重载执行之后,原来的状态就会丢【作者:唐霜】未经授权,禁止复制转载。失。我们来举个例子:
【原创内容,转载请注明出处】转载请注明出处:www.tangshuang.net【转载请注明来源】function a() {
let state = { value: 1 }
html`
<span>${state}</span>
<input :bind=${state} />
`
}
上面的代码是基于一种html标签函数实现【版权所有,侵权必究】【版权所有】唐霜 www.tangshuang.net的前端渲染能力,当在输入框中输入数据时,【原创内容,转载请注明出处】未经授权,禁止复制转载。它会更新state,并且带来界面的变化。【版权所有】唐霜 www.tangshuang.net【本文首发于唐霜的博客】可是现在如果我们重载了 a() 并重新运【原创不易,请尊重版权】【转载请注明来源】行它:
未经授权,禁止复制转载。【本文受版权保护】本文版权归作者所有,未经授权不得转载。function a() {
let state = { value: 1 }
html`
<span>now: ${state}</span>
<input :bind=${state} />
`
}
我们就会发现,a() 运行后,state转载请注明出处:www.tangshuang.net转载请注明出处:www.tangshuang.net 回到了1,这也就导致now: 后面是1未经授权,禁止复制转载。【关注微信公众号:wwwtangshuangnet】,但实际上我们希望它保持我们上一次输入的著作权归作者所有,禁止商业用途转载。【未经授权禁止转载】值,这也就是状态丢失了。怎么办呢?我们只原创内容,盗版必究。【版权所有,侵权必究】要确保 state 是在 a() 外面定【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net义即可解决这个问题。
本文作者:唐霜,转载请注明出处。【本文首发于唐霜的博客】在HMR的实际案例中,这种情况非常常见,转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。因为作为HMR的提供者,是无法确保状态被【本文受版权保护】原创内容,盗版必究。用在什么地方的。因此,我们很少在实际生产本文作者:唐霜,转载请注明出处。著作权归作者所有,禁止商业用途转载。环境使用HMR,更多是在开发环境中使用它【本文受版权保护】【作者:唐霜】。
【作者:唐霜】【作者:唐霜】超俗释然:esbuild、vite等新事物
【作者:唐霜】【版权所有】唐霜 www.tangshuang.net人世间事,或重如泰山,或若有若无。不以物本文作者:唐霜,转载请注明出处。【转载请注明来源】喜,为己所为,行万里路,秉初始心。
【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。
其他原生语言开发前端工具链
2020年开始,前端社区出现了用其他语言【转载请注明来源】原创内容,盗版必究。开发前端工具链工具的现象,到2021-2原创内容,盗版必究。原创内容,盗版必究。022这一现象骤然火爆,并引发了新一代前【原创内容,转载请注明出处】【关注微信公众号:wwwtangshuangnet】端工具链都是由其他语言,甚至更低层的ru【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。st等系统级语言来开发的讨论。在这些讨论原创内容,盗版必究。未经授权,禁止复制转载。之下,总有一种前端快失业的错觉。用其他原【版权所有】唐霜 www.tangshuang.net转载请注明出处:www.tangshuang.net生语言来编写前端工具链主要有两个点:1.【原创内容,转载请注明出处】【本文受版权保护】 现代前端开发非常依赖工具链,随着这些工【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net具越来越臃肿,作为工具,运行越来越慢,已【关注微信公众号:wwwtangshuangnet】原创内容,盗版必究。经无法适应前端开发的快节奏;2. 此前所【转载请注明来源】本文版权归作者所有,未经授权不得转载。有前端工具都是由js写成,部分通过nod【版权所有,侵权必究】未经授权,禁止复制转载。ejs调用c/c++模块,这导致了这些工原创内容,盗版必究。【版权所有】唐霜 www.tangshuang.net具慢,而使用其他更低层的语言来编写,可以【原创内容,转载请注明出处】【转载请注明来源】成百倍的提升其运行性能。
【原创不易,请尊重版权】【版权所有】唐霜 www.tangshuang.net其中,esbuild和SWC就是典型代表【作者:唐霜】本文作者:唐霜,转载请注明出处。。ESBuild是Figma前CTO E【未经授权禁止转载】转载请注明出处:www.tangshuang.netvan Wallace基于GO语言开发,【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。用于实现类似webpack一样的打包工具【转载请注明来源】转载请注明出处:www.tangshuang.net。由于GO语言原生支持高并发,因此,es【关注微信公众号:wwwtangshuangnet】【作者:唐霜】build中的任务可以被拆分并行,同时,本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net由于完全摒弃了JS社区,没有任何历史包袱【本文首发于唐霜的博客】【版权所有,侵权必究】,因此,其整体设计和架构都更加现代化,更【作者:唐霜】【作者:唐霜】不会出现webpack工具链中多个ast著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。串来串去的情况。SWC是由Rust语言实本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】现的类似babel的编译器,不过它的官方著作权归作者所有,禁止商业用途转载。未经授权,禁止复制转载。网站上并没有详细阐述其内部实现,只提到了原创内容,盗版必究。【本文受版权保护】比JS的单线程而言,它具有并发优势。
未经授权,禁止复制转载。本文版权归作者所有,未经授权不得转载。【访问 www.tangshuang.net 获取更多精彩内容】【版权所有】唐霜 www.tangshuang.net由此可见,通过其他语言来开发前端工具链,【关注微信公众号:wwwtangshuangnet】【原创不易,请尊重版权】最主要的一点,是绕开了JS单线程的缺点,【版权所有】唐霜 www.tangshuang.net本文作者:唐霜,转载请注明出处。同时原生语言更接近底层,不需要一个运行时【转载请注明来源】本文版权归作者所有,未经授权不得转载。,减少了额外的开销,因此性能上更优。但是转载请注明出处:www.tangshuang.net【本文首发于唐霜的博客】不可否认的一点是,这些其他语言写就的工具【原创内容,转载请注明出处】【转载请注明来源】,由于缺乏JS社区的支持,未来如何发展还【原创不易,请尊重版权】原创内容,盗版必究。很难讲,因为JS社区是非常活跃的,要让这著作权归作者所有,禁止商业用途转载。【版权所有,侵权必究】些前端开发者切换语言去为其他语言的工具贡未经授权,禁止复制转载。【本文受版权保护】献,可能并不是一件容易的事。
【版权所有,侵权必究】【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。原创内容,盗版必究。bundless
2021年,vue的作者尤雨溪在状态中称【版权所有】唐霜 www.tangshuang.net本文版权归作者所有,未经授权不得转载。vite将超越webpack,而在202【本文受版权保护】【原创不易,请尊重版权】2年它也确实做到了非常大的占有率,甚至它【版权所有】唐霜 www.tangshuang.net【原创不易,请尊重版权】的前辈snowpack都直接在自己的官网未经授权,禁止复制转载。【作者:唐霜】上推荐自己的用户去使用vite,要知道n【关注微信公众号:wwwtangshuangnet】【版权所有】唐霜 www.tangshuang.netowpack可以说是bundless的先【关注微信公众号:wwwtangshuangnet】转载请注明出处:www.tangshuang.net驱,vite就是受其启发而创建的。
【未经授权禁止转载】【本文首发于唐霜的博客】【转载请注明来源】转载请注明出处:www.tangshuang.net所谓bundless,简单讲,就是我们尽转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】量不要去做类似webpack一样的打包,本文作者:唐霜,转载请注明出处。【未经授权禁止转载】让我们的代码直接运行起来。没有了打包这个【作者:唐霜】【版权所有,侵权必究】过程,其速度自然就快了很多。vite作为著作权归作者所有,禁止商业用途转载。【版权所有】唐霜 www.tangshuang.net今年最热门的工具项目,它有自己的一些优势【版权所有】唐霜 www.tangshuang.net未经授权,禁止复制转载。。vite是如何做到比webpack快的【原创不易,请尊重版权】未经授权,禁止复制转载。呢?对于webpack-dev-serv转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】er而言,要在本地启动一个服务作为开发的【原创内容,转载请注明出处】【本文受版权保护】预览服务,它必须进行一次webpack的转载请注明出处:www.tangshuang.net【原创不易,请尊重版权】打包过程,我们前文已经讲过,webpac【原创不易,请尊重版权】【本文首发于唐霜的博客】k其实是很慢的,虽然webpack-de【本文首发于唐霜的博客】原创内容,盗版必究。v-server采用了内存文件系统,但是【转载请注明来源】著作权归作者所有,禁止商业用途转载。架不住其计算过程控制流太长太不可控,所以【本文首发于唐霜的博客】【本文首发于唐霜的博客】仍然会比较慢,开发者修改完代码之后,无法【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net尽快看到修改后的效果。而vite则在本地【转载请注明来源】【原创不易,请尊重版权】服务中不执行打包过程,它基于ES原生的M著作权归作者所有,禁止商业用途转载。著作权归作者所有,禁止商业用途转载。odule系统,也就是import fr【作者:唐霜】【原创内容,转载请注明出处】om语法在浏览器中的原生支持,让浏览器自【原创不易,请尊重版权】转载请注明出处:www.tangshuang.net己去请求一个依赖,而请求的依赖实际上是向转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】vite本地服务的一个url地址发起请求本文作者:唐霜,转载请注明出处。【原创内容,转载请注明出处】,vite本地服务在接收到这个请求之后,本文作者:唐霜,转载请注明出处。转载请注明出处:www.tangshuang.net立马对该请求所对应的文件进行编译和输出,【访问 www.tangshuang.net 获取更多精彩内容】未经授权,禁止复制转载。这个效率和我们经常提到的SSR差不多,这【版权所有】唐霜 www.tangshuang.net原创内容,盗版必究。也就让vite在第一次打开时比webpa【原创内容,转载请注明出处】【原创内容,转载请注明出处】ck快了n倍,因为对于vite而言,第一【本文受版权保护】本文作者:唐霜,转载请注明出处。次打开时,要做的事情非常少,只需要起一个【访问 www.tangshuang.net 获取更多精彩内容】著作权归作者所有,禁止商业用途转载。服务,把被访问的脚本编译完吐出就可以了,原创内容,盗版必究。【本文受版权保护】在页面发生变化的时候,新的请求过来,才会【版权所有】唐霜 www.tangshuang.net【版权所有,侵权必究】执行新的编译。
【原创不易,请尊重版权】原创内容,盗版必究。本文版权归作者所有,未经授权不得转载。本文版权归作者所有,未经授权不得转载。虽然vite在开发时效率极高,但是并不代【关注微信公众号:wwwtangshuangnet】【访问 www.tangshuang.net 获取更多精彩内容】表它就是前端工具的终极形态,bundle本文作者:唐霜,转载请注明出处。本文作者:唐霜,转载请注明出处。ss在浏览器原生支持import的今天,转载请注明出处:www.tangshuang.net【本文受版权保护】其实是非常尴尬的,我们很难预判在不久的将著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。来,我们还需要bundless,我们可能【本文首发于唐霜的博客】【本文受版权保护】只需要浏览器就可以了。
【本文首发于唐霜的博客】未经授权,禁止复制转载。结语
行文至此,我已经把自己在前端开发领域所积转载请注明出处:www.tangshuang.net【版权所有,侵权必究】累的大部分有关性能的知识都讲了一遍,有些转载请注明出处:www.tangshuang.net【访问 www.tangshuang.net 获取更多精彩内容】部分细,有的部分点到为止,有些内容没有讲【原创不易,请尊重版权】著作权归作者所有,禁止商业用途转载。(如使用nodejs进行后端开发时遇到的【未经授权禁止转载】著作权归作者所有,禁止商业用途转载。性能问题),不过对于完整阅读完本册的朋友著作权归作者所有,禁止商业用途转载。【原创不易,请尊重版权】而言,我想你应该能隐约感受到,万变不离其【本文受版权保护】未经授权,禁止复制转载。宗,前端的性能问题主要是加载、渲染、内存转载请注明出处:www.tangshuang.net【原创内容,转载请注明出处】占用、算法(本质是内存和CPU占用)、架本文作者:唐霜,转载请注明出处。【关注微信公众号:wwwtangshuangnet】构设计等方面的知识,慢慢理顺之后,无非如【访问 www.tangshuang.net 获取更多精彩内容】【版权所有,侵权必究】此。虽然本册提供了非常多的优化建议,但是转载请注明出处:www.tangshuang.net【版权所有】唐霜 www.tangshuang.net它们都不是一尘不变的,有的会随着浏览器、转载请注明出处:www.tangshuang.net未经授权,禁止复制转载。运行环境的发展逐渐没用,有的则需要在日常【版权所有】唐霜 www.tangshuang.net著作权归作者所有,禁止商业用途转载。开发中根据自己的情况进行策略调整。我仍然【转载请注明来源】转载请注明出处:www.tangshuang.net认为,虽然前端性能问题涉及的内容很多,但未经授权,禁止复制转载。原创内容,盗版必究。是,在真正的工作中被用到的其实不多,因为【关注微信公众号:wwwtangshuangnet】著作权归作者所有,禁止商业用途转载。我们在完成业务时,往往需要先实现业务本身【本文受版权保护】【访问 www.tangshuang.net 获取更多精彩内容】的目标,然后再来考虑性能,甚至大部分情况著作权归作者所有,禁止商业用途转载。本文版权归作者所有,未经授权不得转载。下,根本不会考虑性能,直到用户使用过程中【访问 www.tangshuang.net 获取更多精彩内容】【未经授权禁止转载】出现了卡顿时,才会回头去关注,而性能问题【关注微信公众号:wwwtangshuangnet】本文作者:唐霜,转载请注明出处。又没有安全问题那么致命,即使我们应该为了【本文受版权保护】转载请注明出处:www.tangshuang.net性能进行重构,但在大部分情况下,我们也只【访问 www.tangshuang.net 获取更多精彩内容】转载请注明出处:www.tangshuang.net会通过补丁的形式优化局部的性能问题。基于本文作者:唐霜,转载请注明出处。本文版权归作者所有,未经授权不得转载。这样的现实,我还是希望读者朋友能够养成良【本文受版权保护】【转载请注明来源】好的习惯,能够在写代码时时刻记住性能问题【访问 www.tangshuang.net 获取更多精彩内容】原创内容,盗版必究。,有些高性能的代码就是随手写的,但是如果【作者:唐霜】【原创内容,转载请注明出处】你此刻忽视了,等回头再来优化时,就不得不未经授权,禁止复制转载。【本文受版权保护】费非常大的力气。我比较推荐阅读《高性能J【版权所有,侵权必究】转载请注明出处:www.tangshuang.netavascript》一书,原因是它非常薄本文作者:唐霜,转载请注明出处。【版权所有,侵权必究】,利用闲暇时间很快就能读完,通过不断实践本文作者:唐霜,转载请注明出处。【版权所有】唐霜 www.tangshuang.net,就能养成比较不错的性能优先的写码习惯。【转载请注明来源】【作者:唐霜】当然,这本书已经比较老了,有些东西不适用【本文受版权保护】【关注微信公众号:wwwtangshuangnet】,但是就像我前面所讲的,万变不离其宗,只【本文首发于唐霜的博客】【作者:唐霜】要我们经常且善于思考如何提升性能,就会在原创内容,盗版必究。未经授权,禁止复制转载。工作中不断积累出自己的性能优化知识体系。原创内容,盗版必究。【作者:唐霜】最后,如果你在阅读过程中发现了什么纰漏,【原创不易,请尊重版权】本文作者:唐霜,转载请注明出处。请立即反馈给我,你可以通过扫描下方二维码原创内容,盗版必究。【关注微信公众号:wwwtangshuangnet】通过微信和我沟通,就像本册中武侠主人公荫【作者:唐霜】本文版权归作者所有,未经授权不得转载。世一般,让我们一起成长。<完>未经授权,禁止复制转载。【原创内容,转载请注明出处】;
【原创不易,请尊重版权】【作者:唐霜】著作权归作者所有,禁止商业用途转载。如果你觉得本书对你有帮助,通过下方的二维码向我打赏吧,帮助我写出更多有用的内容。

2022-08-18